 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Object Detection Accuracy in Autonomous Vehicles Using Synthetic Data
Nov 23, 2024


The rapid progress in machine learning models has significantly boosted the potential for real-world applications such as autonomous vehicles, disease diagnoses, and recognition of emergencies. The performance of many machine learning models depends on the nature and size of the training data sets. These models often face challenges due to the scarcity, noise, and imbalance in real-world data, limiting their performance. Nonetheless, high-quality, diverse, relevant and representative training data is essential to build accurate and reliable machine learning models that adapt well to real-world scenarios. It is hypothesised that well-designed synthetic data can improve the performance of a machine learning algorithm. This work aims to create a synthetic dataset and evaluate its effectiveness to improve the prediction accuracy of object detection systems. This work considers autonomous vehicle scenarios as an illustrative example to show the efficacy of synthetic data. The effectiveness of these synthetic datasets in improving the performance of state-of-the-art object detection models is explored. The findings demonstrate that incorporating synthetic data improves model performance across all performance matrices. Two deep learning systems, System-1 (trained on real-world data) and System-2 (trained on a combination of real and synthetic data), are evaluated using the state-of-the-art YOLO model across multiple metrics, including accuracy, precision, recall, and mean average precision. Experimental results revealed that System-2 outperformed System-1, showing a 3% improvement in accuracy, along with superior performance in all other metrics.
Lateralization in Agents' Decision Making: Evidence of Benefits/Costs from Artificial Intelligence
Feb 03, 2023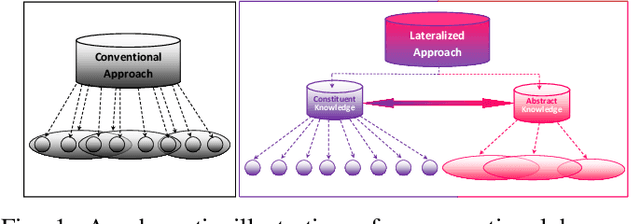
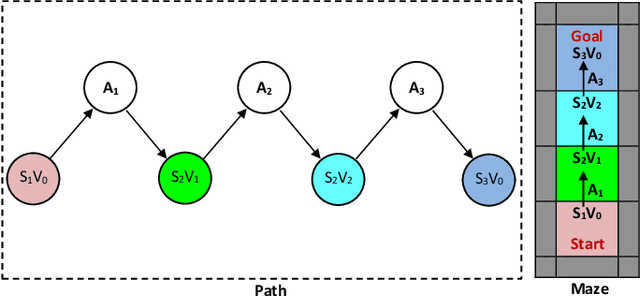
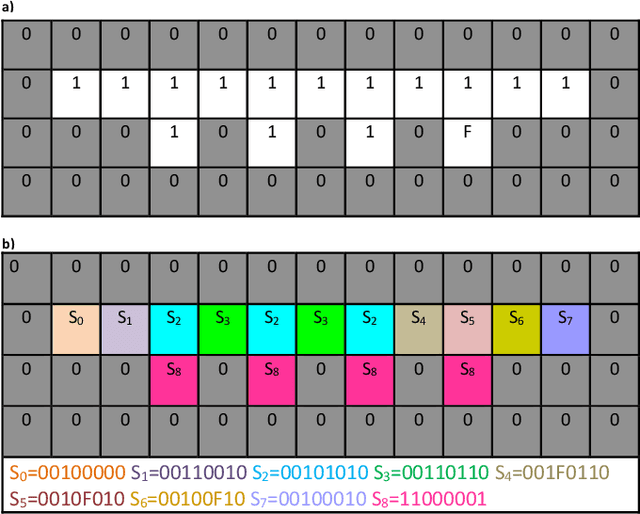
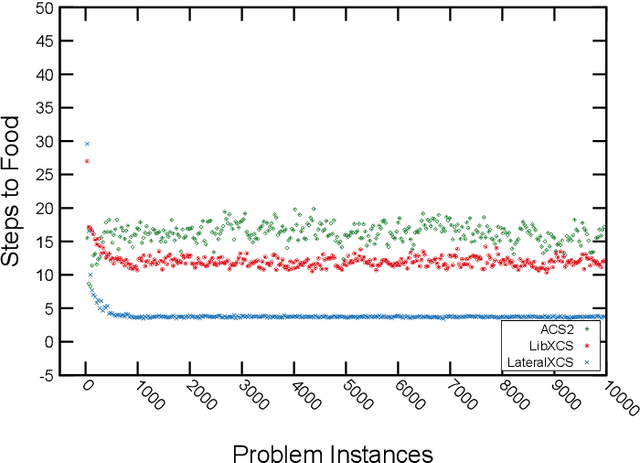
