 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Imaging AI Competitions Lack Fairness
Dec 19, 2025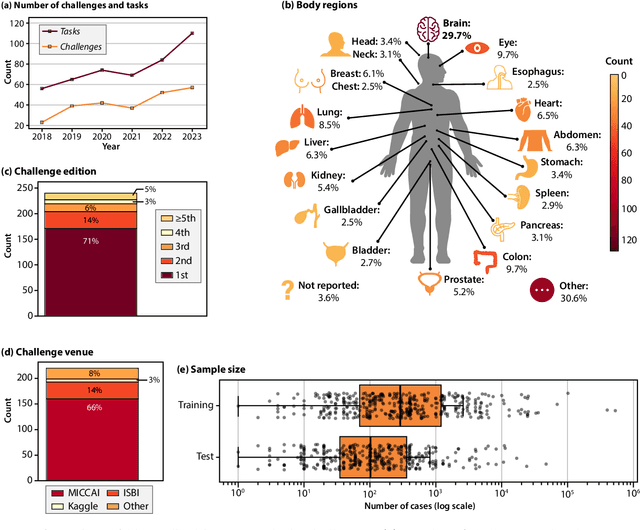
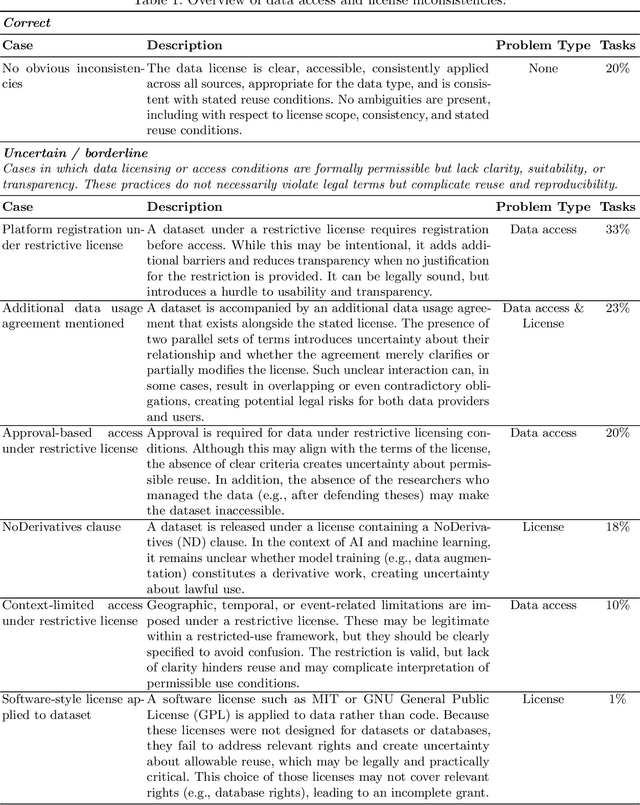
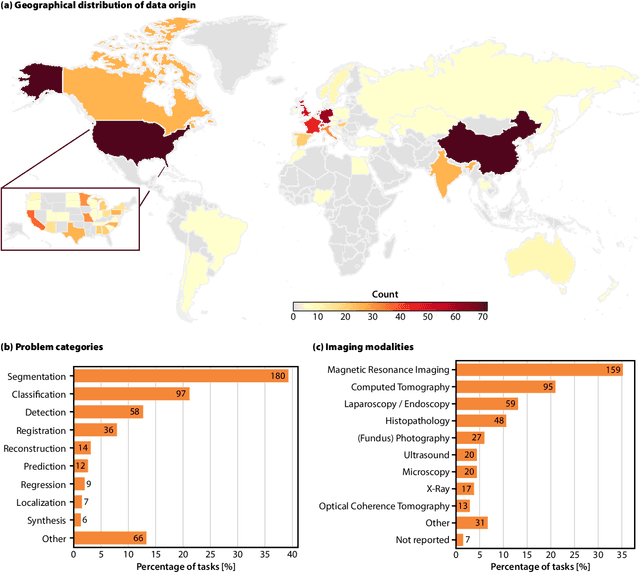
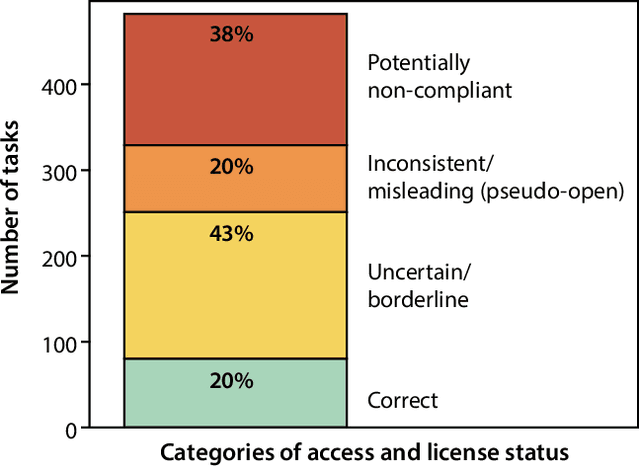
Benchmarking competitions are central to the development of artificial intelligence (AI) in medical imaging, defining performance standards and shaping methodological progress. However, it remains unclear whether these benchmarks provide data that are sufficiently representative, accessible, and reusable to support clinically meaningful AI. In this work, we assess fairness along two complementary dimensions: (1) whether challenge datasets are representative of real-world clinical diversity, and (2) whether they are accessible and legally reusable in line with the FAIR principles. To address this question, we conducted a large-scale systematic study of 241 biomedical image analysis challenges comprising 458 tasks across 19 imaging modalities. Our findings show substantial biases in dataset composition, including geographic location, modality-, and problem type-related biases, indicating that current benchmarks do not adequately reflect real-world clinical diversity. Despite their widespread influence, challenge datasets were frequently constrained by restrictive or ambiguous access conditions, inconsistent or non-compliant licensing practices, and incomplete documentation, limiting reproducibility and long-term reuse. Together, these shortcomings expose foundational fairness limitations in our benchmarking ecosystem and highlight a disconnect between leaderboard success and clinical relevance.
Improving Deep Facial Phenotyping for Ultra-rare Disorder Verification Using Model Ensembles
Nov 12, 2022



Rare genetic disorders affect more than 6% of the global population. Reaching a diagnosis is challenging because rare disorders are very diverse. Many disorders have recognizable facial features that are hints for clinicians to diagnose patients. Previous work, such as GestaltMatcher, utilized representation vectors produced by a DCNN similar to AlexNet to match patients in high-dimensional feature space to support "unseen" ultra-rare disorders. However, the architecture and dataset used for transfer learning in GestaltMatcher have become outdated. Moreover, a way to train the model for generating better representation vectors for unseen ultra-rare disorders has not yet been studied. Because of the overall scarcity of patients with ultra-rare disorders, it is infeasible to directly train a model on them. Therefore, we first analyzed the influence of replacing GestaltMatcher DCNN with a state-of-the-art face recognition approach, iResNet with ArcFace. Additionally, we experimented with different face recognition datasets for transfer learning. Furthermore, we proposed test-time augmentation, and model ensembles that mix general face verification models and models specific for verifying disorders to improve the disorder verification accuracy of unseen ultra-rare disorders. Our proposed ensemble model achieves state-of-the-art performance on both seen and unseen disorders.
