 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Distributed Multi-View 3D Tracking in Real-Time
Jun 11, 2026Multi-camera tracking with overlapping fields of view typically relies on centralized fusion, which creates computational bottlenecks that prevent deployment at scale. We present MV3DT, a fully distributed framework for real-time multi-view 3D tracking that achieves accurate identity propagation and occlusion recovery through peer-to-peer coordination, eliminating the need for central aggregation. Each camera node executes a lightweight modular pipeline comprising monocular 3D perception, distributed multi-view association, and collaborative fusion via lightweight messaging. MV3DT achieves 94.3% IDF1 and 93.3% MOTA on WILDTRACK, competitive with state-of-the-art centralized methods, while demonstrating superior scalability by sustaining 30 FPS on 100 cameras with less than 10 ms inter-camera latency and only 2.2% communication overhead. MV3DT operates in a zero-shot regime given camera calibrations, requiring no scene-specific learning and making it directly deployable in new environments. These results establish MV3DT as a practical solution for real-time multi-view tracking in large-scale overlapping camera networks.
Multi-Camera Multi-Person Association using Transformer-Based Dense Pixel Correspondence Estimation and Detection-Based Masking
Aug 17, 2024

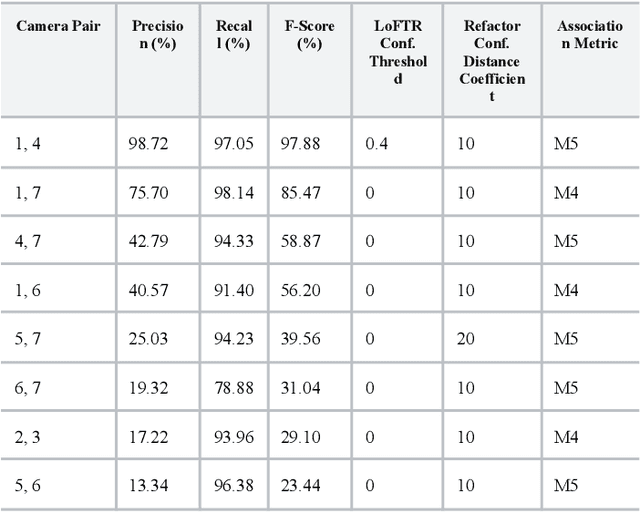

Multi-camera Association (MCA) is the task of identifying objects and individuals across camera views and is an active research topic, given its numerous applications across robotics, surveillance, and agriculture. We investigate a novel multi-camera multi-target association algorithm based on dense pixel correspondence estimation with a Transformer-based architecture and underlying detection-based masking. After the algorithm generates a set of corresponding keypoints and their respective confidence levels between every pair of detections in the camera views are computed, an affinity matrix is determined containing the probabilities of matches between each pair. Finally, the Hungarian algorithm is applied to generate an optimal assignment matrix with all the predicted associations between the camera views. Our method is evaluated on the WILDTRACK Seven-Camera HD Dataset, a high-resolution dataset containing footage of walking pedestrians as well as precise annotations and camera calibrations. Our results conclude that the algorithm performs exceptionally well associating pedestrians on camera pairs that are positioned close to each other and observe the scene from similar perspectives. On camera pairs with orientations that are drastically different in distance or angle, there is still significant room for improvement.
Tracking Passengers and Baggage Items using Multiple Overhead Cameras at Security Checkpoints
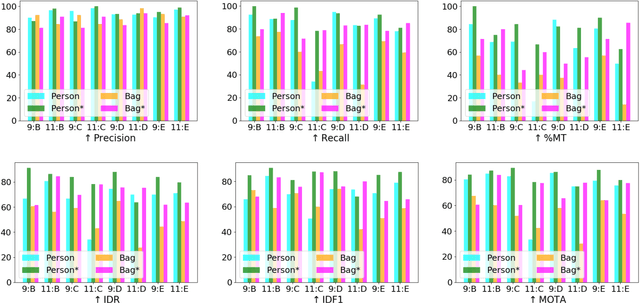
Dec 31, 2022We introduce a novel framework to track multiple objects in overhead camera videos for airport checkpoint security scenarios where targets correspond to passengers and their baggage items. We propose a Self-Supervised Learning (SSL) technique to provide the model information about instance segmentation uncertainty from overhead images. Our SSL approach improves object detection by employing a test-time data augmentation and a regression-based, rotation-invariant pseudo-label refinement technique. Our pseudo-label generation method provides multiple geometrically-transformed images as inputs to a Convolutional Neural Network (CNN), regresses the augmented detections generated by the network to reduce localization errors, and then clusters them using the mean-shift algorithm. The self-supervised detector model is used in a single-camera tracking algorithm to generate temporal identifiers for the targets. Our method also incorporates a multi-view trajectory association mechanism to maintain consistent temporal identifiers as passengers travel across camera views. An evaluation of detection, tracking, and association performances on videos obtained from multiple overhead cameras in a realistic airport checkpoint environment demonstrates the effectiveness of the proposed approach. Our results show that self-supervision improves object detection accuracy by up to $42\%$ without increasing the inference time of the model. Our multi-camera association method achieves up to $89\%$ multi-object tracking accuracy with an average computation time of less than $15$ ms.
