 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEFI: A Toolbox for Feature Importance Fusion and Interpretation in Python
Aug 08, 2022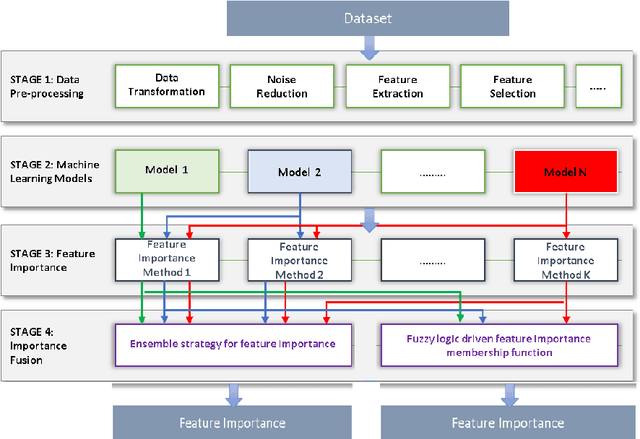
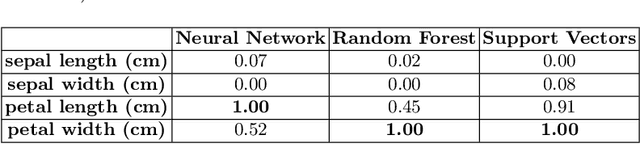
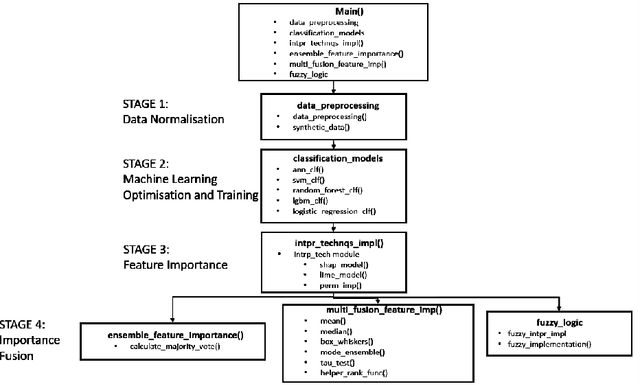

This paper presents an open-source Python toolbox called Ensemble Feature Importance (EFI) to provide machine learning (ML) researchers, domain experts, and decision makers with robust and accurate feature importance quantification and more reliable mechanistic interpretation of feature importance for prediction problems using fuzzy sets. The toolkit was developed to address uncertainties in feature importance quantification and lack of trustworthy feature importance interpretation due to the diverse availability of machine learning algorithms, feature importance calculation methods, and dataset dependencies. EFI merges results from multiple machine learning models with different feature importance calculation approaches using data bootstrapping and decision fusion techniques, such as mean, majority voting and fuzzy logic. The main attributes of the EFI toolbox are: (i) automatic optimisation of ML algorithms, (ii) automatic computation of a set of feature importance coefficients from optimised ML algorithms and feature importance calculation techniques, (iii) automatic aggregation of importance coefficients using multiple decision fusion techniques, and (iv) fuzzy membership functions that show the importance of each feature to the prediction task. The key modules and functions of the toolbox are described, and a simple example of their application is presented using the popular Iris dataset.