Lateralization is ubiquitous in vertebrate brains which, as well as its role in locomotion, is considered an important factor in biological intelligence. Lateralization has been associated with both poor and good performance. It has been hypothesized that lateralization has benefits that may counterbalance its costs. Given that lateralization is ubiquitous, it likely has advantages that can benefit artificial intelligence. In turn, lateralized artificial intelligent systems can be used as tools to advance the understanding of lateralization in biological intelligence. Recently lateralization has been incorporated into artificially intelligent systems to solve complex problems in computer vision and navigation domains. Here we describe and test two novel lateralized artificial intelligent systems that simultaneously represent and address given problems at constituent and holistic levels. The experimental results demonstrate that the lateralized systems outperformed state-of-the-art non-lateralized systems in resolving complex problems. The advantages arise from the abilities, (i) to represent an input signal at both the constituent level and holistic level simultaneously, such that the most appropriate viewpoint controls the system; (ii) to avoid extraneous computations by generating excite and inhibit signals. The computational costs associated with the lateralized AI systems are either less than the conventional AI systems or countered by providing better solutions.
Lateralized Learning for Multi-Class Visual Classification Tasks
Jan 30, 2023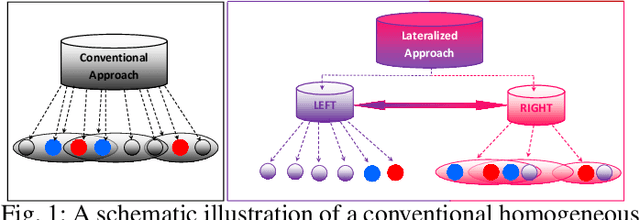
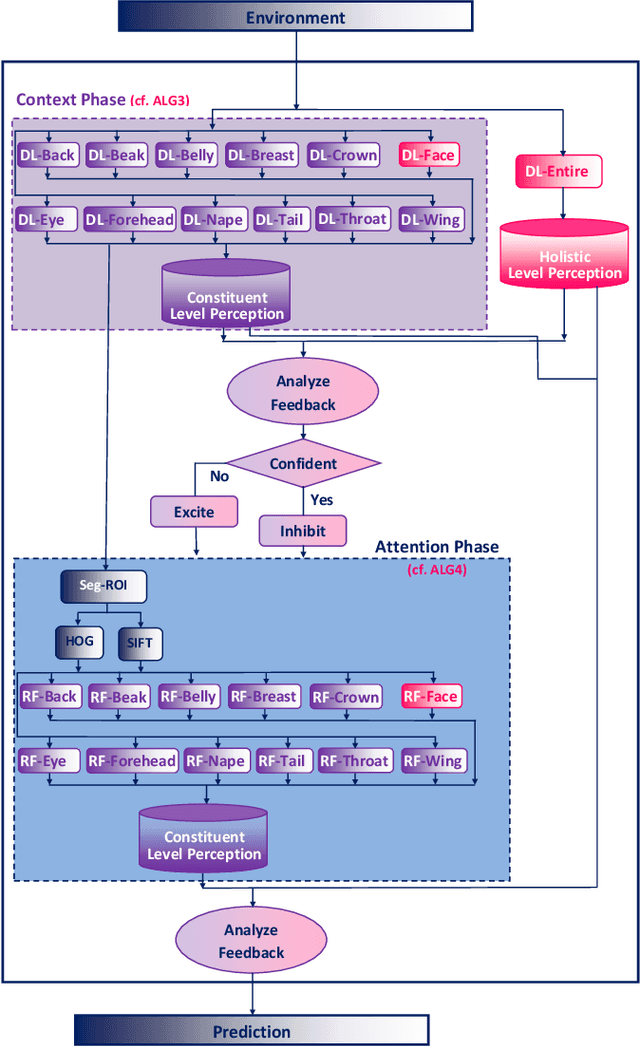
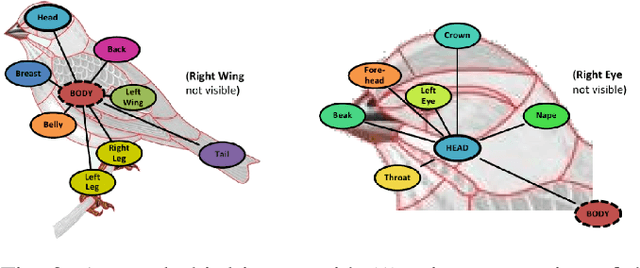

The majority of computer vision algorithms fail to find higher-order (abstract) patterns in an image so are not robust against adversarial attacks, unlike human lateralized vision. Deep learning considers each input pixel in a homogeneous manner such that different parts of a ``locality-sensitive hashing table'' are often not connected, meaning higher-order patterns are not discovered. Hence these systems are not robust against noisy, irrelevant, and redundant data, resulting in the wrong prediction being made with high confidence. Conversely, vertebrate brains afford heterogeneous knowledge representation through lateralization, enabling modular learning at different levels of abstraction. This work aims to verify the effectiveness, scalability, and robustness of a lateralized approach to real-world problems that contain noisy, irrelevant, and redundant data. The