 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Heterogeneous Autoencoder for Subspace Clustering of Sequential Data
Paper and Code

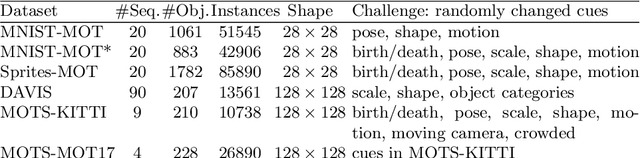
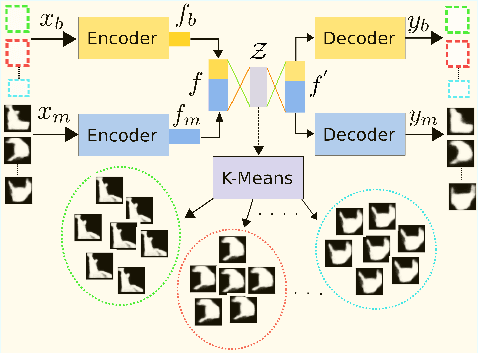
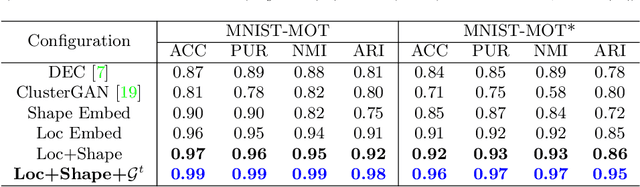
We propose an unsupervised learning approach using a convolutional and fully connected autoencoder, which we call deep heterogeneous autoencoder, to learn discriminative features from segmentation masks and detection bounding boxes. To learn the mask shape information and its corresponding location in an input image, we extract coarse masks from a pretrained semantic segmentation network as well as their corresponding bounding boxes. We train the autoencoders jointly using task-dependent uncertainty weights to generate common latent features. The feature vector is then fed to the k-means clustering algorithm to separate the data points in the latent space. Finally, we incorporate additional penalties in the form of a constraints graph based on prior knowledge of the sequential data to increase clustering robustness. We evaluate the performance of our method using both synthetic and real world multi-object video datasets to demonstrate the applicability of our proposed model. Our results show that the proposed technique outperforms several state-of-the-art methods on challenging video sequences.