 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePittsburgh Learning Classifier Systems for Explainable Reinforcement Learning: Comparing with XCS
May 17, 2023



Interest in reinforcement learning (RL) has recently surged due to the application of deep learning techniques, but these connectionist approaches are opaque compared with symbolic systems. Learning Classifier Systems (LCSs) are evolutionary machine learning systems that can be categorised as eXplainable AI (XAI) due to their rule-based nature. Michigan LCSs are commonly used in RL domains as the alternative Pittsburgh systems (e.g. SAMUEL) suffer from complex algorithmic design and high computational requirements; however they can produce more compact/interpretable solutions than Michigan systems. We aim to develop two novel Pittsburgh LCSs to address RL domains: PPL-DL and PPL-ST. The former acts as a "zeroth-level" system, and the latter revisits SAMUEL's core Monte Carlo learning mechanism for estimating rule strength. We compare our two Pittsburgh systems to the Michigan system XCS across deterministic and stochastic FrozenLake environments. Results show that PPL-ST performs on-par or better than PPL-DL and outperforms XCS in the presence of high levels of environmental uncertainty. Rulesets evolved by PPL-ST can achieve higher performance than those evolved by XCS, but in a more parsimonious and therefore more interpretable fashion, albeit with higher computational cost. This indicates that PPL-ST is an LCS well-suited to producing explainable policies in RL domains.
A Genetic Fuzzy System for Interpretable and Parsimonious Reinforcement Learning Policies
May 17, 2023



Reinforcement learning (RL) is experiencing a resurgence in research interest, where Learning Classifier Systems (LCSs) have been applied for many years. However, traditional Michigan approaches tend to evolve large rule bases that are difficult to interpret or scale to domains beyond standard mazes. A Pittsburgh Genetic Fuzzy System (dubbed Fuzzy MoCoCo) is proposed that utilises both multiobjective and cooperative coevolutionary mechanisms to evolve fuzzy rule-based policies for RL environments. Multiobjectivity in the system is concerned with policy performance vs. complexity. The continuous state RL environment Mountain Car is used as a testing bed for the proposed system. Results show the system is able to effectively explore the trade-off between policy performance and complexity, and learn interpretable, high-performing policies that use as few rules as possible.
Optimality-based Analysis of XCSF Compaction in Discrete Reinforcement Learning
Sep 03, 2020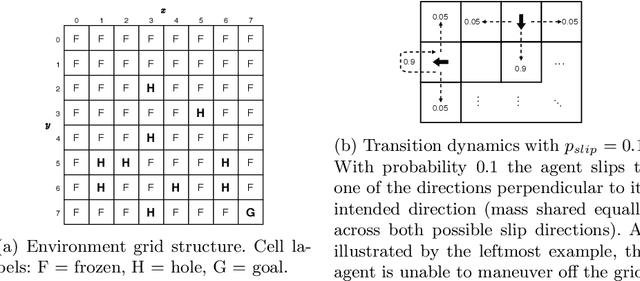
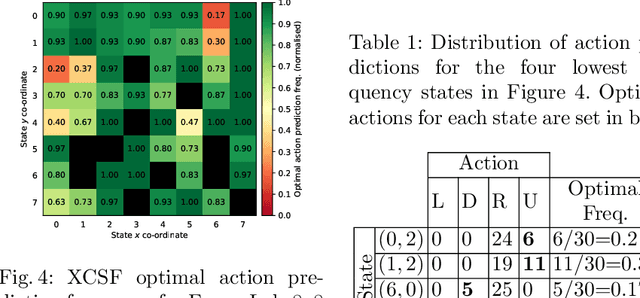
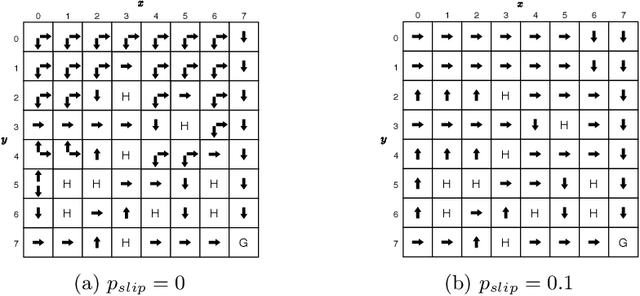
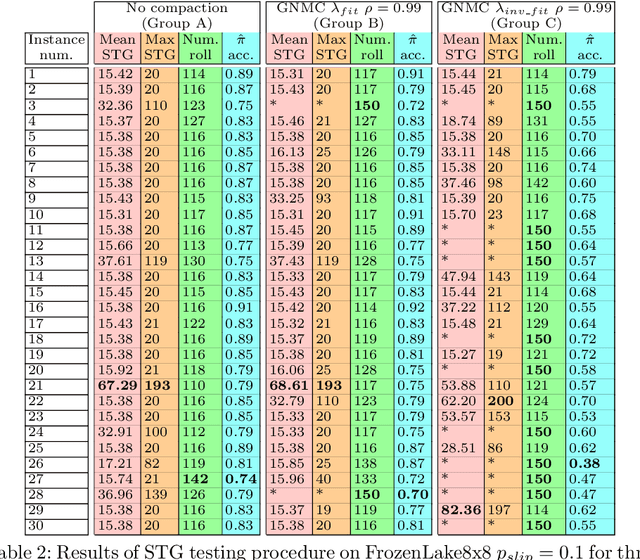
Learning classifier systems (LCSs) are population-based predictive systems that were originally envisioned as agents to act in reinforcement learning (RL) environments. These systems can suffer from population bloat and so are amenable to compaction techniques that try to strike a balance between population size and performance. A well-studied LCS architecture is XCSF, which in the RL setting acts as a Q-function approximator. We apply XCSF to a deterministic and stochastic variant of the FrozenLake8x8 environment from OpenAI Gym, with its performance compared in terms of function approximation error and policy accuracy to the optimal Q-functions and policies produced by solving the environments via dynamic programming. We then introduce a novel compaction algorithm (Greedy Niche Mass Compaction - GNMC) and study its operation on XCSF's trained populations. Results show that given a suitable parametrisation, GNMC preserves or even slightly improves function approximation error while yielding a significant reduction in population size. Reasonable preservation of policy accuracy also occurs, and we link this metric to the commonly used steps-to-goal metric in maze-like environments, illustrating how the metrics are complementary rather than competitive.