 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Semantic Segmentation Refinement by Monte Carlo Region Growing
May 12, 2020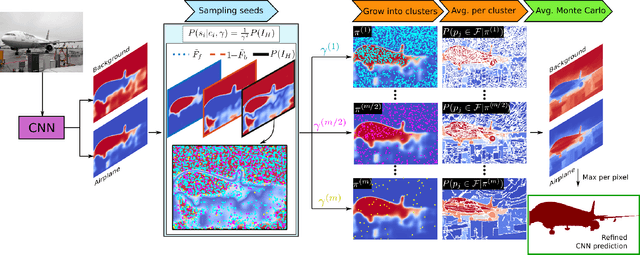
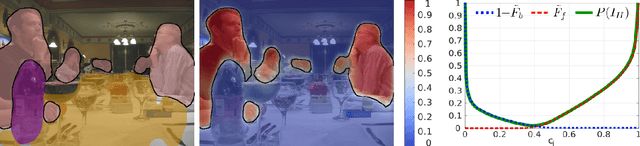
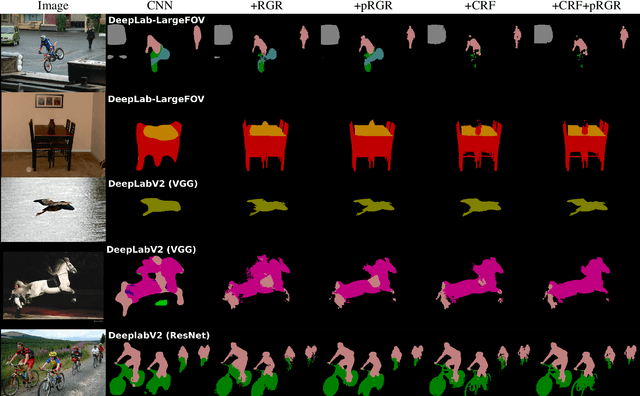
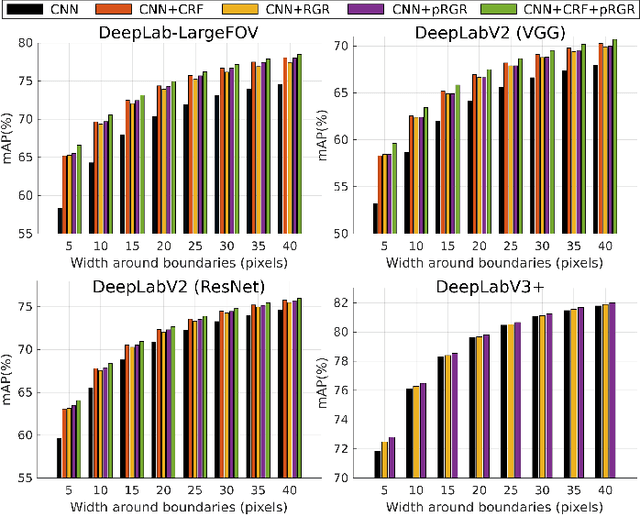
Semantic segmentation with fine-grained pixel-level accuracy is a fundamental component of a variety of computer vision applications. However, despite the large improvements provided by recent advances in the architectures of convolutional neural networks, segmentations provided by modern state-of-the-art methods still show limited boundary adherence. We introduce a fully unsupervised post-processing algorithm that exploits Monte Carlo sampling and pixel similarities to propagate high-confidence pixel labels into regions of low-confidence classification. Our algorithm, which we call probabilistic Region Growing Refinement (pRGR), is based on a rigorous mathematical foundation in which clusters are modelled as multivariate normally distributed sets of pixels. Exploiting concepts of Bayesian estimation and variance reduction techniques, pRGR performs multiple refinement iterations at varied receptive fields sizes, while updating cluster statistics to adapt to local image features. Experiments using multiple modern semantic segmentation networks and benchmark datasets demonstrate the effectiveness of our approach for the refinement of segmentation predictions at different levels of coarseness, as well as the suitability of the variance estimates obtained in the Monte Carlo iterations as uncertainty measures that are highly correlated with segmentation accuracy.