* 12 pages, 12 figures. arXiv admin note: text overlap with arXiv:2007.07924
Self-supervised Learning for Panoptic Segmentation of Multiple Fruit Flower Species
Sep 10, 2022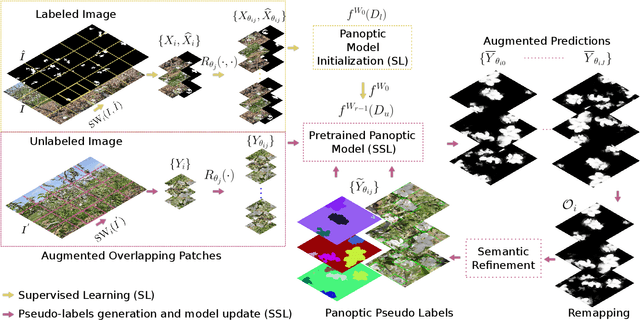



Convolutional neural networks trained using manually generated labels are commonly used for semantic or instance segmentation. In precision agriculture, automated flower detection methods use supervised models and post-processing techniques that may not perform consistently as the appearance of the flowers and the data acquisition conditions vary. We propose a self-supervised learning strategy to enhance the sensitivity of segmentation models to different flower species using automatically generated pseudo-labels. We employ a data augmentation and refinement approach to improve the accuracy of the model predictions. The augmented semantic predictions are then converted to panoptic pseudo-labels to iteratively train a multi-task model. The self-supervised model predictions can be refined with existing post-processing approaches to further improve their accuracy. An evaluation on a multi-species fruit tree flower dataset demonstrates that our method outperforms state-of-the-art models without computationally expensive post-processing steps, providing a new baseline for flower detection applications.
Deep Convolutional Correlation Iterative Particle Filter for Visual Tracking
Jul 07, 2021This work proposes a novel framework for visual tracking based on the integration of an iterative particle filter, a deep convolutional neural network, and a correlation filter. The iterative particle filter enables the particles to correct themselves and converge to the correct target position. We employ a novel strategy to assess the likelihood of the particles after the iterations by applying K-means clustering. Our approach ensures a consistent support for the posterior distribution. Thus, we do not need to perform resampling at every video frame, improving the utilization of prior distribution information. Experimental results on two different benchmark datasets show that our tracker performs favorably against state-of-the-art methods.
Tracking Passengers and Baggage Items using Multi-camera Systems at Security Checkpoints
Jul 15, 2020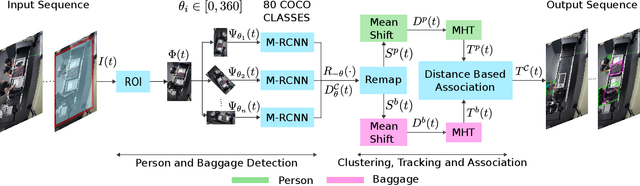
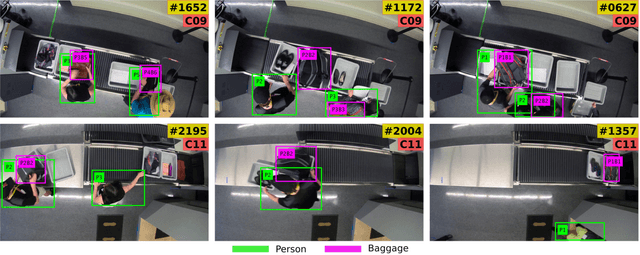
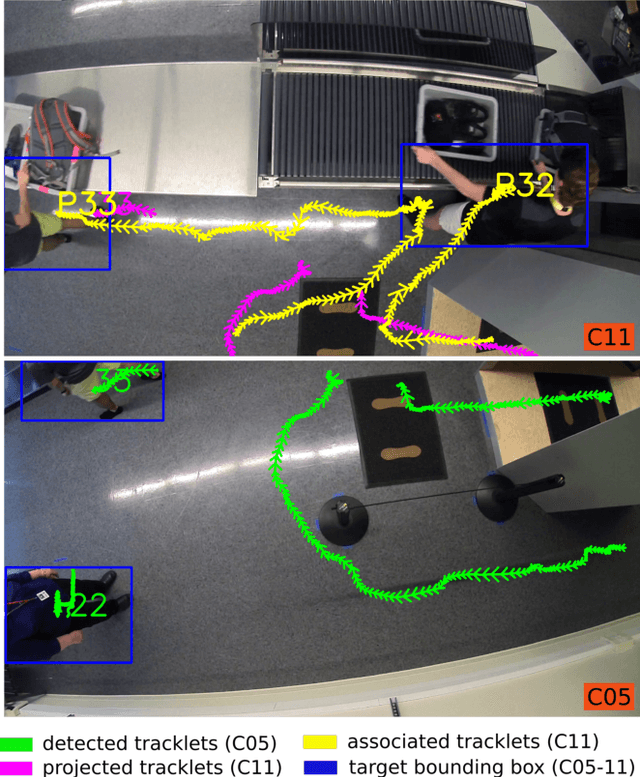
