 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeguarding Privacy: Privacy-Preserving Detection of Mind Wandering and Disengagement Using Federated Learning in Online Education
Feb 10, 2026Since the COVID-19 pandemic, online courses have expanded access to education, yet the absence of direct instructor support challenges learners' ability to self-regulate attention and engagement. Mind wandering and disengagement can be detrimental to learning outcomes, making their automated detection via video-based indicators a promising approach for real-time learner support. However, machine learning-based approaches often require sharing sensitive data, raising privacy concerns. Federated learning offers a privacy-preserving alternative by enabling decentralized model training while also distributing computational load. We propose a framework exploiting cross-device federated learning to address different manifestations of behavioral and cognitive disengagement during remote learning, specifically behavioral disengagement, mind wandering, and boredom. We fit video-based cognitive disengagement detection models using facial expressions and gaze features. By adopting federated learning, we safeguard users' data privacy through privacy-by-design and introduce a novel solution with the potential for real-time learner support. We further address challenges posed by eyeglasses by incorporating related features, enhancing overall model performance. To validate the performance of our approach, we conduct extensive experiments on five datasets and benchmark multiple federated learning algorithms. Our results show great promise for privacy-preserving educational technologies promoting learner engagement.
Multimodal Assessment of Classroom Discourse Quality: A Text-Centered Attention-Based Multi-Task Learning Approach
May 12, 2025Classroom discourse is an essential vehicle through which teaching and learning take place. Assessing different characteristics of discursive practices and linking them to student learning achievement enhances the understanding of teaching quality. Traditional assessments rely on manual coding of classroom observation protocols, which is time-consuming and costly. Despite many studies utilizing AI techniques to analyze classroom discourse at the utterance level, investigations into the evaluation of discursive practices throughout an entire lesson segment remain limited. To address this gap, our study proposes a novel text-centered multimodal fusion architecture to assess the quality of three discourse components grounded in the Global Teaching InSights (GTI) observation protocol: Nature of Discourse, Questioning, and Explanations. First, we employ attention mechanisms to capture inter- and intra-modal interactions from transcript, audio, and video streams. Second, a multi-task learning approach is adopted to jointly predict the quality scores of the three components. Third, we formulate the task as an ordinal classification problem to account for rating level order. The effectiveness of these designed elements is demonstrated through an ablation study on the GTI Germany dataset containing 92 videotaped math lessons. Our results highlight the dominant role of text modality in approaching this task. Integrating acoustic features enhances the model's consistency with human ratings, achieving an overall Quadratic Weighted Kappa score of 0.384, comparable to human inter-rater reliability (0.326). Our study lays the groundwork for the future development of automated discourse quality assessment to support teacher professional development through timely feedback on multidimensional discourse practices.
Can AI grade your essays? A comparative analysis of large language models and teacher ratings in multidimensional essay scoring
Nov 25, 2024



The manual assessment and grading of student writing is a time-consuming yet critical task for teachers. Recent developments in generative AI, such as large language models, offer potential solutions to facilitate essay-scoring tasks for teachers. In our study, we evaluate the performance and reliability of both open-source and closed-source LLMs in assessing German student essays, comparing their evaluations to those of 37 teachers across 10 pre-defined criteria (i.e., plot logic, expression). A corpus of 20 real-world essays from Year 7 and 8 students was analyzed using five LLMs: GPT-3.5, GPT-4, o1, LLaMA 3-70B, and Mixtral 8x7B, aiming to provide in-depth insights into LLMs' scoring capabilities. Closed-source GPT models outperform open-source models in both internal consistency and alignment with human ratings, particularly excelling in language-related criteria. The novel o1 model outperforms all other LLMs, achieving Spearman's $r = .74$ with human assessments in the overall score, and an internal consistency of $ICC=.80$. These findings indicate that LLM-based assessment can be a useful tool to reduce teacher workload by supporting the evaluation of essays, especially with regard to language-related criteria. However, due to their tendency for higher scores, the models require further refinement to better capture aspects of content quality.
Web Table Classification based on Visual Features
Feb 25, 2021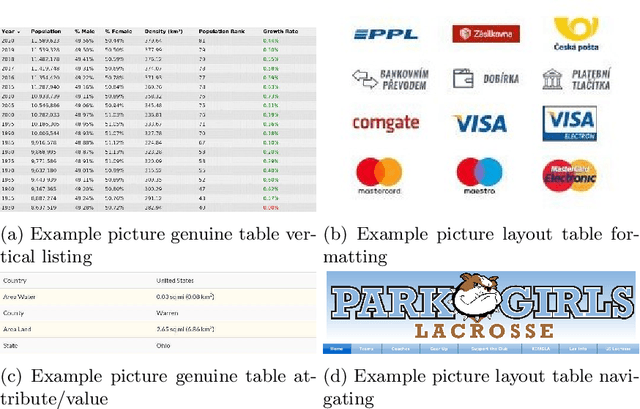
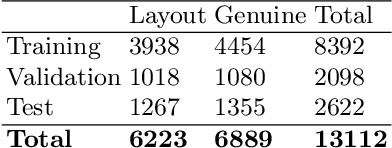
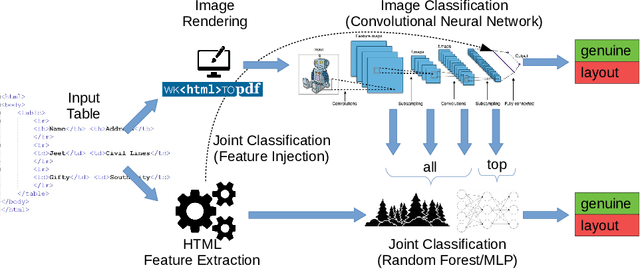

Tables on the web constitute a valuable data source for many applications, like factual search and knowledge base augmentation. However, as genuine tables containing relational knowledge only account for a small proportion of tables on the web, reliable genuine web table classification is a crucial first step of table extraction. Previous works usually rely on explicit feature construction from the HTML code. In contrast, we propose an approach for web table classification by exploiting the full visual appearance of a table, which works purely by applying a convolutional neural network on the rendered image of the web table. Since these visual features can be extracted automatically, our approach circumvents the need for explicit feature construction. A new hand labeled gold standard dataset containing HTML source code and images for 13,112 tables was generated for this task. Transfer learning techniques are applied to well known VGG16 and ResNet50 architectures. The evaluation of CNN image classification with fine tuned ResNet50 (F1 93.29%) shows that this approach achieves results comparable to previous solutions using explicitly defined HTML code based features. By combining visual and explicit features, an F-measure of 93.70% can be achieved by Random Forest classification, which beats current state of the art methods.