 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Assessment of Classroom Discourse Quality: A Text-Centered Attention-Based Multi-Task Learning Approach
May 12, 2025Classroom discourse is an essential vehicle through which teaching and learning take place. Assessing different characteristics of discursive practices and linking them to student learning achievement enhances the understanding of teaching quality. Traditional assessments rely on manual coding of classroom observation protocols, which is time-consuming and costly. Despite many studies utilizing AI techniques to analyze classroom discourse at the utterance level, investigations into the evaluation of discursive practices throughout an entire lesson segment remain limited. To address this gap, our study proposes a novel text-centered multimodal fusion architecture to assess the quality of three discourse components grounded in the Global Teaching InSights (GTI) observation protocol: Nature of Discourse, Questioning, and Explanations. First, we employ attention mechanisms to capture inter- and intra-modal interactions from transcript, audio, and video streams. Second, a multi-task learning approach is adopted to jointly predict the quality scores of the three components. Third, we formulate the task as an ordinal classification problem to account for rating level order. The effectiveness of these designed elements is demonstrated through an ablation study on the GTI Germany dataset containing 92 videotaped math lessons. Our results highlight the dominant role of text modality in approaching this task. Integrating acoustic features enhances the model's consistency with human ratings, achieving an overall Quadratic Weighted Kappa score of 0.384, comparable to human inter-rater reliability (0.326). Our study lays the groundwork for the future development of automated discourse quality assessment to support teacher professional development through timely feedback on multidimensional discourse practices.
Estimating Presentation Competence using Multimodal Nonverbal Behavioral Cues
May 06, 2021
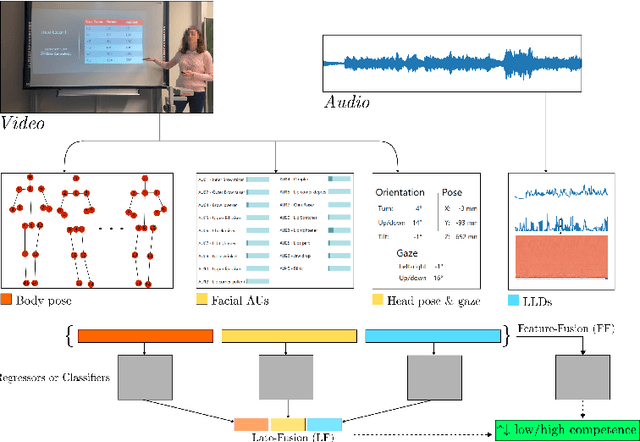

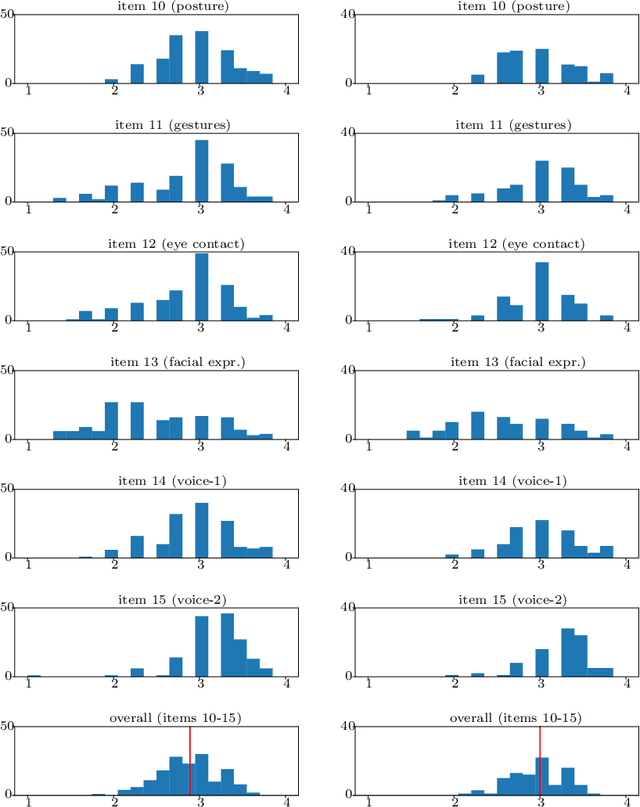
Public speaking and presentation competence plays an essential role in many areas of social interaction in our educational, professional, and everyday life. Since our intention during a speech can differ from what is actually understood by the audience, the ability to appropriately convey our message requires a complex set of skills. Presentation competence is cultivated in the early school years and continuously developed over time. One approach that can promote efficient development of presentation competence is the automated analysis of human behavior during a speech based on visual and audio features and machine learning. Furthermore, this analysis can be used to suggest improvements and the development of skills related to presentation competence. In this work, we investigate the contribution of different nonverbal behavioral cues, namely, facial, body pose-based, and audio-related features, to estimate presentation competence. The analyses were performed on videos of 251 students while the automated assessment is based on manual ratings according to the T\"ubingen Instrument for Presentation Competence (TIP). Our classification results reached the best performance with early fusion in the same dataset evaluation (accuracy of 71.25%) and late fusion of speech, face, and body pose features in the cross dataset evaluation (accuracy of 78.11%). Similarly, regression results performed the best with fusion strategies.