We introduce a novel tracking-by-detection framework to track multiple objects in overhead camera videos for airport checkpoint security scenarios where targets correspond to passengers and their baggage items. Our approach improves object detection by employing a test-time data augmentation procedure that provides multiple geometrically transformed images as inputs to a convolutional neural network. We cluster the multiple detections generated by the network using the mean-shift algorithm. The multiple hypothesis tracking algorithm then keeps track of the temporal identifiers of the targets based on the cluster centroids. Our method also incorporates a trajectory association mechanism to maintain the consistency of the temporal identifiers as passengers travel across camera views. Finally, we also introduce a simple distance-based matching mechanism to associate passengers with their luggage. An evaluation of detection, tracking, and association performances on videos obtained from multiple overhead cameras in a realistic airport checkpoint environment demonstrates the effectiveness of the proposed approach.
Deep Heterogeneous Autoencoder for Subspace Clustering of Sequential Data
Jul 14, 2020
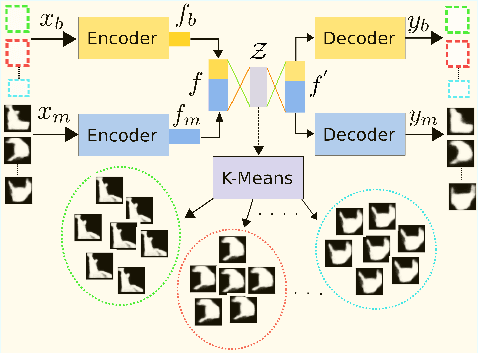
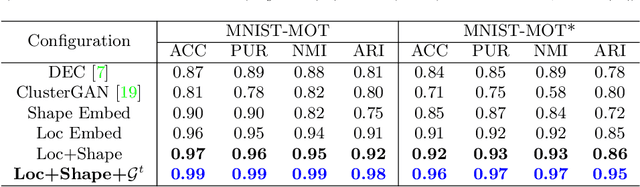
We propose an unsupervised learning approach using a convolutional and fully connected autoencoder, which we call deep heterogeneous autoencoder, to learn discriminative features from segmentation masks and detection bounding boxes. To learn the mask shape information and its corresponding location in an input image, we extract coarse masks from a pretrained semantic segmentation network as well as their corresponding bounding boxes. We train the autoencoders jointly using task-dependent uncertainty weights to generate common latent features. The feature vector is then fed to the k-means clustering algorithm to separate the data points in the latent space. Finally, we incorporate additional penalties in the form of a constraints graph based on prior knowledge of the sequential data to increase clustering robustness. We evaluate the performance of our method using both synthetic and real world multi-object video datasets to demonstrate the applicability of our proposed model. Our results show that the proposed technique outperforms several state-of-the-art methods on challenging video sequences.
