 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic Feedback for Closed-Loop Force Control in Robotic Grinding
Feb 24, 2026Acoustic feedback is a critical indicator for assessing the contact condition between the tool and the workpiece when humans perform grinding tasks with rotary tools. In contrast, robotic grinding systems typically rely on force sensing, with acoustic information largely ignored. This reliance on force sensors is costly and difficult to adapt to different grinding tools, whereas audio sensors (microphones) are low-cost and can be mounted on any medium that conducts grinding sound. This paper introduces a low-cost Acoustic Feedback Robotic Grinding System (AFRG) that captures audio signals with a contact microphone, estimates grinding force from the audio in real time, and enables closed-loop force control of the grinding process. Compared with conventional force-sensing approaches, AFRG achieves a 4-fold improvement in consistency across different grinding disc conditions. AFRG relies solely on a low-cost microphone, which is approximately 200-fold cheaper than conventional force sensors, as the sensing modality, providing an easily deployable, cost-effective robotic grinding solution.
Open-Vocabulary Part-Based Grasping
Jun 10, 2024
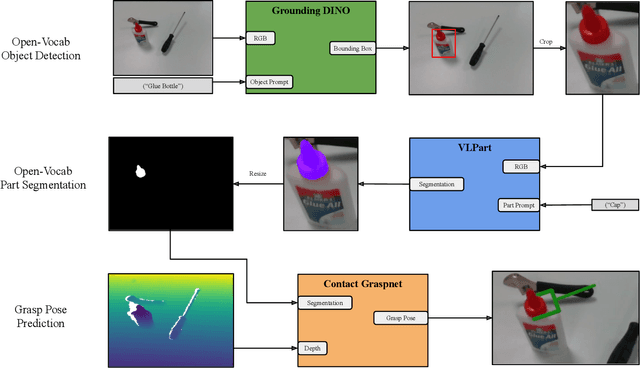

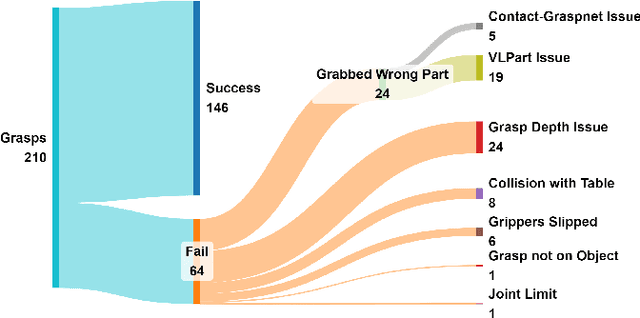
Many robotic applications require to grasp objects not arbitrarily but at a very specific object part. This is especially important for manipulation tasks beyond simple pick-and-place scenarios or in robot-human interactions, such as object handovers. We propose AnyPart, a practical system that combines open-vocabulary object detection, open-vocabulary part segmentation and 6DOF grasp pose prediction to infer a grasp pose on a specific part of an object in 800 milliseconds. We contribute two new datasets for the task of open-vocabulary part-based grasping, a hand-segmented dataset containing 1014 object-part segmentations, and a dataset of real-world scenarios gathered during our robot trials for individual objects and table-clearing tasks. We evaluate AnyPart on a mobile manipulator robot using a set of 28 common household objects over 360 grasping trials. AnyPart is capable of producing successful grasps 69.52 %, when ignoring robot-based grasp failures, AnyPart predicts a grasp location on the correct part 88.57 % of the time.
Pittsburgh Learning Classifier Systems for Explainable Reinforcement Learning: Comparing with XCS
May 17, 2023



Interest in reinforcement learning (RL) has recently surged due to the application of deep learning techniques, but these connectionist approaches are opaque compared with symbolic systems. Learning Classifier Systems (LCSs) are evolutionary machine learning systems that can be categorised as eXplainable AI (XAI) due to their rule-based nature. Michigan LCSs are commonly used in RL domains as the alternative Pittsburgh systems (e.g. SAMUEL) suffer from complex algorithmic design and high computational requirements; however they can produce more compact/interpretable solutions than Michigan systems. We aim to develop two novel Pittsburgh LCSs to address RL domains: PPL-DL and PPL-ST. The former acts as a "zeroth-level" system, and the latter revisits SAMUEL's core Monte Carlo learning mechanism for estimating rule strength. We compare our two Pittsburgh systems to the Michigan system XCS across deterministic and stochastic FrozenLake environments. Results show that PPL-ST performs on-par or better than PPL-DL and outperforms XCS in the presence of high levels of environmental uncertainty. Rulesets evolved by PPL-ST can achieve higher performance than those evolved by XCS, but in a more parsimonious and therefore more interpretable fashion, albeit with higher computational cost. This indicates that PPL-ST is an LCS well-suited to producing explainable policies in RL domains.