Anomaly Detection for Unmanned Aerial Vehicle Sensor Data Using a Stacked Recurrent Autoencoder Method with Dynamic Thresholding
Mar 09, 2022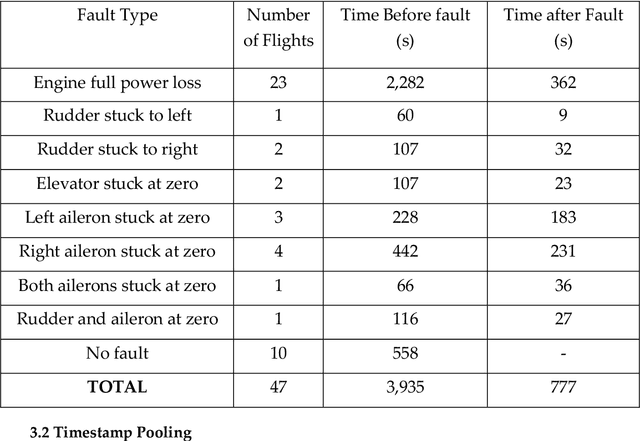
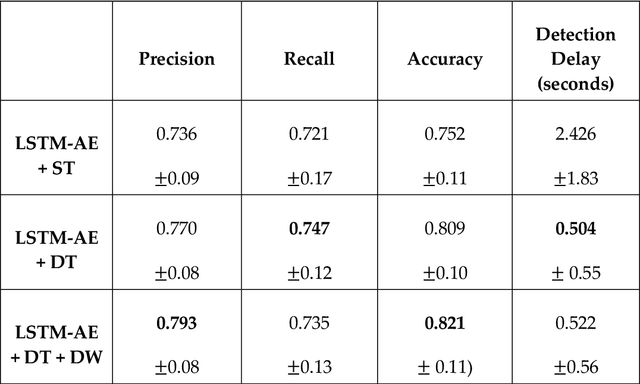
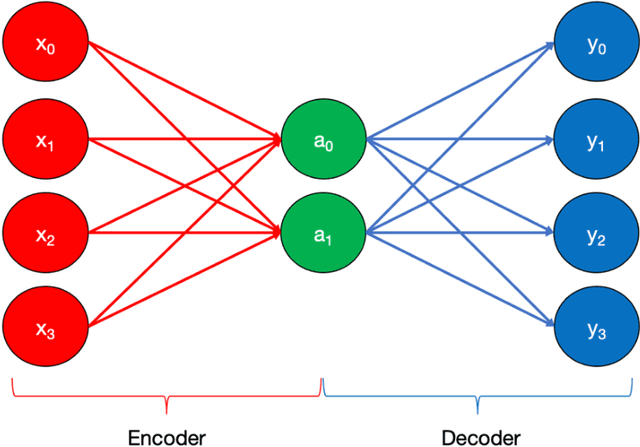
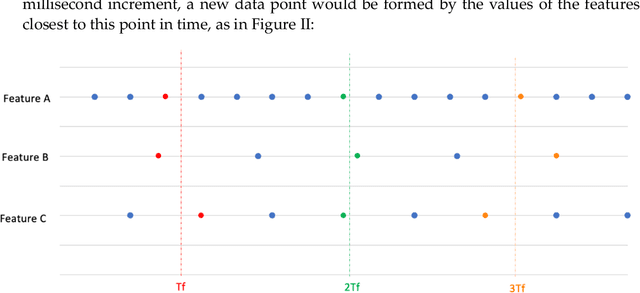
With substantial recent developments in aviation technologies, Unmanned Aerial Vehicles (UAVs) are becoming increasingly integrated in commercial and military operations internationally. Research into the applications of aircraft data is essential in improving safety, reducing operational costs, and developing the next frontier of aerial technology. Having an outlier detection system that can accurately identify anomalous behaviour in aircraft is crucial for these reasons. This paper proposes a system incorporating a Long Short-Term Memory (LSTM) Deep Learning Autoencoder based method with a novel dynamic thresholding algorithm and weighted loss function for anomaly detection of a UAV dataset, in order to contribute to the ongoing efforts that leverage innovations in machine learning and data analysis within the aviation industry. The dynamic thresholding and weighted loss functions showed promising improvements to the standard static thresholding method, both in accuracy-related performance metrics and in speed of true fault detection.