Deep Convolutional Likelihood Particle Filter for Visual Tracking
Jun 11, 2020
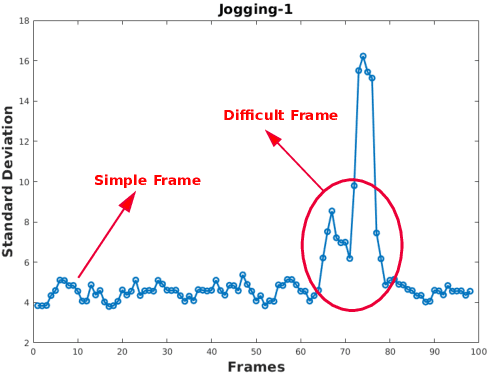

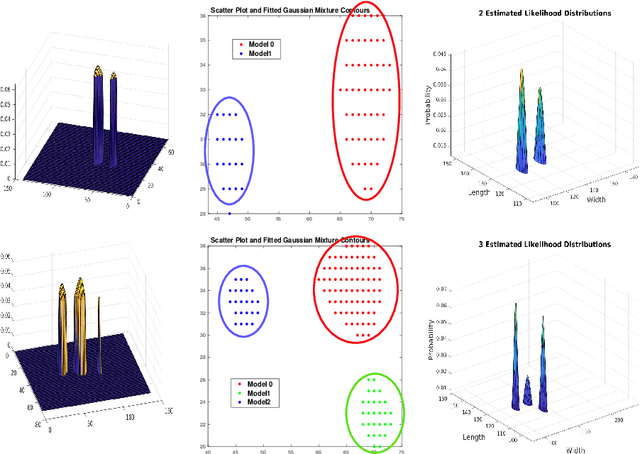
We propose a novel particle filter for convolutional-correlation visual trackers. Our method uses correlation response maps to estimate likelihood distributions and employs these likelihoods as proposal densities to sample particles. Likelihood distributions are more reliable than proposal densities based on target transition distributions because correlation response maps provide additional information regarding the target's location. Additionally, our particle filter searches for multiple modes in the likelihood distribution, which improves performance in target occlusion scenarios while decreasing computational costs by more efficiently sampling particles. In other challenging scenarios such as those involving motion blur, where only one mode is present but a larger search area may be necessary, our particle filter allows for the variance of the likelihood distribution to increase. We tested our algorithm on the Visual Tracker Benchmark v1.1 (OTB100) and our experimental results demonstrate that our framework outperforms state-of-the-art methods.
Probabilistic Semantic Segmentation Refinement by Monte Carlo Region Growing
May 12, 2020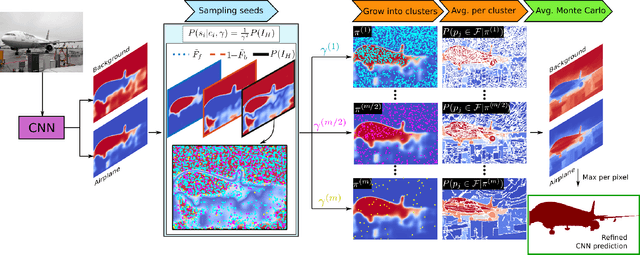
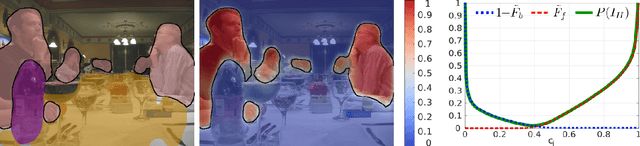
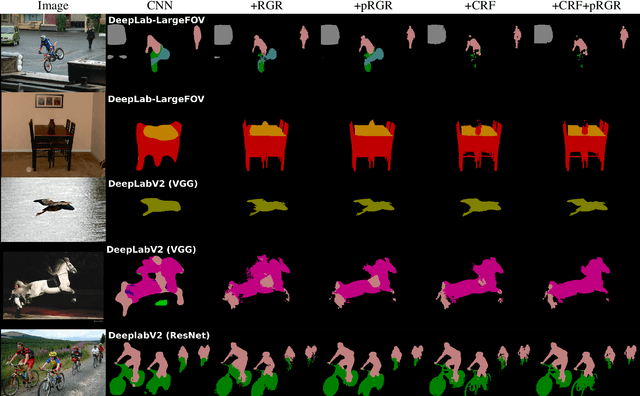
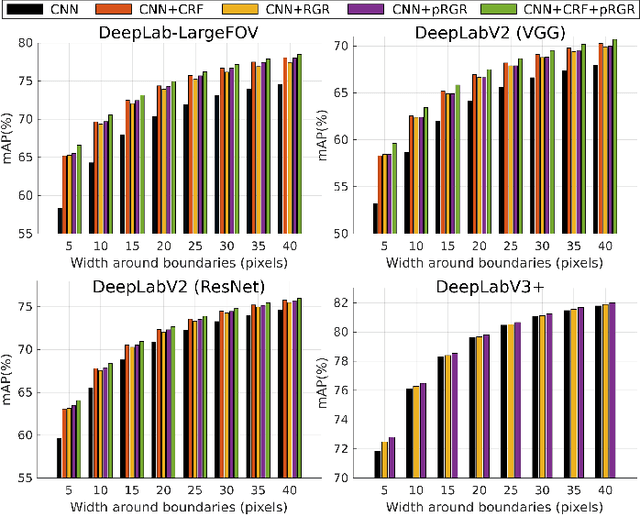
Semantic segmentation with fine-grained pixel-level accuracy is a fundamental component of a variety of computer vision applications. However, despite the large improvements provided by recent advances in the architectures of convolutional neural networks, segmentations provided by modern state-of-the-art methods still show limited boundary adherence. We introduce a fully unsupervised post-processing algorithm that exploits Monte Carlo sampling and pixel similarities to propagate high-confidence pixel labels into regions of low-confidence classification. Our algorithm, which we call probabilistic Region Growing Refinement (pRGR), is based on a rigorous mathematical foundation in which