A Genetic Fuzzy System for Interpretable and Parsimonious Reinforcement Learning Policies
May 17, 2023



Reinforcement learning (RL) is experiencing a resurgence in research interest, where Learning Classifier Systems (LCSs) have been applied for many years. However, traditional Michigan approaches tend to evolve large rule bases that are difficult to interpret or scale to domains beyond standard mazes. A Pittsburgh Genetic Fuzzy System (dubbed Fuzzy MoCoCo) is proposed that utilises both multiobjective and cooperative coevolutionary mechanisms to evolve fuzzy rule-based policies for RL environments. Multiobjectivity in the system is concerned with policy performance vs. complexity. The continuous state RL environment Mountain Car is used as a testing bed for the proposed system. Results show the system is able to effectively explore the trade-off between policy performance and complexity, and learn interpretable, high-performing policies that use as few rules as possible.
Lateralization in Agents' Decision Making: Evidence of Benefits/Costs from Artificial Intelligence
Feb 03, 2023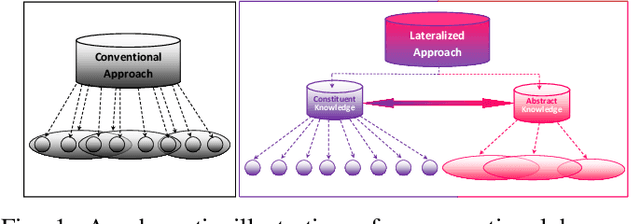
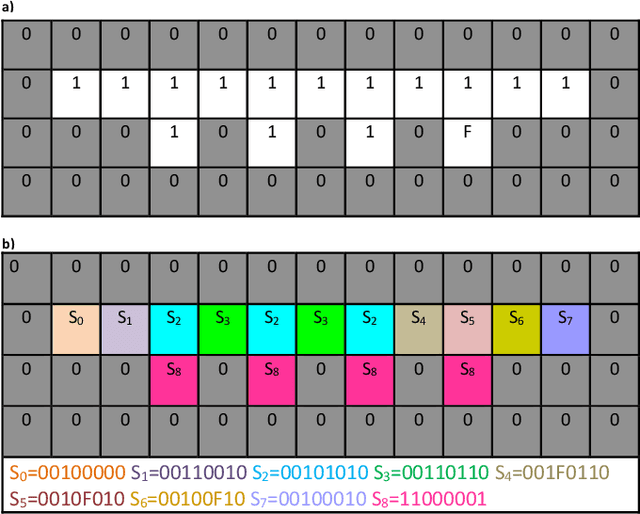
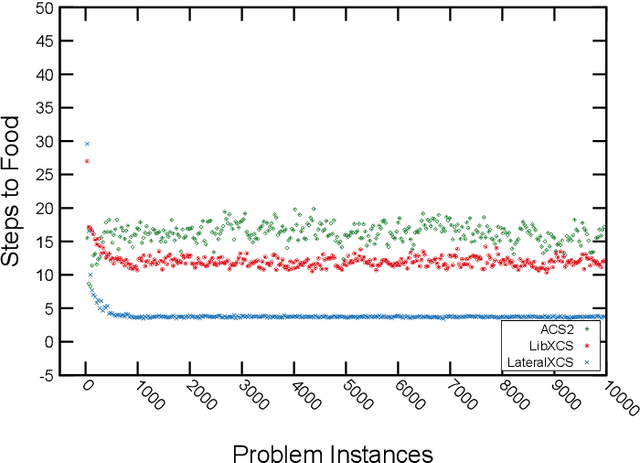
Lateralization is ubiquitous in vertebrate brains which, as well as its role in locomotion, is considered an important factor in biological intelligence. Lateralization has been associated with both poor and good performance. It has been hypothesized that lateralization has benefits that may counterbalance its costs. Given that lateralization is ubiquitous, it likely has advantages that can benefit artificial intelligence. In turn, lateralized artificial intelligent systems can be used as tools to advance the understanding of lateralization in biological intelligence. Recently lateralization has been incorporated into artificially intelligent systems to solve complex problems in computer vision and navigation domains. Here we describe and test two novel lateralized artificial intelligent systems that simultaneously represent and address given problems at constituent and holistic levels. The experimental results demonstrate that the lateralized systems outperformed state-of-the-art non-lateralized systems in resolving complex problems. The advantages arise from the abilities, (i) to represent an input signal at both the constituent level and holistic level simultaneously, such that the most appropriate viewpoint controls the system; (ii) to avoid extraneous computations by generating excite and inhibit signals. The computational costs associated with the lateralized AI systems are either less than the conventional AI systems or countered by providing better solutions.