Few-Shot Meta Learning for Recognizing Facial Phenotypes of Genetic Disorders
Oct 23, 2022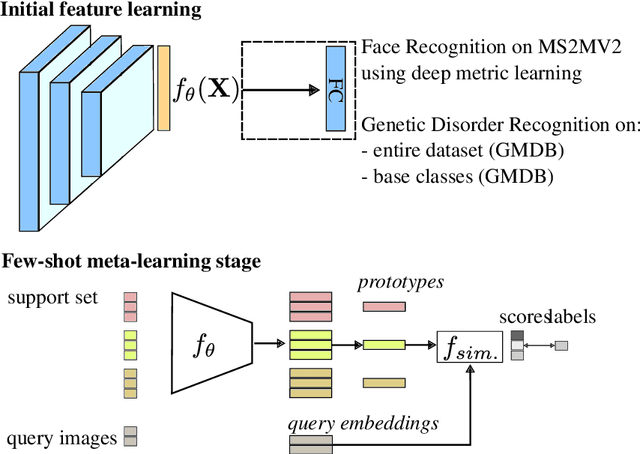
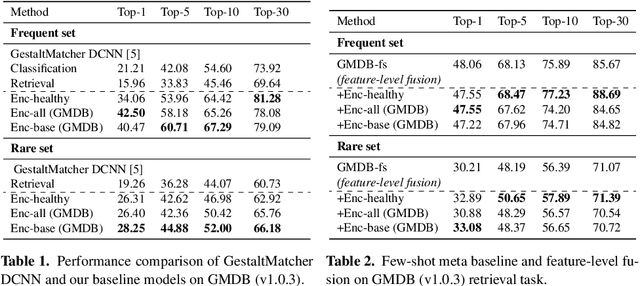
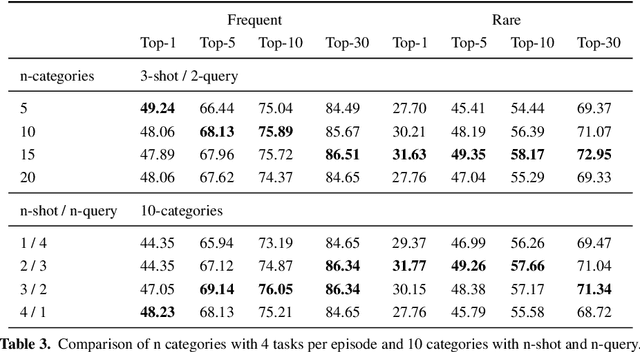
Computer vision-based methods have valuable use cases in precision medicine, and recognizing facial phenotypes of genetic disorders is one of them. Many genetic disorders are known to affect faces' visual appearance and geometry. Automated classification and similarity retrieval aid physicians in decision-making to diagnose possible genetic conditions as early as possible. Previous work has addressed the problem as a classification problem and used deep learning methods. The challenging issue in practice is the sparse label distribution and huge class imbalances across categories. Furthermore, most disorders have few labeled samples in training sets, making representation learning and generalization essential to acquiring a reliable feature descriptor. In this study, we used a facial recognition model trained on a large corpus of healthy individuals as a pre-task and transferred it to facial phenotype recognition. Furthermore, we created simple baselines of few-shot meta-learning methods to improve our base feature descriptor. Our quantitative results on GestaltMatcher Database show that our CNN baseline surpasses previous works, including GestaltMatcher, and few-shot meta-learning strategies improve retrieval performance in frequent and rare classes.
Are 3D Face Shapes Expressive Enough for Recognising Continuous Emotions and Action Unit Intensities?