Gaze Estimation for Assisted Living Environments
Sep 19, 2019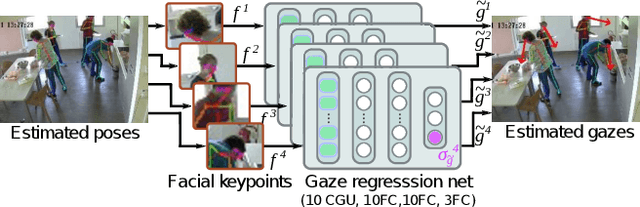
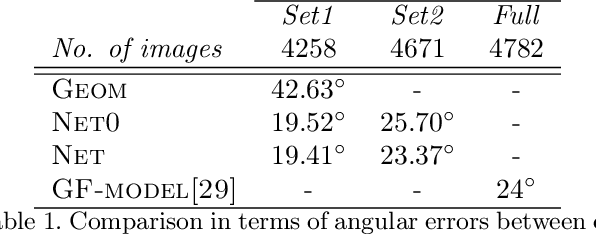

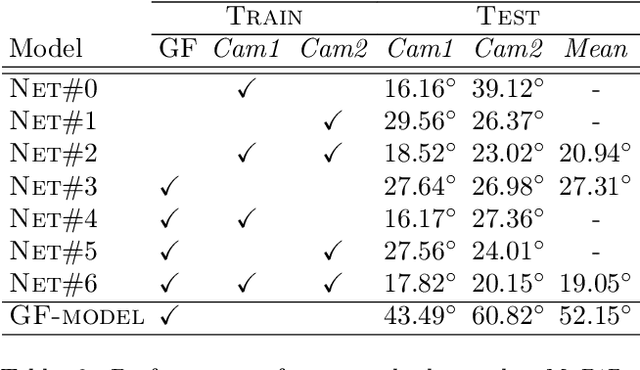
Effective assisted living environments must be able to perform inferences on how their occupants interact with one another as well as with surrounding objects. To accomplish this goal using a vision-based automated approach, multiple tasks such as pose estimation, object segmentation and gaze estimation must be addressed. Gaze direction in particular provides some of the strongest indications of how a person interacts with the environment. In this paper, we propose a simple neural network regressor that estimates the gaze direction of individuals in a multi-camera assisted living scenario, relying only on the relative positions of facial keypoints collected from a single pose estimation model. To handle cases of keypoint occlusion, our model exploits a novel confidence gated unit in its input layer. In addition to the gaze direction, our model also outputs an estimation of its own prediction uncertainty. Experimental results on a public benchmark demonstrate that our approach performs on pair with a complex, dataset-specific baseline, while its uncertainty predictions are highly correlated to the actual angular error of corresponding estimations. Finally, experiments on images from a real assisted living environment demonstrate the higher suitability of our model for its final application.
FreeLabel: A Publicly Available Annotation Tool based on Freehand Traces
Mar 11, 2019
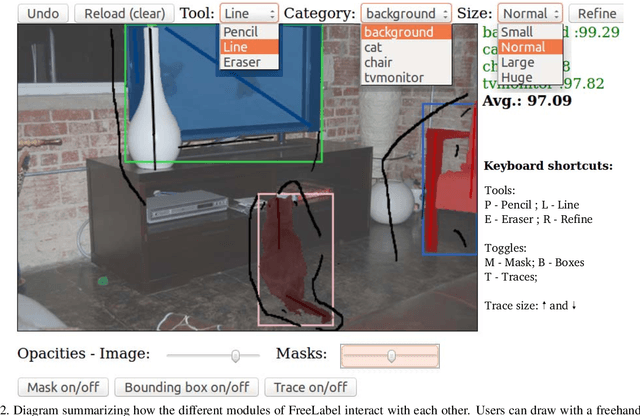

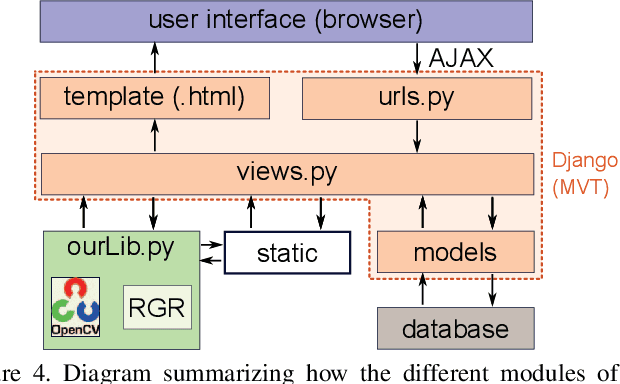
Large-scale annotation of image segmentation datasets is often prohibitively expensive, as it usually requires a huge number of worker hours to obtain high-quality results. Abundant and reliable data has been, however, crucial for the advances on image understanding tasks achieved by deep learning models. In this paper, we introduce FreeLabel, an intuitive open-source web interface that allows users to obtain high-quality segmentation masks with just a few freehand scribbles, in a matter of seconds. The efficacy of FreeLabel is quantitatively demonstrated by experimental results on the PASCAL dataset as well as on a dataset from the agricultural domain. Designed to benefit the computer vision community, FreeLabel can be used for both crowdsourced or private annotation and has a modular structure that can be easily adapted for any image dataset.