Lateralized Learning for Multi-Class Visual Classification Tasks
Jan 30, 2023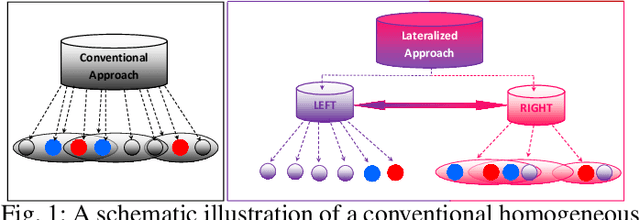
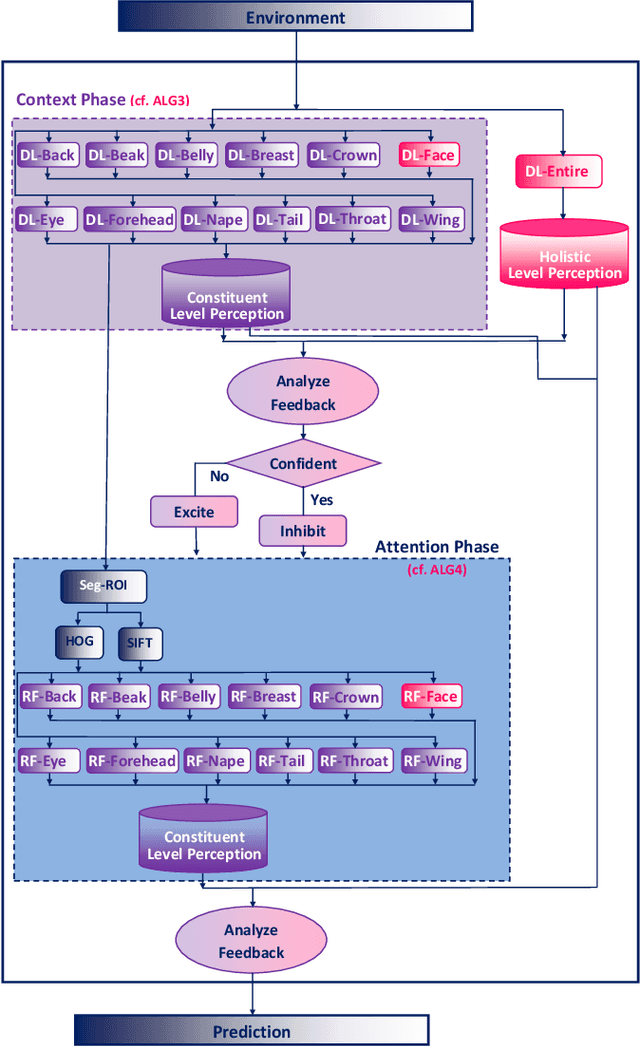

The majority of computer vision algorithms fail to find higher-order (abstract) patterns in an image so are not robust against adversarial attacks, unlike human lateralized vision. Deep learning considers each input pixel in a homogeneous manner such that different parts of a ``locality-sensitive hashing table'' are often not connected, meaning higher-order patterns are not discovered. Hence these systems are not robust against noisy, irrelevant, and redundant data, resulting in the wrong prediction being made with high confidence. Conversely, vertebrate brains afford heterogeneous knowledge representation through lateralization, enabling modular learning at different levels of abstraction. This work aims to verify the effectiveness, scalability, and robustness of a lateralized approach to real-world problems that contain noisy, irrelevant, and redundant data. The experimental results of multi-class (200 classes) image classification show that the novel system effectively learns knowledge representation at multiple levels of abstraction making it more robust than other state-of-the-art techniques. Crucially, the novel lateralized system outperformed all the state-of-the-art deep learning-based systems for the classification of normal and adversarial images by 19.05% - 41.02% and 1.36% - 49.22%, respectively. Findings demonstrate the value of heterogeneous and lateralized learning for computer vision applications.