Jul 03, 2022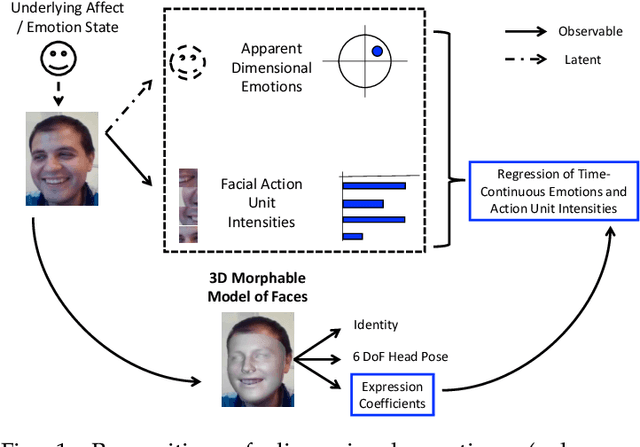
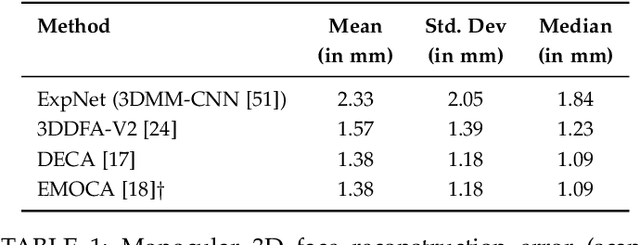
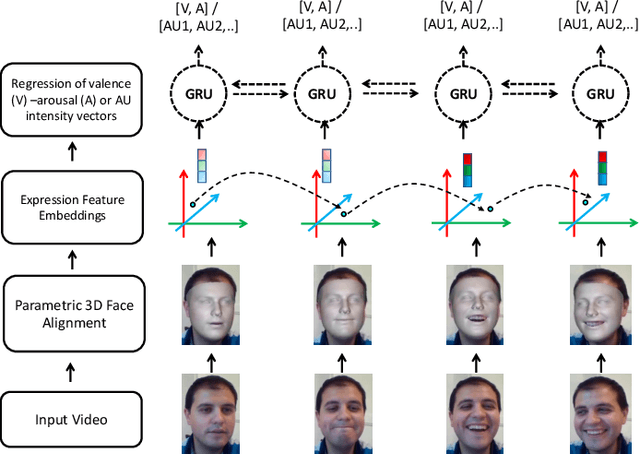
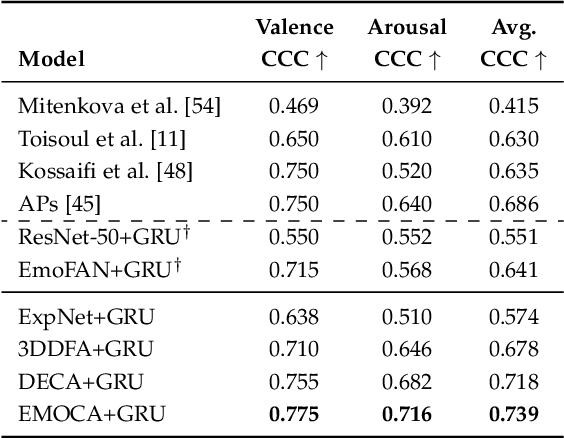
Recognising continuous emotions and action unit (AU) intensities from face videos requires a spatial and temporal understanding of expression dynamics. Existing works primarily rely on 2D face appearances to extract such dynamics. This work focuses on a promising alternative based on parametric 3D face shape alignment models, which disentangle different factors of variation, including expression-induced shape variations. We aim to understand how expressive 3D face shapes are in estimating valence-arousal and AU intensities compared to the state-of-the-art 2D appearance-based models. We benchmark four recent 3D face alignment models: ExpNet, 3DDFA-V2, DECA, and EMOCA. In valence-arousal estimation, expression features of 3D face models consistently surpassed previous works and yielded an average concordance correlation of .739 and .574 on SEWA and AVEC 2019 CES corpora, respectively. We also study how 3D face shapes performed on AU intensity estimation on BP4D and DISFA datasets, and report that 3D face features were on par with 2D appearance features in AUs 4, 6, 10, 12, and 25, but not the entire set of AUs. To understand this discrepancy, we conduct a correspondence analysis between valence-arousal and AUs, which points out that accurate prediction of valence-arousal may require the knowledge of only a few AUs.
