 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Weighted Combination Method for Feature Selection using Fuzzy Sets
May 21, 2020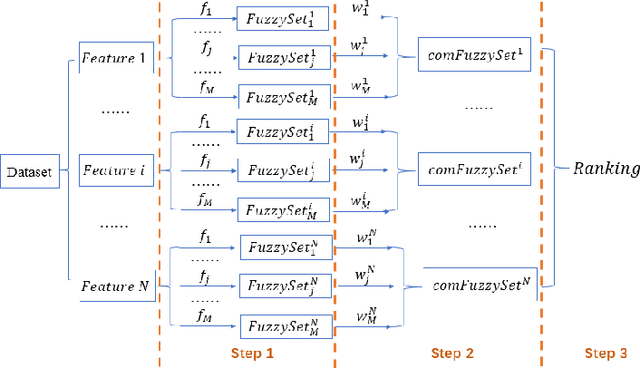


In this paper, we propose a novel weighted combination feature selection method using bootstrap and fuzzy sets. The proposed method mainly consists of three processes, including fuzzy sets generation using bootstrap, weighted combination of fuzzy sets and feature ranking based on defuzzification. We implemented the proposed method by combining four state-of-the-art feature selection methods and evaluated the performance based on three publicly available biomedical datasets using five-fold cross validation. Based on the feature selection results, our proposed method produced comparable (if not better) classification accuracies to the best of the individual feature selection methods for all evaluated datasets. More importantly, we also applied standard deviation and Pearson's correlation to measure the stability of the methods. Remarkably, our combination method achieved significantly higher stability than the four individual methods when variations and size reductions were introduced to the datasets.
Performance Optimization of a Fuzzy Entropy based Feature Selection and Classification Framework
May 21, 2020



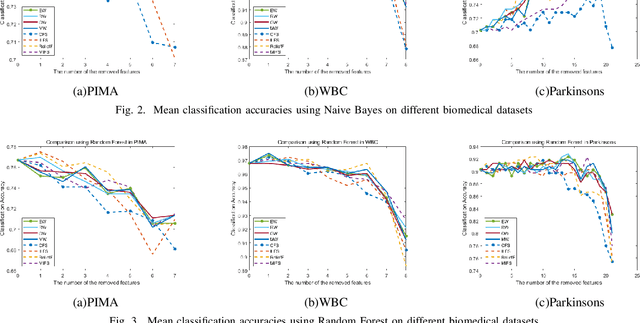
In this paper, based on a fuzzy entropy feature selection framework, different methods have been implemented and compared to improve the key components of the framework. Those methods include the combinations of three ideal vector calculations, three maximal similarity classifiers and three fuzzy entropy functions. Different feature removal orders based on the fuzzy entropy values were also compared. The proposed method was evaluated on three publicly available biomedical datasets. From the experiments, we concluded the optimized combination of the ideal vector, similarity classifier and fuzzy entropy function for feature selection. The optimized framework was also compared with other six classical filter-based feature selection methods. The proposed method was ranked as one of the top performers together with the Correlation and ReliefF methods. More importantly, the proposed method achieved the most stable performance for all three datasets when the features being gradually removed. This indicates a better feature ranking performance than the other compared methods.
A Novel Meta Learning Framework for Feature Selection using Data Synthesis and Fuzzy Similarity
May 21, 2020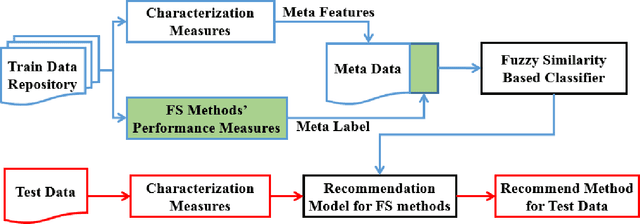

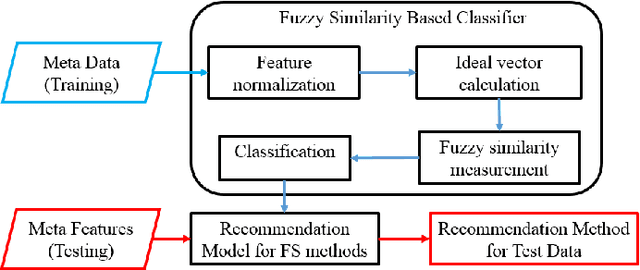
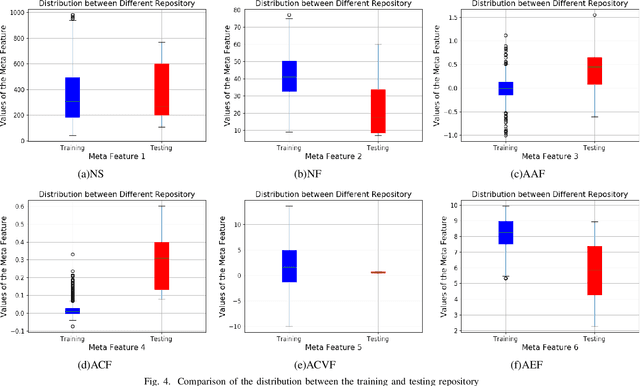
This paper presents a novel meta learning framework for feature selection (FS) based on fuzzy similarity. The proposed method aims to recommend the best FS method from four candidate FS methods for any given dataset. This is achieved by firstly constructing a large training data repository using data synthesis. Six meta features that represent the characteristics of the training dataset are then extracted. The best FS method for each of the training datasets is used as the meta label. Both the meta features and the corresponding meta labels are subsequently used to train a classification model using a fuzzy similarity measure based framework. Finally the trained model is used to recommend the most suitable FS method for a given unseen dataset. This proposed method was evaluated based on eight public datasets of real-world applications. It successfully recommended the best method for five datasets and the second best method for one dataset, which outperformed any of the four individual FS methods. Besides, the proposed method is computationally efficient for algorithm selection, leading to negligible additional time for the feature selection process. Thus, the paper contributes a novel method for effectively recommending which feature selection method to use for any new given dataset.