 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperparameter Optimisation with Practical Interpretability and Explanation Methods in Probabilistic Curriculum Learning
Apr 09, 2025Hyperparameter optimisation (HPO) is crucial for achieving strong performance in reinforcement learning (RL), as RL algorithms are inherently sensitive to hyperparameter settings. Probabilistic Curriculum Learning (PCL) is a curriculum learning strategy designed to improve RL performance by structuring the agent's learning process, yet effective hyperparameter tuning remains challenging and computationally demanding. In this paper, we provide an empirical analysis of hyperparameter interactions and their effects on the performance of a PCL algorithm within standard RL tasks, including point-maze navigation and DC motor control. Using the AlgOS framework integrated with Optuna's Tree-Structured Parzen Estimator (TPE), we present strategies to refine hyperparameter search spaces, enhancing optimisation efficiency. Additionally, we introduce a novel SHAP-based interpretability approach tailored specifically for analysing hyperparameter impacts, offering clear insights into how individual hyperparameters and their interactions influence RL performance. Our work contributes practical guidelines and interpretability tools that significantly improve the effectiveness and computational feasibility of hyperparameter optimisation in reinforcement learning.
AlgOS: Algorithm Operating System
Apr 07, 2025Algorithm Operating System (AlgOS) is an unopinionated, extensible, modular framework for algorithmic implementations. AlgOS offers numerous features: integration with Optuna for automated hyperparameter tuning; automated argument parsing for generic command-line interfaces; automated registration of new classes; and a centralised database for logging experiments and studies. These features are designed to reduce the overhead of implementing new algorithms and to standardise the comparison of algorithms. The standardisation of algorithmic implementations is crucial for reproducibility and reliability in research. AlgOS combines Abstract Syntax Trees with a novel implementation of the Observer pattern to control the logical flow of algorithmic segments.
Probabilistic Curriculum Learning for Goal-Based Reinforcement Learning
Apr 02, 2025Reinforcement learning (RL) -- algorithms that teach artificial agents to interact with environments by maximising reward signals -- has achieved significant success in recent years. These successes have been facilitated by advances in algorithms (e.g., deep Q-learning, deep deterministic policy gradients, proximal policy optimisation, trust region policy optimisation, and soft actor-critic) and specialised computational resources such as GPUs and TPUs. One promising research direction involves introducing goals to allow multimodal policies, commonly through hierarchical or curriculum reinforcement learning. These methods systematically decompose complex behaviours into simpler sub-tasks, analogous to how humans progressively learn skills (e.g. we learn to run before we walk, or we learn arithmetic before calculus). However, fully automating goal creation remains an open challenge. We present a novel probabilistic curriculum learning algorithm to suggest goals for reinforcement learning agents in continuous control and navigation tasks.
Parameter Optimization and Learning in a Spiking Neural Network for UAV Obstacle Avoidance targeting Neuromorphic Processors
Oct 17, 2019
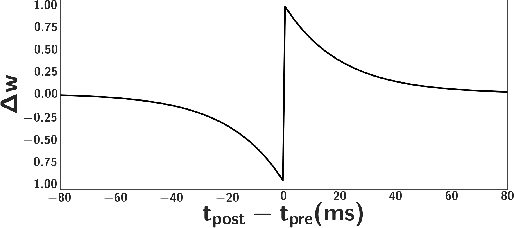

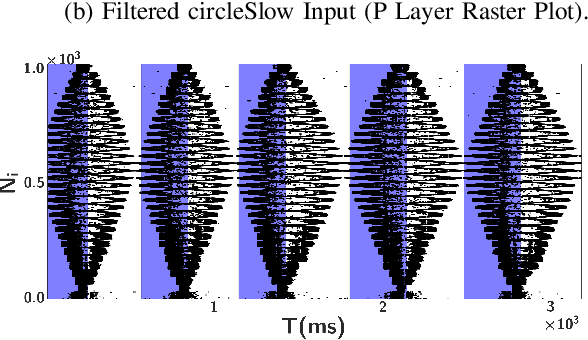
The Lobula Giant Movement Detector (LGMD) is an identified neuron of the locust that detects looming objects and triggers the insect's escape responses. Understanding the neural principles and network structure that lead to these fast and robust responses can facilitate the design of efficient obstacle avoidance strategies for robotic applications. Here we present a neuromorphic spiking neural network model of the LGMD driven by the output of a neuromorphic Dynamic Vision Sensor (DVS), which incorporates spiking frequency adaptation and synaptic plasticity mechanisms, and which can be mapped onto existing neuromorphic processor chips. However, as the model has a wide range of parameters, and the mixed signal analogue-digital circuits used to implement the model are affected by variability and noise, it is necessary to optimise the parameters to produce robust and reliable responses. Here we propose to use Differential Evolution (DE) and Bayesian Optimisation (BO) techniques to optimise the parameter space and investigate the use of Self-Adaptive Differential Evolution (SADE) to ameliorate the difficulties of finding appropriate input parameters for the DE technique. We quantify the performance of the methods proposed with a comprehensive comparison of different optimisers applied to the model, and demonstrate the validity of the approach proposed using recordings made from a DVS sensor mounted on a UAV.