Multimodal Engagement Analysis from Facial Videos in the Classroom
Jan 22, 2021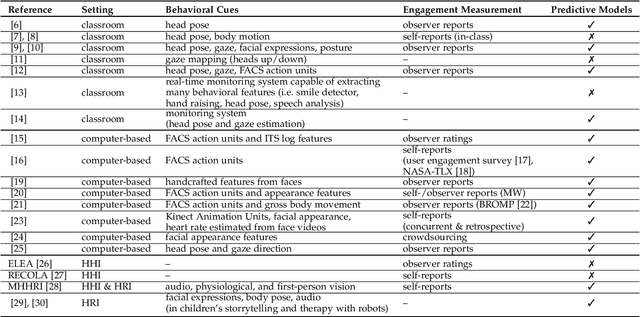
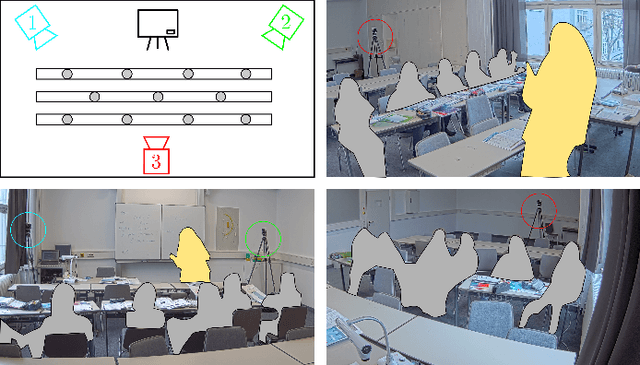
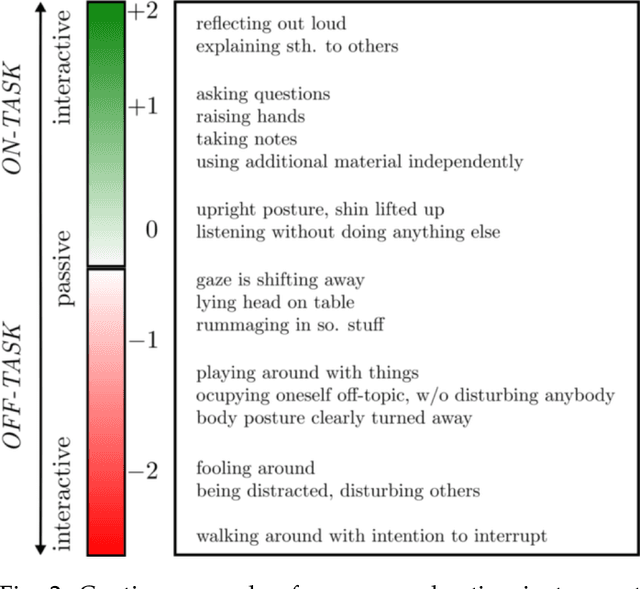
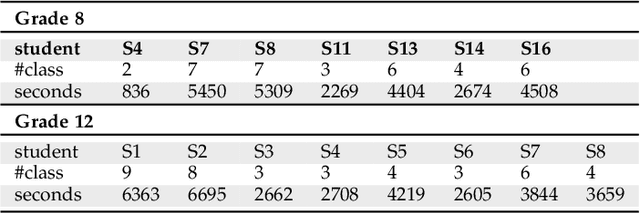
Student engagement is a key construct for learning and teaching. While most of the literature explored the student engagement analysis on computer-based settings, this paper extends that focus to classroom instruction. To best examine student visual engagement in the classroom, we conducted a study utilizing the audiovisual recordings of classes at a secondary school over one and a half month's time, acquired continuous engagement labeling per student (N=15) in repeated sessions, and explored computer vision methods to classify engagement levels from faces in the classroom. We trained deep embeddings for attentional and emotional features, training Attention-Net for head pose estimation and Affect-Net for facial expression recognition. We additionally trained different engagement classifiers, consisting of Support Vector Machines, Random Forest, Multilayer Perceptron, and Long Short-Term Memory, for both features. The best performing engagement classifiers achieved AUCs of .620 and .720 in Grades 8 and 12, respectively. We further investigated fusion strategies and found score-level fusion either improves the engagement classifiers or is on par with the best performing modality. We also investigated the effect of personalization and found that using only 60-seconds of person-specific data selected by margin uncertainty of the base classifier yielded an average AUC improvement of .084. 4.Our main aim with this work is to provide the technical means to facilitate the manual data analysis of classroom videos in research on teaching quality and in the context of teacher training.