experimental results of multi-class (200 classes) image classification show that the novel system effectively learns knowledge representation at multiple levels of abstraction making it more robust than other state-of-the-art techniques. Crucially, the novel lateralized system outperformed all the state-of-the-art deep learning-based systems for the classification of normal and adversarial images by 19.05% - 41.02% and 1.36% - 49.22%, respectively. Findings demonstrate the value of heterogeneous and lateralized learning for computer vision applications.
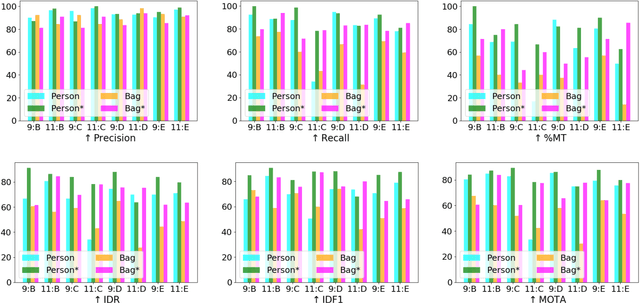
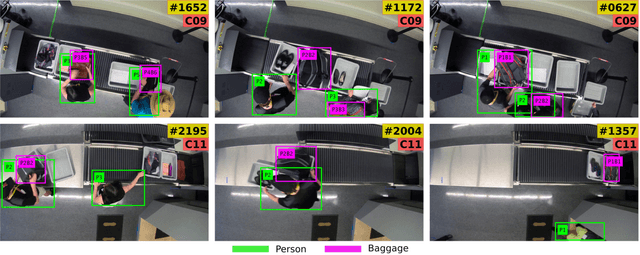
Tracking Passengers and Baggage Items using Multiple Overhead Cameras at Security Checkpoints
Dec 31, 2022We introduce a novel framework to track multiple objects in overhead camera videos for airport checkpoint security scenarios where targets correspond to passengers and their baggage items. We propose a Self-Supervised Learning (SSL) technique to provide the model information about instance segmentation uncertainty from overhead images. Our SSL approach improves object detection by employing a test-time data augmentation and a regression-based, rotation-invariant pseudo-label refinement technique. Our pseudo-label generation method provides multiple geometrically-transformed images as inputs to a Convolutional Neural Network (CNN), regresses the augmented detections generated by the network to reduce localization errors, and then clusters them using the mean-shift algorithm. The self-supervised detector model is used in a single-camera tracking algorithm to generate temporal identifiers for the targets. Our method also incorporates a multi-view trajectory association mechanism to maintain consistent temporal identifiers as passengers travel across camera views. An evaluation of detection, tracking, and association performances on videos obtained from multiple overhead cameras in a realistic airport checkpoint environment demonstrates the effectiveness of the proposed approach. Our results show that self-supervision improves object detection accuracy by up to $42\%$ without increasing the inference time of the model. Our multi-camera association method achieves up to $89\%$ multi-object tracking accuracy with an average computation time of less than $15$ ms.
