 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReMoSPLAT: Reactive Mobile Manipulation Control on a Gaussian Splat
Dec 10, 2025
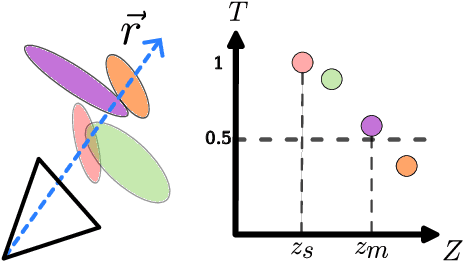

Reactive control can gracefully coordinate the motion of the base and the arm of a mobile manipulator. However, incorporating an accurate representation of the environment to avoid obstacles without involving costly planning remains a challenge. In this work, we present ReMoSPLAT, a reactive controller based on a quadratic program formulation for mobile manipulation that leverages a Gaussian Splat representation for collision avoidance. By integrating additional constraints and costs into the optimisation formulation, a mobile manipulator platform can reach its intended end effector pose while avoiding obstacles, even in cluttered scenes. We investigate the trade-offs of two methods for efficiently calculating robot-obstacle distances, comparing a purely geometric approach with a rasterisation-based approach. Our experiments in simulation on both synthetic and real-world scans demonstrate the feasibility of our method, showing that the proposed approach achieves performance comparable to controllers that rely on perfect ground-truth information.
RMMI: Enhanced Obstacle Avoidance for Reactive Mobile Manipulation using an Implicit Neural Map
Aug 29, 2024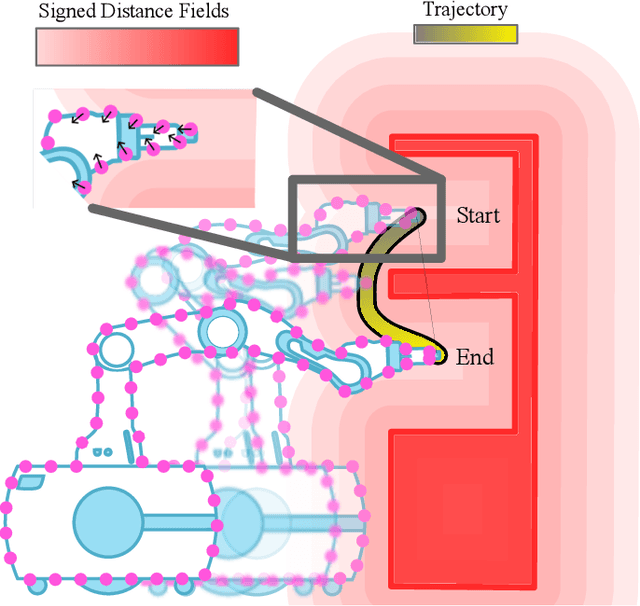
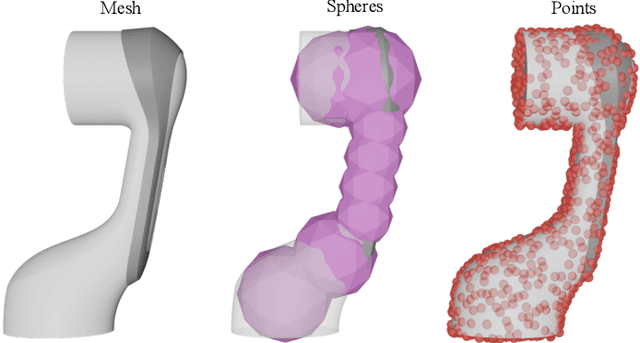
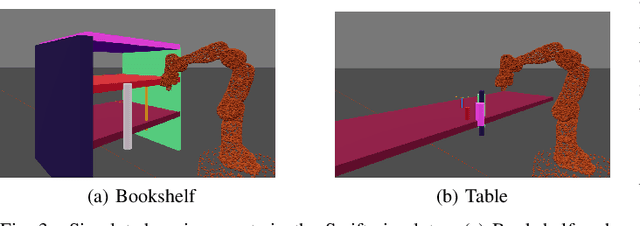
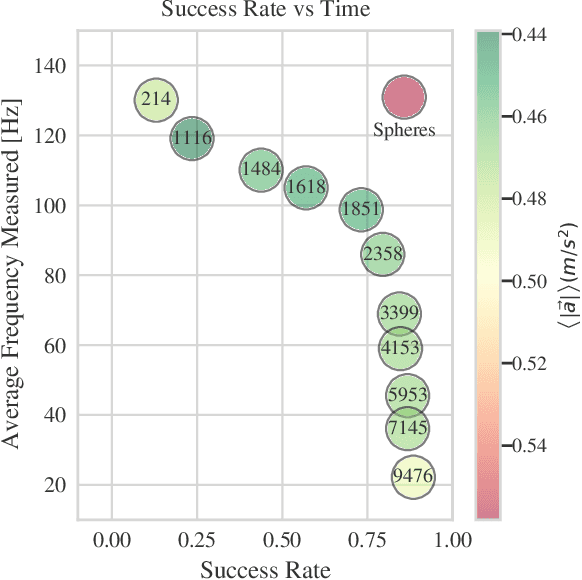
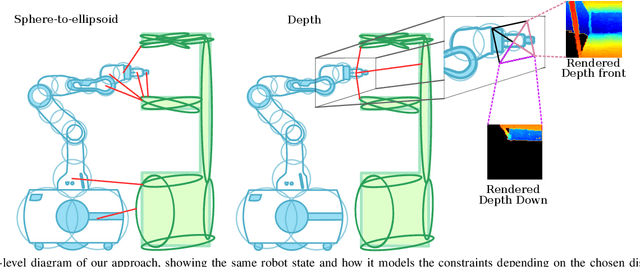
We introduce RMMI, a novel reactive control framework for mobile manipulators operating in complex, static environments. Our approach leverages a neural Signed Distance Field (SDF) to model intricate environment details and incorporates this representation as inequality constraints within a Quadratic Program (QP) to coordinate robot joint and base motion. A key contribution