Estimating Presentation Competence using Multimodal Nonverbal Behavioral Cues
May 06, 2021
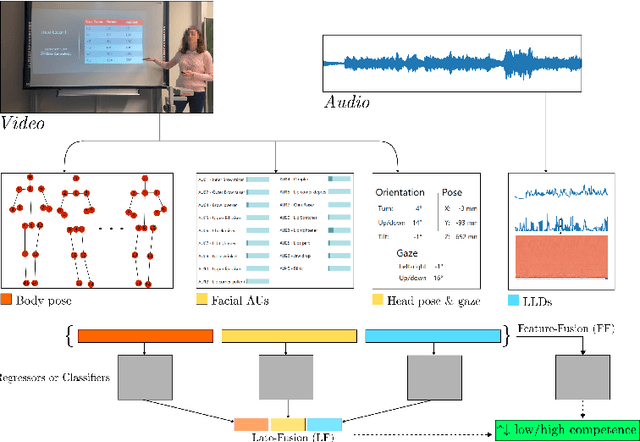

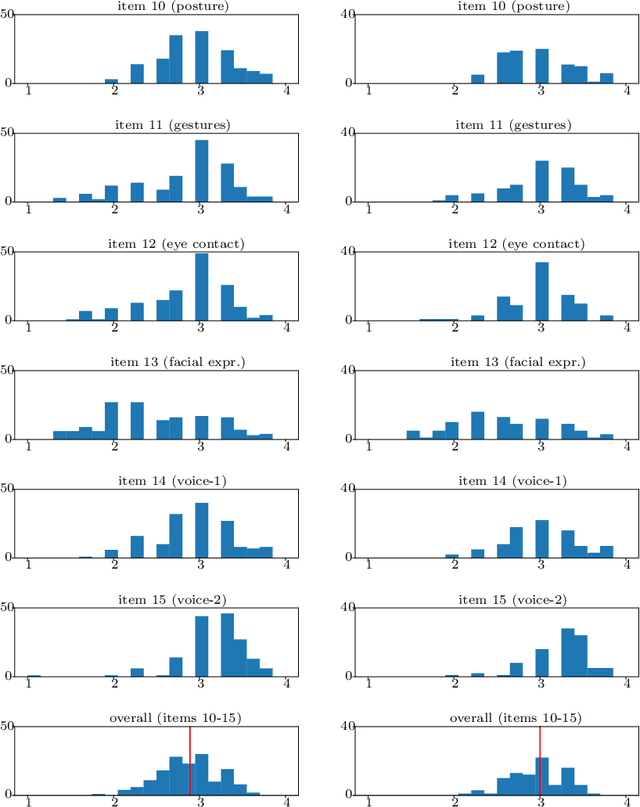
Public speaking and presentation competence plays an essential role in many areas of social interaction in our educational, professional, and everyday life. Since our intention during a speech can differ from what is actually understood by the audience, the ability to appropriately convey our message requires a complex set of skills. Presentation competence is cultivated in the early school years and continuously developed over time. One approach that can promote efficient development of presentation competence is the automated analysis of human behavior during a speech based on visual and audio features and machine learning. Furthermore, this analysis can be used to suggest improvements and the development of skills related to presentation competence. In this work, we investigate the contribution of different nonverbal behavioral cues, namely, facial, body pose-based, and audio-related features, to estimate presentation competence. The analyses were performed on videos of 251 students while the automated assessment is based on manual ratings according to the T\"ubingen Instrument for Presentation Competence (TIP). Our classification results reached the best performance with early fusion in the same dataset evaluation (accuracy of 71.25%) and late fusion of speech, face, and body pose features in the cross dataset evaluation (accuracy of 78.11%). Similarly, regression results performed the best with fusion strategies.
Multimodal Engagement Analysis from Facial Videos in the Classroom
Jan 22, 2021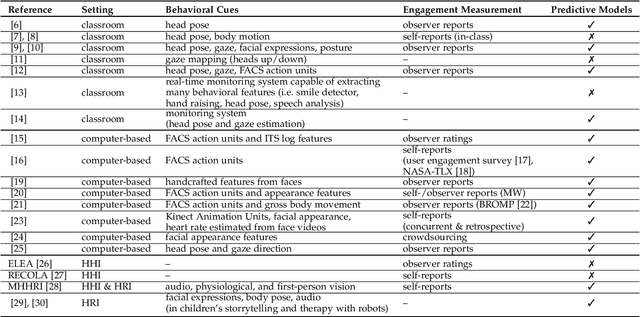
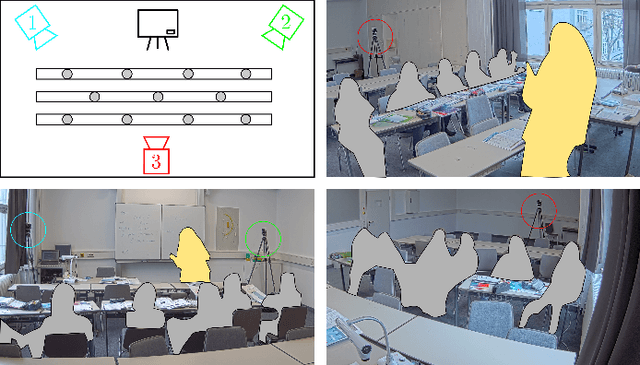
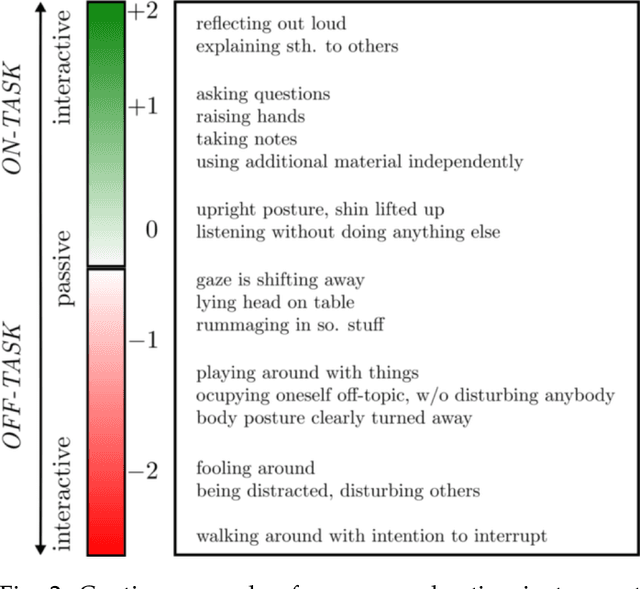
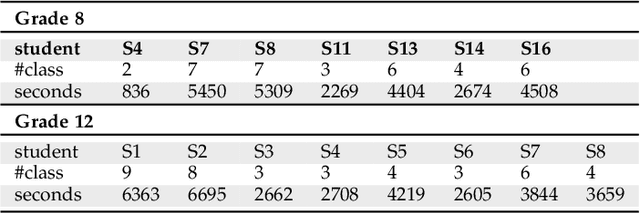
Student engagement is a key construct for learning and teaching. While most of the literature explored the student engagement analysis on computer-based settings, this paper extends that focus to classroom instruction. To best examine student visual engagement in the classroom, we conducted a study utilizing the audiovisual recordings of classes at a secondary school over one and a half month's time, acquired continuous engagement labeling per student (N=15) in repeated sessions, and explored computer vision methods to classify engagement levels from faces in the classroom. We trained deep