Mechanistic Interpretation of Machine Learning Inference: A Fuzzy Feature Importance Fusion Approach
Oct 22, 2021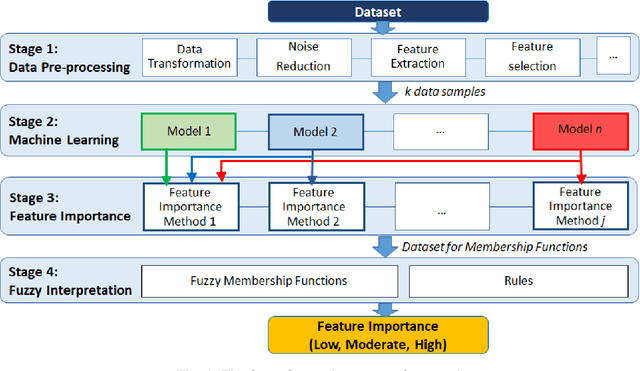
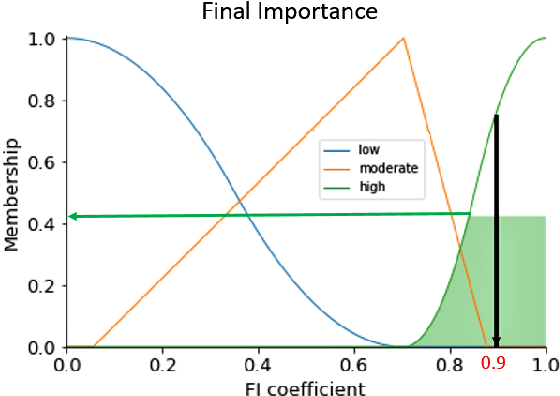
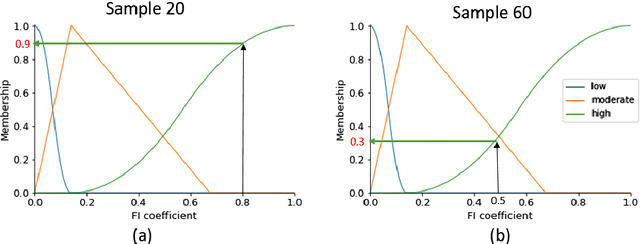
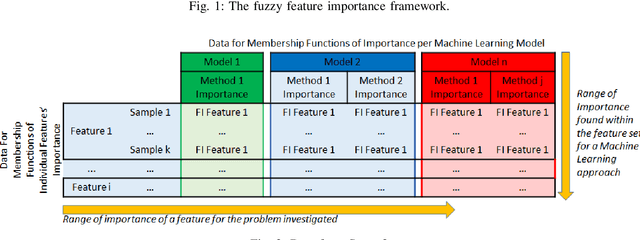
With the widespread use of machine learning to support decision-making, it is increasingly important to verify and understand the reasons why a particular output is produced. Although post-training feature importance approaches assist this interpretation, there is an overall lack of consensus regarding how feature importance should be quantified, making explanations of model predictions unreliable. In addition, many of these explanations depend on the specific machine learning approach employed and on the subset of data used when calculating feature importance. A possible solution to improve the reliability of explanations is to combine results from multiple feature importance quantifiers from different machine learning approaches coupled with re-sampling. Current state-of-the-art ensemble feature importance fusion uses crisp techniques to fuse results from different approaches. There is, however, significant loss of information as these approaches are not context-aware and reduce several quantifiers to a single crisp output. More importantly, their representation of 'importance' as coefficients is misleading and incomprehensible to end-users and decision makers. Here we show how the use of fuzzy data fusion methods can overcome some of the important limitations of crisp fusion methods.
Towards a More Reliable Interpretation of Machine Learning Outputs for Safety-Critical Systems using Feature Importance Fusion
Sep 11, 2020



When machine learning supports decision-making in safety-critical systems, it is important to verify and understand the reasons why a particular output is produced. Although feature importance calculation approaches assist in interpretation, there is a lack of consensus regarding how features' importance is quantified, which makes the explanations offered for the outcomes mostly unreliable. A possible solution to address the lack of agreement is to combine the results from multiple feature importance quantifiers to reduce the variance of estimates. Our hypothesis is that this will lead to more robust and trustworthy interpretations of the contribution of each feature to machine learning predictions. To assist test this hypothesis, we propose an extensible Framework divided in four main parts: (i) traditional data pre-processing and preparation for predictive machine learning models; (ii) predictive machine learning; (iii) feature importance quantification and (iv) feature importance decision fusion using an ensemble strategy. We also introduce a novel fusion metric and compare it to the state-of-the-art. Our approach is tested on synthetic data, where the ground truth is known. We compare different fusion approaches and their results for both training and test sets. We also investigate how different characteristics within the datasets affect the feature importance ensembles studied. Results show that our feature importance ensemble Framework overall produces 15% less feature importance error compared to existing methods. Additionally, results reveal that different levels of noise in the datasets do not affect the feature importance ensembles' ability to accurately quantify feature importance, whereas the feature importance quantification error increases with the number of features and number of orthogonal informative features.