A Layered Learning Approach to Scaling in Learning Classifier Systems for Boolean Problems
Jun 02, 2020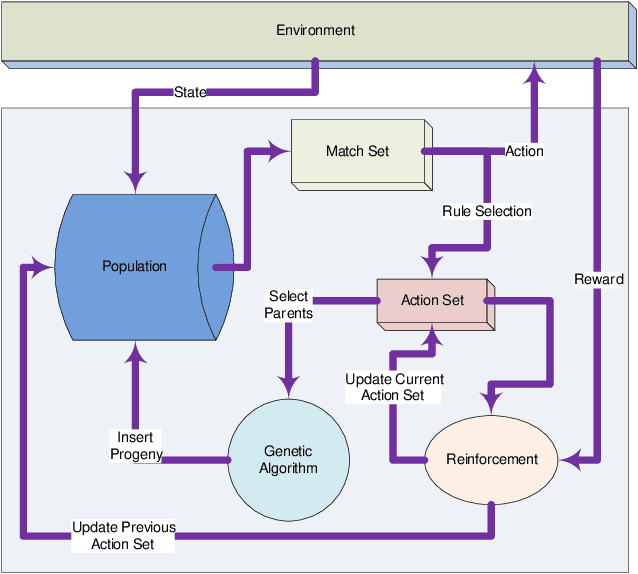
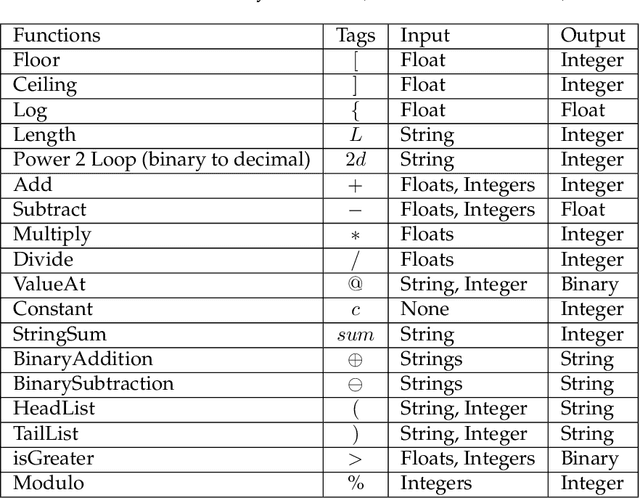
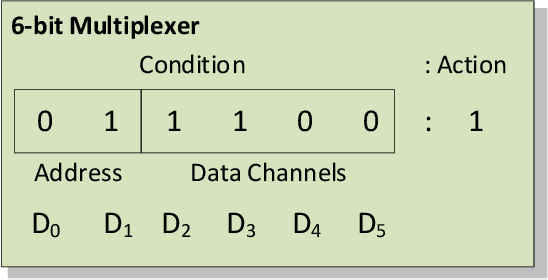
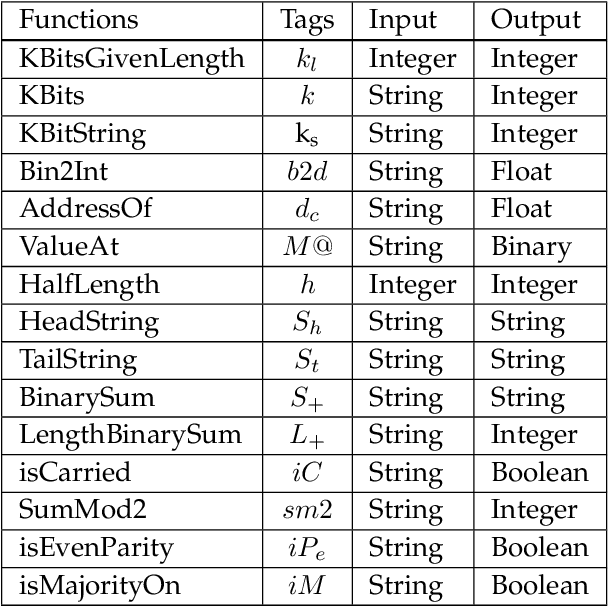
Learning classifier systems (LCSs) originated from cognitive-science research but migrated such that LCS became powerful classification techniques. Modern LCSs can be used to extract building blocks of knowledge to solve more difficult problems in the same or a related domain. Recent works on LCSs showed that the knowledge reuse through the adoption of Code Fragments, GP-like tree-based programs, into LCSs could provide advances in scaling. However, since solving hard problems often requires constructing high-level building blocks, which also results in an intractable search space, a limit of scaling will eventually be reached. Inspired by human problem-solving abilities, XCSCF* can reuse learned knowledge and learned functionality to scale to complex problems by transferring them from simpler problems using layered learning. However, this method was unrefined and suited to only the Multiplexer problem domain. In this paper, we propose improvements to XCSCF* to enable it to be robust across multiple problem domains. This is demonstrated on the benchmarks Multiplexer, Carry-one, Majority-on, and Even-parity domains. The required base axioms necessary for learning are proposed, methods for transfer learning in LCSs developed and learning recast as a decomposition into a series of subordinate problems. Results show that from a conventional tabula rasa, with only a vague notion of what subordinate problems might be relevant, it is possible to capture the general logic behind the tested domains, so the advanced system is capable of solving any individual n-bit Multiplexer, n-bit Carry-one, n-bit Majority-on, or n-bit Even-parity problem.
