 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity-based Portfolio Construction for Black-box Optimization
Apr 20, 2026In black-box optimization, a central question is which algorithm to use to solve a given, previously unseen, problem. Selecting a single algorithm, however, entails inherent risks: inaccuracies in the selector may lead to poor choices, and even well-performing algorithms with high variance can yield unsatisfactory results in a single run. A natural remedy is to split the evaluation budget across multiple runs of potentially different algorithms. Such sequential algorithm portfolios benefit from variance reduction and complementarities between algorithms, often outperforming approaches that allocate the entire budget to a single solver. While effective portfolios can be constructed post-hoc, transferring this idea to the algorithm selection setting is non-trivial. We show that a naive portfolio constructed over the full training set already outperforms the strongest traditional baseline, the virtual best solver. We then propose a simple yet effective k-nearest-neighbor-based finetuning approach to construct portfolios tailored to unseen instances, yielding further improvements and highlighting the effectiveness of portfolio selection in fixed-budget black-box optimization.
How Sequential Algorithm Portfolios can benefit Black Box Optimization
Jan 23, 2026In typical black-box optimization applications, the available computational budget is often allocated to a single algorithm, typically chosen based on user preference with limited knowledge about the problem at hand or according to some expert knowledge. However, we show that splitting the budget across several algorithms yield significantly better results. This approach benefits from both algorithm complementarity across diverse problems and variance reduction within individual functions, and shows that algorithm portfolios do NOT require parallel evaluation capabilities. To demonstrate the advantage of sequential algorithm portfolios, we apply it to the COCO data archive, using over 200 algorithms evaluated on the BBOB test suite. The proposed sequential portfolios consistently outperform single-algorithm baselines, achieving relative performance gains of over 14%, and offering new insights into restart mechanisms and potential for warm-started execution strategies.
A Standardized Benchmark Set of Clustering Problem Instances for Comparing Black-Box Optimizers
May 14, 2025
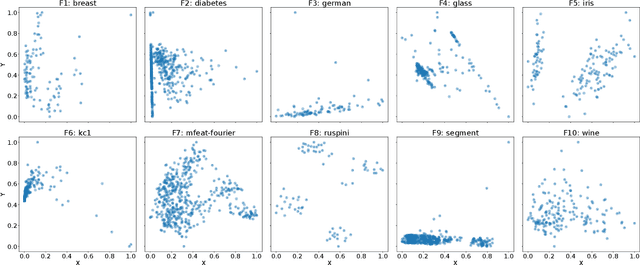

One key challenge in optimization is the selection of a suitable set of benchmark problems. A common goal is to find functions which are representative of a class of real-world optimization problems in order to ensure findings on the benchmarks will translate to relevant problem domains. While some problem characteristics are well-covered by popular benchmarking suites, others are often overlooked. One example of such a problem characteristic is permutation invariance, where the search space consists of a set of symmetrical search regions. This type of problem occurs e.g. when a set of solutions has to be found, but the ordering within this set does not matter. The data clustering problem, often seen in machine learning contexts, is a clear example of such an optimization landscape, and has thus been proposed as a base from which optimization benchmarks can be created. In addition to the symmetry aspect, these clustering problems also contain potential regions of neutrality, which can provide an additional challenge to optimization algorithms. In this paper, we present a standardized benchmark suite for the evaluation of continuous black-box optimization algorithms, based on data clustering problems. To gain insight into the diversity of the benchmark set, both internally and in comparison to existing suites, we perform a benchmarking study of a set of modular CMA-ES configurations, as well as an analysis using exploratory landscape analysis. Our benchmark set is open-source and integrated with the IOHprofiler benchmarking framework to encourage its use in future research.
Reinforcement learning for Quantum Tiq-Taq-Toe
Nov 10, 2024Quantum Tiq-Taq-Toe is a well-known benchmark and playground for both quantum computing and machine learning. Despite its popularity, no reinforcement learning (RL) methods have been applied to Quantum Tiq-Taq-Toe. Although there has been some research on Quantum Chess this game is significantly more complex in terms of computation and analysis. Therefore, we study the combination of quantum computing and reinforcement learning in Quantum Tiq-Taq-Toe, which may serve as an accessible testbed for the integration of both fields. Quantum games are challenging to represent classically due to their inherent partial observability and the potential for exponential state complexity. In Quantum Tiq-Taq-Toe, states are observed through Measurement (a 3x3 matrix of state probabilities) and Move History (a 9x9 matrix of entanglement relations), making strategy complex as each move can collapse the quantum state.
An Adaptive Re-evaluation Method for Evolution Strategy under Additive Noise
Sep 25, 2024


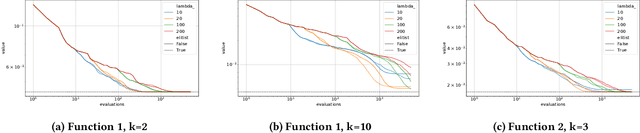
The Covariance Matrix Adaptation Evolutionary Strategy (CMA-ES) is one of the most advanced algorithms in numerical black-box optimization. For noisy objective functions, several approaches were proposed to mitigate the noise, e.g., re-evaluations of the same solution or adapting the population size. In this paper, we devise a novel method to adaptively choose the optimal re-evaluation number for function values corrupted by additive Gaussian white noise. We derive a theoretical lower bound of the expected improvement achieved in one iteration of CMA-ES, given an estimation of the noise level and the Lipschitz constant of the function's gradient. Solving for the maximum of the lower bound, we obtain a simple expression of the optimal re-evaluation number. We experimentally compare our method to the state-of-the-art noise-handling methods for CMA-ES on a set of artificial test functions across various noise levels, optimization budgets, and dimensionality. Our method demonstrates significant advantages in terms of the probability of hitting near-optimal function values.