embeddings for attentional and emotional features, training Attention-Net for head pose estimation and Affect-Net for facial expression recognition. We additionally trained different engagement classifiers, consisting of Support Vector Machines, Random Forest, Multilayer Perceptron, and Long Short-Term Memory, for both features. The best performing engagement classifiers achieved AUCs of .620 and .720 in Grades 8 and 12, respectively. We further investigated fusion strategies and found score-level fusion either improves the engagement classifiers or is on par with the best performing modality. We also investigated the effect of personalization and found that using only 60-seconds of person-specific data selected by margin uncertainty of the base classifier yielded an average AUC improvement of .084. 4.Our main aim with this work is to provide the technical means to facilitate the manual data analysis of classroom videos in research on teaching quality and in the context of teacher training.
Automated Anonymisation of Visual and Audio Data in Classroom Studies
Jan 14, 2020


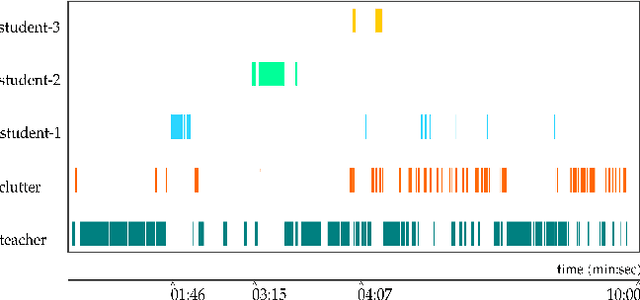
Understanding students' and teachers' verbal and non-verbal behaviours during instruction may help infer valuable information regarding the quality of teaching. In education research, there have been many studies that aim to measure students' attentional focus on learning-related tasks: Based on audio-visual recordings and manual or automated ratings of behaviours of teachers and students. Student data is, however, highly sensitive. Therefore, ensuring high standards of data protection and privacy has the utmost importance in current practices. For example, in the context of teaching management studies, data collection is carried out with the consent of pupils, parents, teachers and school administrations. Nevertheless, there may often be students whose data cannot be used for research purposes. Excluding these students from the classroom is an unnatural intrusion into the organisation of the classroom. A possible solution would be to request permission to record the audio-visual recordings of all students (including those who do not voluntarily participate in the study) and to anonymise their data. Yet, the manual anonymisation of audio-visual data is very demanding. In this study, we examine the use of artificial intelligence methods to automatically anonymise the visual and audio data of a particular person.