Automated Anonymisation of Visual and Audio Data in Classroom Studies
Jan 14, 2020


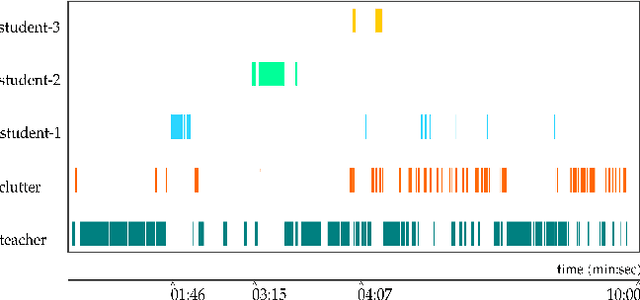
Understanding students' and teachers' verbal and non-verbal behaviours during instruction may help infer valuable information regarding the quality of teaching. In education research, there have been many studies that aim to measure students' attentional focus on learning-related tasks: Based on audio-visual recordings and manual or automated ratings of behaviours of teachers and students. Student data is, however, highly sensitive. Therefore, ensuring high standards of data protection and privacy has the utmost importance in current practices. For example, in the context of teaching management studies, data collection is carried out with the consent of pupils, parents, teachers and school administrations. Nevertheless, there may often be students whose data cannot be used for research purposes. Excluding these students from the classroom is an unnatural intrusion into the organisation of the classroom. A possible solution would be to request permission to record the audio-visual recordings of all students (including those who do not voluntarily participate in the study) and to anonymise their data. Yet, the manual anonymisation of audio-visual data is very demanding. In this study, we examine the use of artificial intelligence methods to automatically anonymise the visual and audio data of a particular person.
Attention Flow: End-to-End Joint Attention Estimation
Jan 12, 2020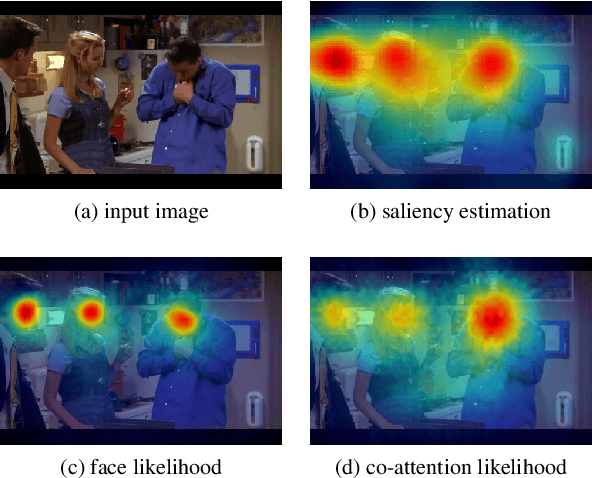



This paper addresses the problem of understanding joint attention in third-person social scene videos. Joint attention is the shared gaze behaviour of two or more individuals on an object or an area of interest and has a wide range of applications such as human-computer interaction, educational assessment, treatment of patients with attention disorders, and many more. Our method, Attention Flow, learns joint attention in an end-to-end fashion by using saliency-augmented attention maps and two novel convolutional attention mechanisms that determine to select relevant features and improve joint attention localization. We compare the effect of saliency maps and attention mechanisms and report quantitative and qualitative results on the detection and localization of joint attention in the VideoCoAtt dataset, which contains complex social scenes.
Teacher's Perception in the Classroom
May 22, 2018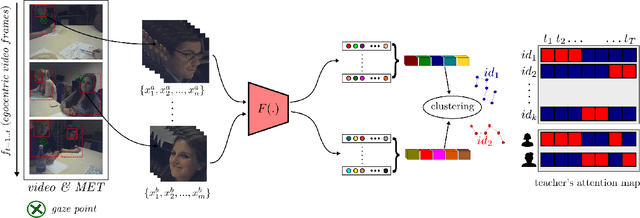
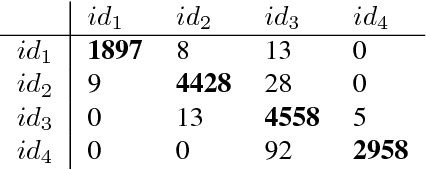

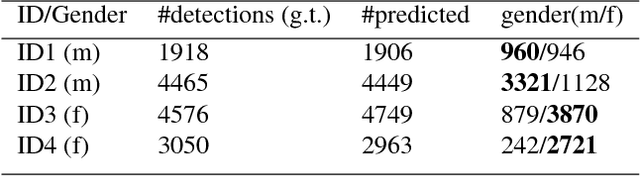
The ability for a teacher to engage all students in active learning processes in classroom constitutes a crucial prerequisite for enhancing students achievement. Teachers' attentional processes provide important insights into teachers' ability to focus their attention on relevant information in the complexity of classroom interaction and distribute their attention across students in order to recognize the relevant needs for learning. In this context, mobile eye tracking is an innovative approach within teaching effectiveness research to capture teachers' attentional processes while teaching. However, analyzing mobile eye-tracking data by hand is time consuming and still limited. In this paper, we introduce a new approach to enhance the impact of mobile eye tracking by connecting it with computer vision. In mobile eye tracking videos from an educational study using a standardized small group situation, we apply a state-ofthe-art face detector, create face tracklets, and introduce a novel method to cluster faces into the number of identity. Subsequently, teachers' attentional focus is calculated per student during a teaching unit by associating eye tracking fixations and face tracklets. To the best of our knowledge, this is the first work to combine computer vision and mobile eye tracking to model teachers' attention while instructing.