* 12 pages, 12 figures. arXiv admin note: text overlap with arXiv:2007.07924
Self-supervised Learning for Panoptic Segmentation of Multiple Fruit Flower Species
Sep 10, 2022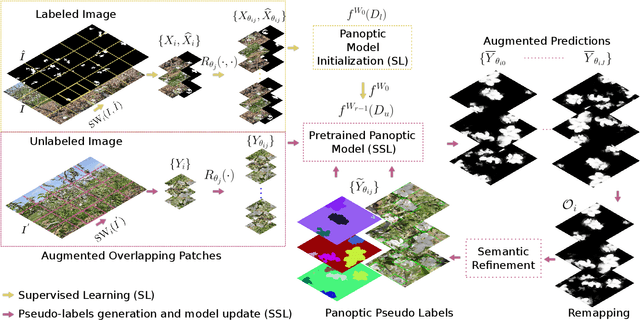



Convolutional neural networks trained using manually generated labels are commonly used for semantic or instance segmentation. In precision agriculture, automated flower detection methods use supervised models and post-processing techniques that may not perform consistently as the appearance of the flowers and the data acquisition conditions vary. We propose a self-supervised learning strategy to enhance the sensitivity of segmentation models to different flower species using automatically generated pseudo-labels. We employ a data augmentation and refinement approach to improve the accuracy of the model predictions. The augmented semantic predictions are then converted to panoptic pseudo-labels to iteratively train a multi-task model. The self-supervised model predictions can be refined with existing post-processing approaches to further improve their accuracy. An evaluation on a multi-species fruit tree flower dataset demonstrates that our method outperforms state-of-the-art models without computationally expensive post-processing steps, providing a new baseline for flower detection applications.
Tracking Passengers and Baggage Items using Multi-camera Systems at Security Checkpoints
Jul 15, 2020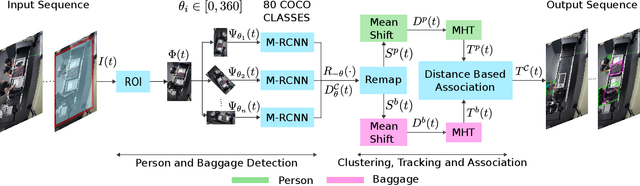
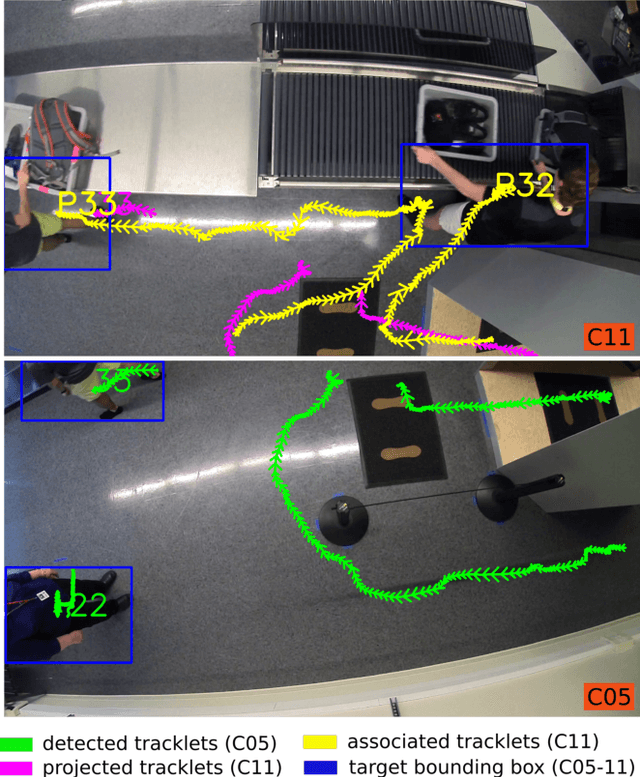
We introduce a novel tracking-by-detection framework to track multiple objects in overhead camera videos for airport checkpoint security scenarios where targets correspond to passengers and their baggage items. Our approach improves object detection by employing a test-time data augmentation procedure that provides multiple geometrically transformed images as inputs to a convolutional neural network. We cluster the multiple detections generated by the network