Attention Flow: End-to-End Joint Attention Estimation
Jan 12, 2020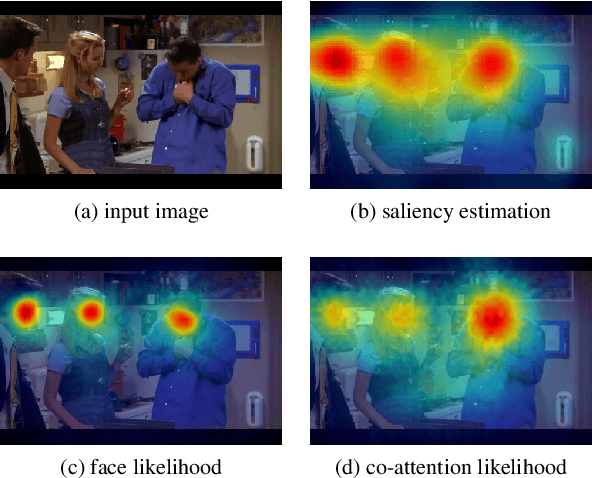



This paper addresses the problem of understanding joint attention in third-person social scene videos. Joint attention is the shared gaze behaviour of two or more individuals on an object or an area of interest and has a wide range of applications such as human-computer interaction, educational assessment, treatment of patients with attention disorders, and many more. Our method, Attention Flow, learns joint attention in an end-to-end fashion by using saliency-augmented attention maps and two novel convolutional attention mechanisms that determine to select relevant features and improve joint attention localization. We compare the effect of saliency maps and attention mechanisms and report quantitative and qualitative results on the detection and localization of joint attention in the VideoCoAtt dataset, which contains complex social scenes.
Teacher's Perception in the Classroom
May 22, 2018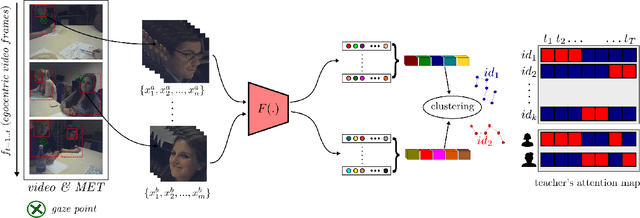
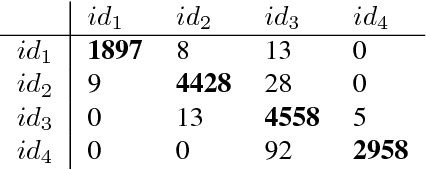

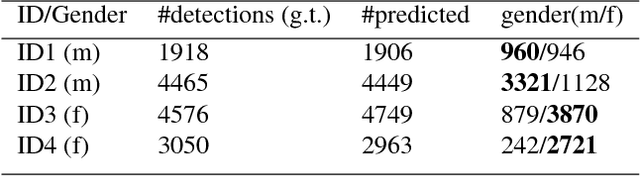
The ability for a teacher to engage all students in active learning processes in classroom constitutes a crucial prerequisite for enhancing students achievement. Teachers' attentional processes provide important insights into teachers' ability to focus their attention on relevant information in the complexity of classroom interaction and distribute their attention across students in order to recognize the relevant needs for learning. In this context, mobile eye tracking is an innovative approach within teaching effectiveness research to capture teachers' attentional processes while teaching. However, analyzing mobile eye-tracking data by hand is time consuming and still limited. In this paper, we introduce a new approach to enhance the impact of mobile eye tracking by connecting it with computer vision. In mobile eye tracking videos from an educational study using a standardized small group situation, we apply a state-ofthe-art face detector, create face tracklets, and introduce a novel method to cluster faces into the number of identity. Subsequently, teachers' attentional focus is calculated per student during a teaching unit by associating eye tracking fixations and face tracklets. To the best of our knowledge, this is the first work to combine computer vision and mobile eye tracking to model teachers' attention while instructing.