Relatedness Measures to Aid the Transfer of Building Blocks among Multiple Tasks
May 17, 2020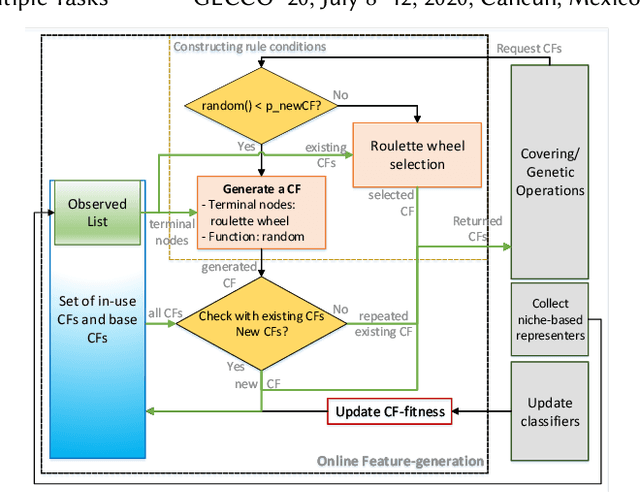

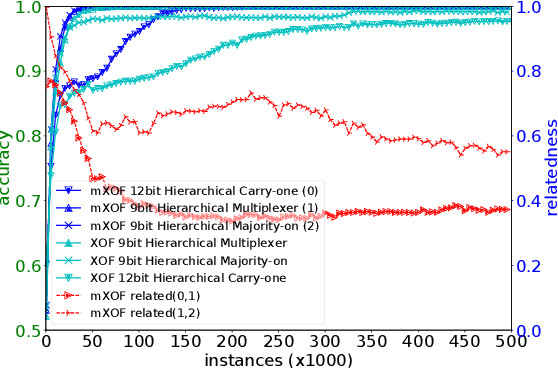
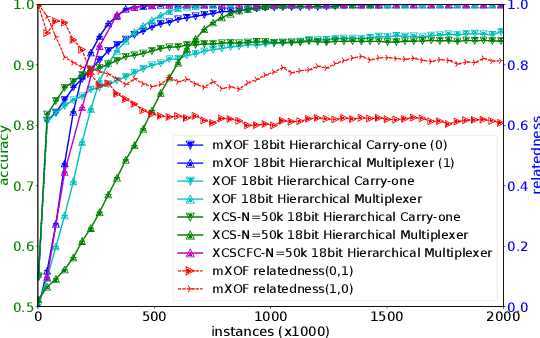
Multitask Learning is a learning paradigm that deals with multiple different tasks in parallel and transfers knowledge among them. XOF, a Learning Classifier System using tree-based programs to encode building blocks (meta-features), constructs and collects features with rich discriminative information for classification tasks in an observed list. This paper seeks to facilitate the automation of feature transferring in between tasks by utilising the observed list. We hypothesise that the best discriminative features of a classification task carry its characteristics. Therefore, the relatedness between any two tasks can be estimated by comparing their most appropriate patterns. We propose a multiple-XOF system, called mXOF, that can dynamically adapt feature transfer among XOFs. This system utilises the observed list to estimate the task relatedness. This method enables the automation of transferring features. In terms of knowledge discovery, the resemblance estimation provides insightful relations among multiple data. We experimented mXOF on various scenarios, e.g. representative Hierarchical Boolean problems, classification of distinct classes in the UCI Zoo dataset, and unrelated tasks, to validate its abilities of automatic knowledge-transfer and estimating task relatedness. Results show that mXOF can estimate the relatedness reasonably between multiple tasks to aid the learning performance with the dynamic feature transferring.