* Accepted and presented at 2019 IEEE Winter Conference on Applications of Computer Vision (WACV). 10 pages
Multispecies fruit flower detection using a refined semantic segmentation network
Sep 20, 2018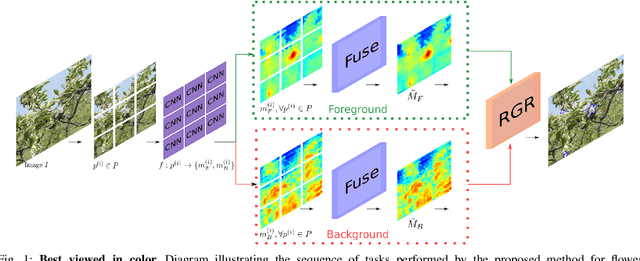
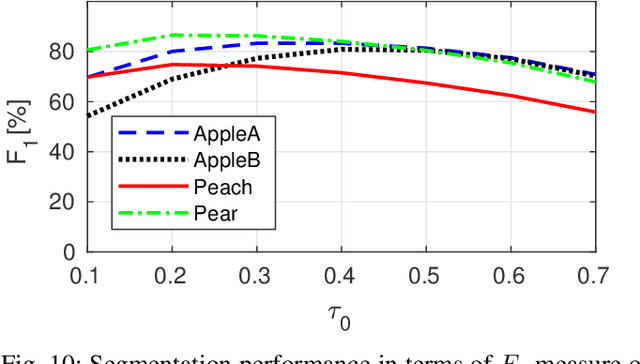
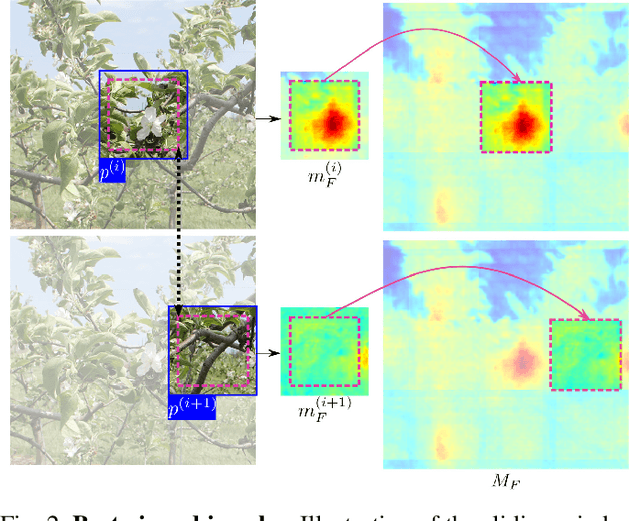
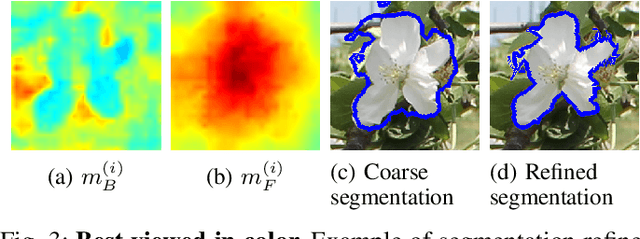
In fruit production, critical crop management decisions are guided by bloom intensity, i.e., the number of flowers present in an orchard. Despite its importance, bloom intensity is still typically estimated by means of human visual inspection. Existing automated computer vision systems for flower identification are based on hand-engineered techniques that work only under specific conditions and with limited performance. This work proposes an automated technique for flower identification that is robust to uncontrolled environments and applicable to different flower species. Our method relies on an end-to-end residual convolutional neural network (CNN) that represents the state-of-the-art in semantic segmentation. To enhance its sensitivity to flowers, we fine-tune this network using a single dataset of apple flower images. Since CNNs tend to produce coarse segmentations, we employ a refinement method to better distinguish between individual flower instances. Without any pre-processing or dataset-specific training, experimental results on images of apple, peach and pear flowers, acquired under different conditions demonstrate the robustness and broad applicability of our method.