is the introduction of an active collision avoidance cost term that maximises the total robot distance to obstacles during the motion. We first evaluate our approach in a simulated reaching task, outperforming previous methods that rely on representing both the robot and the scene as a set of primitive geometries. Compared with the baseline, we improved the task success rate by 25% in total, which includes increases of 10% by using the active collision cost. We also demonstrate our approach on a real-world platform, showing its effectiveness in reaching target poses in cluttered and confined spaces using environment models built directly from sensor data. For additional details and experiment videos, visit https://rmmi.github.io/.
Open-Vocabulary Part-Based Grasping
Jun 10, 2024
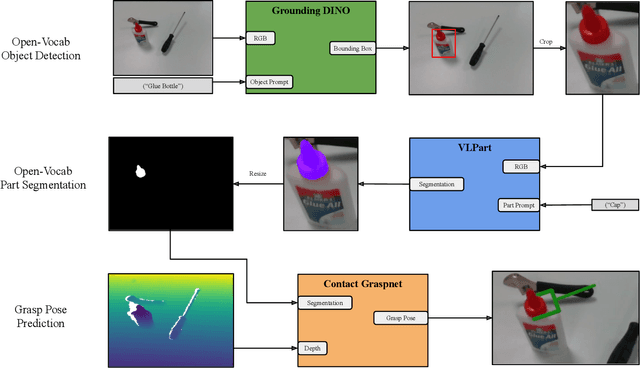

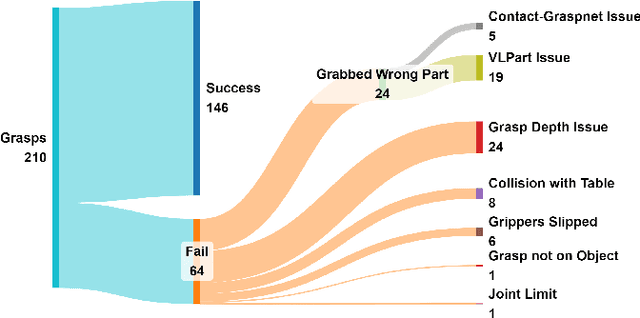
Many robotic applications require to grasp objects not arbitrarily but at a very specific object part. This is especially important for manipulation tasks beyond simple pick-and-place scenarios or in robot-human interactions, such as object handovers. We propose AnyPart, a practical system that combines open-vocabulary object detection, open-vocabulary part segmentation and 6DOF grasp pose prediction to infer a grasp pose on a specific part of an object in 800 milliseconds. We contribute two new datasets for the task of open-vocabulary part-based grasping, a hand-segmented dataset containing 1014 object-part segmentations, and a dataset of real-world scenarios gathered during our robot trials for individual objects and table-clearing tasks. We evaluate AnyPart on a mobile manipulator robot using a set of 28 common household objects over 360 grasping trials. AnyPart is capable of producing successful grasps 69.52 %, when ignoring robot-based grasp failures, AnyPart predicts a grasp location on the correct part 88.57 % of the time.