clusters are modelled as multivariate normally distributed sets of pixels. Exploiting concepts of Bayesian estimation and variance reduction techniques, pRGR performs multiple refinement iterations at varied receptive fields sizes, while updating cluster statistics to adapt to local image features. Experiments using multiple modern semantic segmentation networks and benchmark datasets demonstrate the effectiveness of our approach for the refinement of segmentation predictions at different levels of coarseness, as well as the suitability of the variance estimates obtained in the Monte Carlo iterations as uncertainty measures that are highly correlated with segmentation accuracy.
Gaze Estimation for Assisted Living Environments
Sep 19, 2019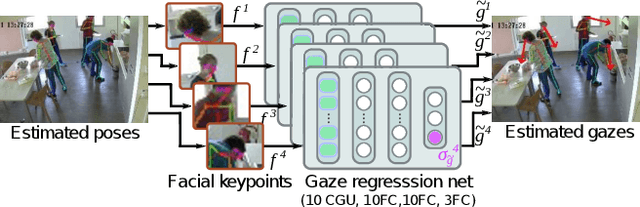
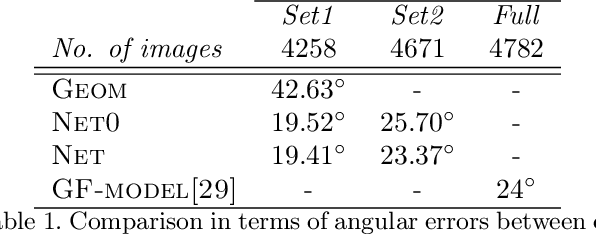

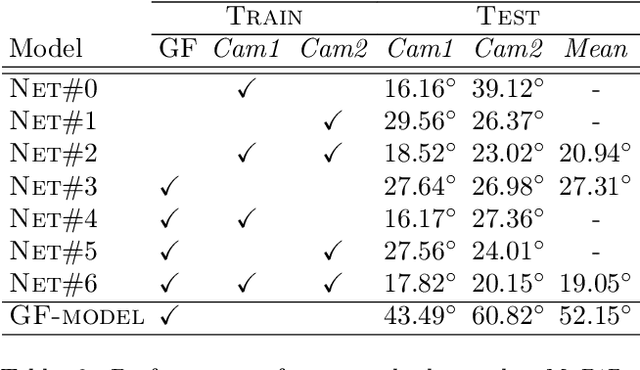
Effective assisted living environments must be able to perform inferences on how their occupants interact with one another as well as with surrounding objects. To accomplish this goal using a vision-based automated approach, multiple tasks such as pose estimation, object segmentation and gaze estimation must be addressed. Gaze direction in particular provides some of the strongest indications of how a person interacts with the environment. In this paper, we propose a simple neural network regressor that estimates the gaze direction of individuals in a multi-camera assisted living scenario, relying only on the relative positions of facial keypoints collected from a single pose estimation model. To handle cases of keypoint occlusion, our model exploits a novel confidence gated unit in its input layer. In addition to the gaze direction, our model also outputs an estimation of its own prediction uncertainty. Experimental results on a public benchmark demonstrate that our approach performs on pair with a complex, dataset-specific baseline, while its uncertainty predictions are highly correlated to the actual angular error of corresponding estimations. Finally, experiments on images from a real assisted living environment demonstrate the higher suitability of our model for its final application.