* 8 pages
Apple Flower Detection using Deep Convolutional Networks
Sep 17, 2018
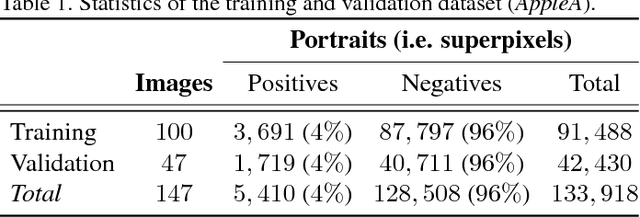
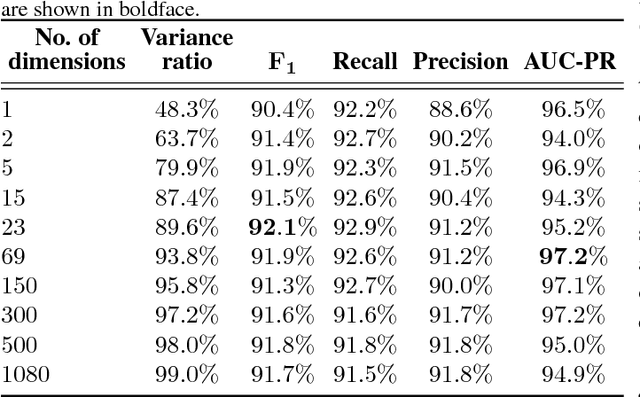

To optimize fruit production, a portion of the flowers and fruitlets of apple trees must be removed early in the growing season. The proportion to be removed is determined by the bloom intensity, i.e., the number of flowers present in the orchard. Several automated computer vision systems have been proposed to estimate bloom intensity, but their overall performance is still far from satisfactory even in relatively controlled environments. With the goal of devising a technique for flower identification which is robust to clutter and to changes in illumination, this paper presents a method in which a pre-trained convolutional neural network is fine-tuned to become specially sensitive to flowers. Experimental results on a challenging dataset demonstrate that our method significantly outperforms three approaches that represent the state of the art in flower detection, with recall and precision rates higher than $90\%$. Moreover, a performance assessment on three additional datasets previously unseen by the network, which consist of different flower species and were acquired under different conditions, reveals that the proposed method highly surpasses baseline approaches in terms of generalization capability.
* 14 pages
Semantic Segmentation Refinement by Monte Carlo Region Growing of High Confidence Detections
Feb 21, 2018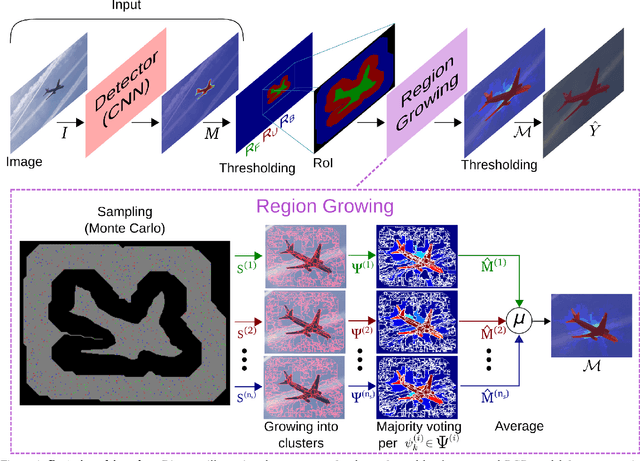

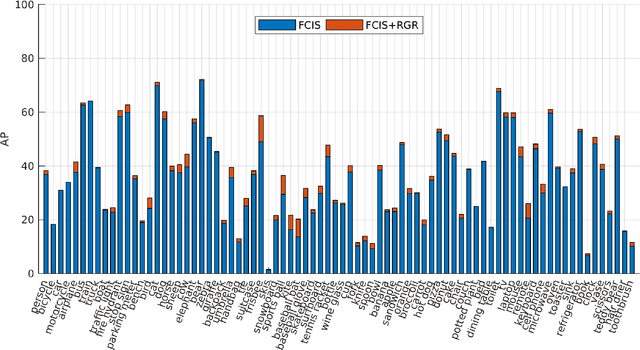

Despite recent improvements using fully convolutional networks, in general, the segmentation produced by most state-of-the-art semantic segmentation methods does not show satisfactory adherence to the object boundaries. We propose a method to refine the segmentation results generated by such deep learning models. Our method takes as input the confidence scores generated by a pixel-dense segmentation network and re-labels pixels with low confidence levels. The re-labeling approach employs a region growing mechanism that aggregates these pixels to neighboring areas with high confidence scores and similar appearance. In order to correct the labels of pixels that were incorrectly classified with high confidence level by the semantic segmentation algorithm, we generate multiple region growing steps through a Monte Carlo sampling of the seeds of the regions. Our method improves the accuracy of a state-of-the-art fully convolutional semantic segmentation approach on the publicly available COCO and PASCAL datasets, and it shows significantly better results on selected sequences of the finely-annotated DAVIS dataset.