using the mean-shift algorithm. The multiple hypothesis tracking algorithm then keeps track of the temporal identifiers of the targets based on the cluster centroids. Our method also incorporates a trajectory association mechanism to maintain the consistency of the temporal identifiers as passengers travel across camera views. Finally, we also introduce a simple distance-based matching mechanism to associate passengers with their luggage. An evaluation of detection, tracking, and association performances on videos obtained from multiple overhead cameras in a realistic airport checkpoint environment demonstrates the effectiveness of the proposed approach.
Deep Heterogeneous Autoencoder for Subspace Clustering of Sequential Data
Jul 14, 2020
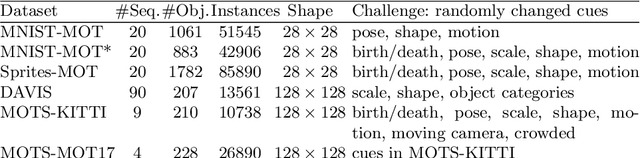
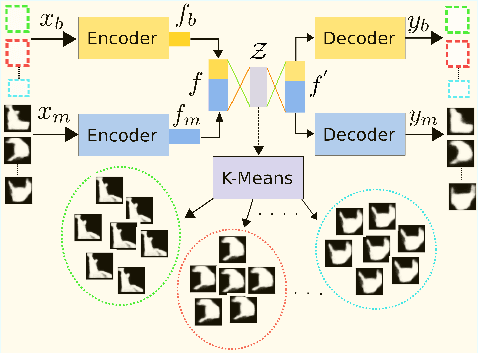
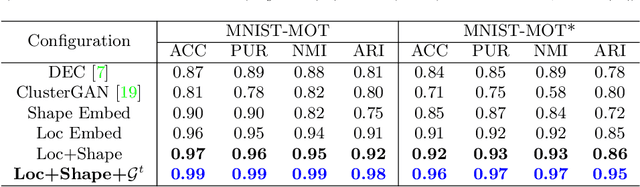
We propose an unsupervised learning approach using a convolutional and fully connected autoencoder, which we call deep heterogeneous autoencoder, to learn discriminative features from segmentation masks and detection bounding boxes. To learn the mask shape information and its corresponding location in an input image, we extract coarse masks from a pretrained semantic segmentation network as well as their corresponding bounding boxes. We train the autoencoders jointly using task-dependent uncertainty weights to generate common latent features. The feature vector is then fed to the k-means clustering algorithm to separate the data points in the latent space. Finally, we incorporate additional penalties in the form of a constraints graph based on prior knowledge of the sequential data to increase clustering robustness. We evaluate the performance of our method using both synthetic and real world multi-object video datasets to demonstrate the applicability of our proposed model. Our results show that the proposed technique outperforms several state-of-the-art methods on challenging video sequences.