Constructing Complexity-efficient Features in XCS with Tree-based Rule Conditions
Apr 23, 2020

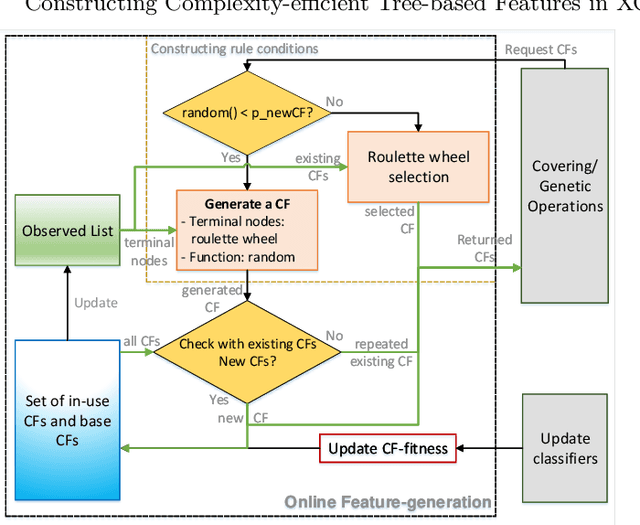
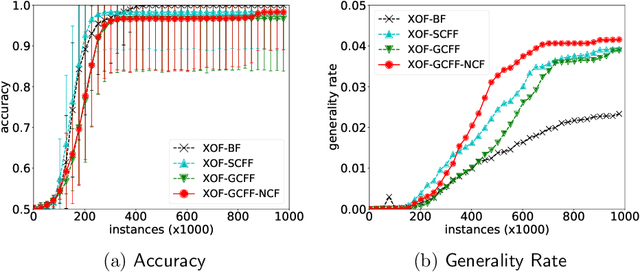
A major goal of machine learning is to create techniques that abstract away irrelevant information. The generalisation property of standard Learning Classifier System (LCS) removes such information at the feature level but not at the feature interaction level. Code Fragments (CFs), a form of tree-based programs, introduced feature manipulation to discover important interactions, but they often contain irrelevant information, which causes structural inefficiency. XOF is a recently introduced LCS that uses CFs to encode building blocks of knowledge about feature interaction. This paper aims to optimise the structural efficiency of CFs in XOF. We propose two measures to improve constructing CFs to achieve this goal. Firstly, a new CF-fitness update estimates the applicability of CFs that also considers the structural complexity. The second measure we can use is a niche-based method of generating CFs. These approaches were tested on Even-parity and Hierarchical problems, which require highly complex combinations of input features to capture the data patterns. The results show that the proposed methods significantly increase the structural efficiency of CFs, which is estimated by the rule "generality rate". This results in faster learning performance in the Hierarchical Majority-on problem. Furthermore, a user-set depth limit for CF generation is not needed as the learning agent will not adopt higher-level CFs once optimal CFs are constructed.