 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOLD Fusion: Calibrated and Ordinal Latent Distribution Fusion for Uncertainty-Aware Multimodal Emotion Recognition
Paper and Code
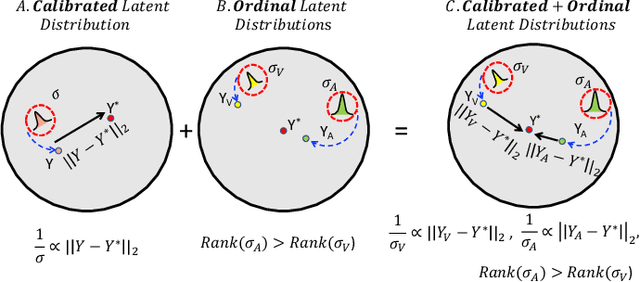

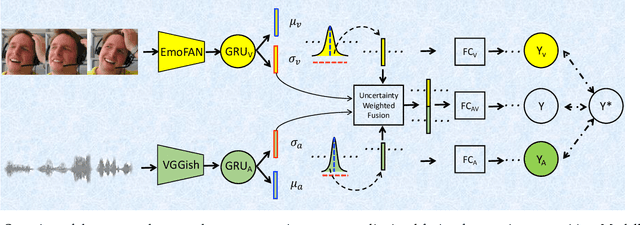

Automatically recognising apparent emotions from face and voice is hard, in part because of various sources of uncertainty, including in the input data and the labels used in a machine learning framework. This paper introduces an uncertainty-aware audiovisual fusion approach that quantifies modality-wise uncertainty towards emotion prediction. To this end, we propose a novel fusion framework in which we first learn latent distributions over audiovisual temporal context vectors separately, and then constrain the variance vectors of unimodal latent distributions so that they represent the amount of information each modality provides w.r.t. emotion recognition. In particular, we impose Calibration and Ordinal Ranking constraints on the variance vectors of audiovisual latent distributions. When well-calibrated, modality-wise uncertainty scores indicate how much their corresponding predictions may differ from the ground truth labels. Well-ranked uncertainty scores allow the ordinal ranking of different frames across the modalities. To jointly impose both these constraints, we propose a softmax distributional matching loss. In both classification and regression settings, we compare our uncertainty-aware fusion model with standard model-agnostic fusion baselines. Our evaluation on two emotion recognition corpora, AVEC 2019 CES and IEMOCAP, shows that audiovisual emotion recognition can considerably benefit from well-calibrated and well-ranked latent uncertainty measures.