Self-supervised Learning of Pose Embeddings from Spatiotemporal Relations in Videos
Aug 07, 2017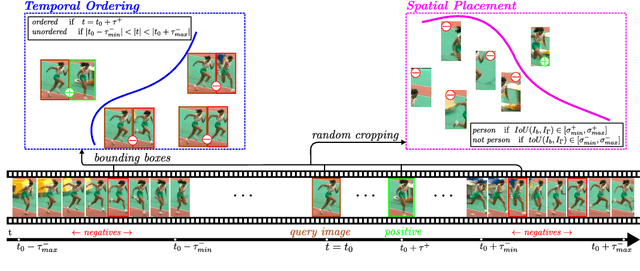
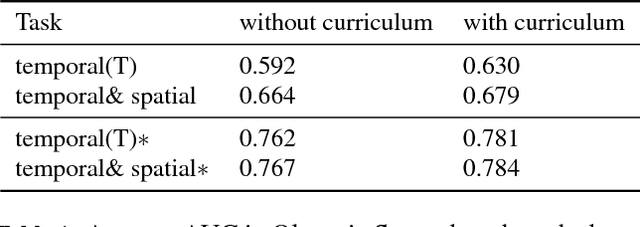
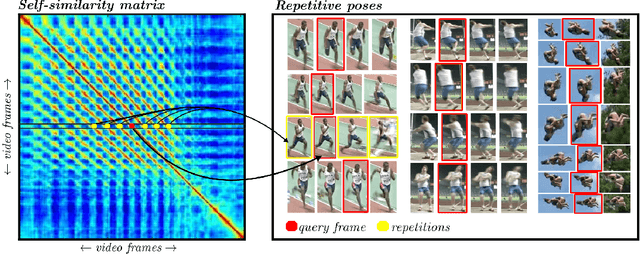
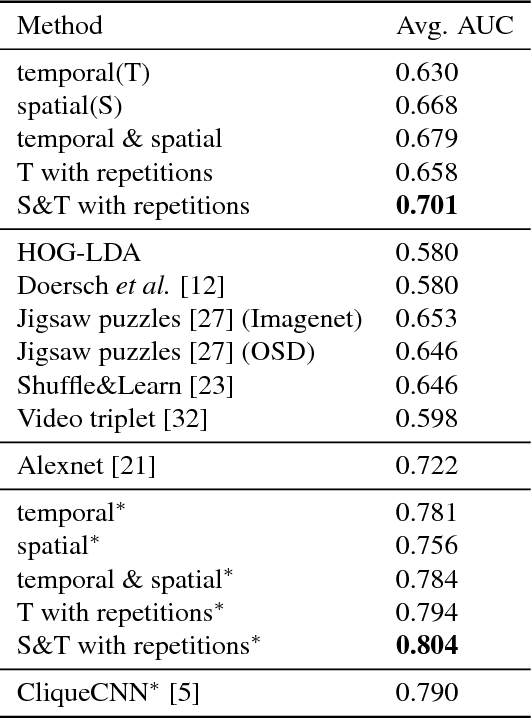
Human pose analysis is presently dominated by deep convolutional networks trained with extensive manual annotations of joint locations and beyond. To avoid the need for expensive labeling, we exploit spatiotemporal relations in training videos for self-supervised learning of pose embeddings. The key idea is to combine temporal ordering and spatial placement estimation as auxiliary tasks for learning pose similarities in a Siamese convolutional network. Since the self-supervised sampling of both tasks from natural videos can result in ambiguous and incorrect training labels, our method employs a curriculum learning idea that starts training with the most reliable data samples and gradually increases the difficulty. To further refine the training process we mine repetitive poses in individual videos which provide reliable labels while removing inconsistencies. Our pose embeddings capture visual characteristics of human pose that can boost existing supervised representations in human pose estimation and retrieval. We report quantitative and qualitative results on these tasks in Olympic Sports, Leeds Pose Sports and MPII Human Pose datasets.