 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJournal Impact Factor and Peer Review Thoroughness and Helpfulness: A Supervised Machine Learning Study
Jul 23, 2022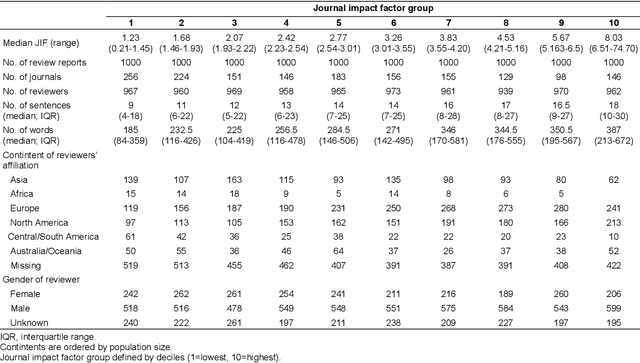
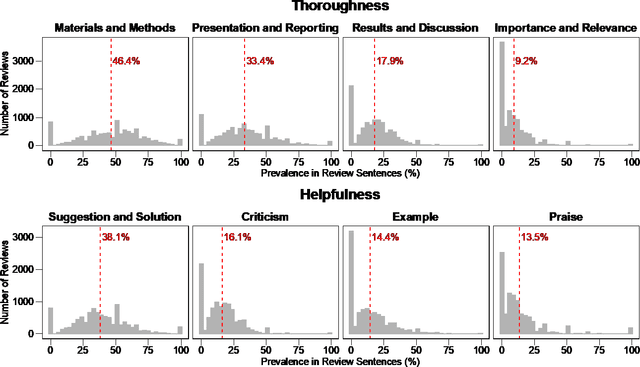
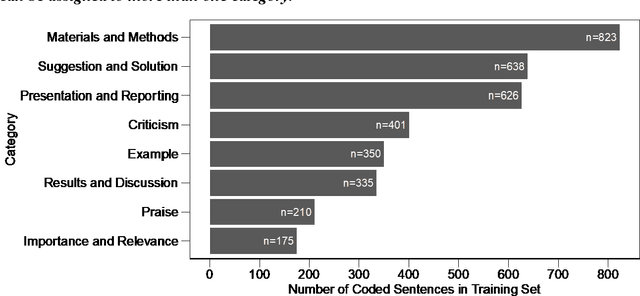
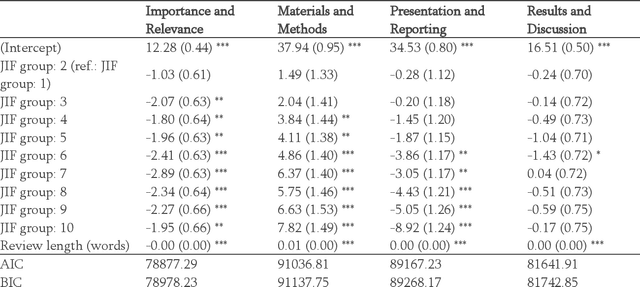
The journal impact factor (JIF) is often equated with journal quality and the quality of the peer review of the papers submitted to the journal. We examined the association between the content of peer review and JIF by analysing 10,000 peer review reports submitted to 1,644 medical and life sciences journals. Two researchers hand-coded a random sample of 2,000 sentences. We then trained machine learning models to classify all 187,240 sentences as contributing or not contributing to content categories. We examined the association between ten groups of journals defined by JIF deciles and the content of peer reviews using linear mixed-effects models, adjusting for the length of the review. The JIF ranged from 0.21 to 74.70. The length of peer reviews increased from the lowest (median number of words 185) to the JIF group (387 words). The proportion of sentences allocated to different content categories varied widely, even within JIF groups. For thoroughness, sentences on 'Materials and Methods' were more common in the highest JIF journals than in the lowest JIF group (difference of 7.8 percentage points; 95% CI 4.9 to 10.7%). The trend for 'Presentation and Reporting' went in the opposite direction, with the highest JIF journals giving less emphasis to such content (difference -8.9%; 95% CI -11.3 to -6.5%). For helpfulness, reviews for higher JIF journals devoted less attention to 'Suggestion and Solution' and provided fewer Examples than lower impact factor journals. No, or only small differences were evident for other content categories. In conclusion, peer review in journals with higher JIF tends to be more thorough in discussing the methods used but less helpful in terms of suggesting solutions and providing examples. Differences were modest and variability high, indicating that the JIF is a bad predictor for the quality of peer review of an individual manuscript.
Go-CaRD -- Generic, Optical Car Part Recognition and Detection: Collection, Insights, and Applications
Jun 15, 2020
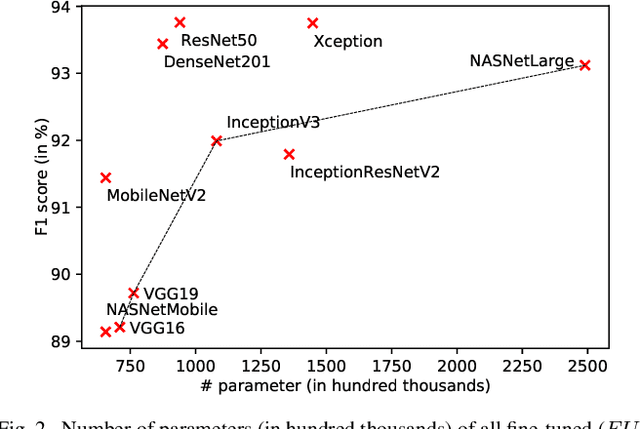

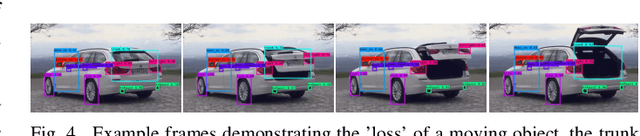
Systems for the automatic recognition and detection of automotive parts are crucial in several emerging research areas in the development of intelligent vehicles. They enable, for example, the detection and modelling of interactions between human and the vehicle. In this paper, we present three suitable datasets as well as quantitatively and qualitatively explore the efficacy of state-of-the-art deep learning architectures for the localisation of 29 interior and exterior vehicle regions, independent of brand, model, and environment. A ResNet50 model achieved an F1 score of 93.67 % for recognition, while our best Darknet model achieved an mAP of 58.20 % for detection. We also experiment with joint and transfer learning approaches and point out potential applications of our systems.
Yet Another Paper about Partial Verb Phrase Fronting in German
May 02, 1996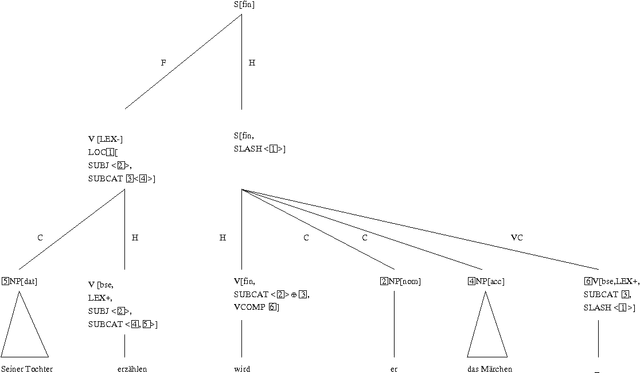
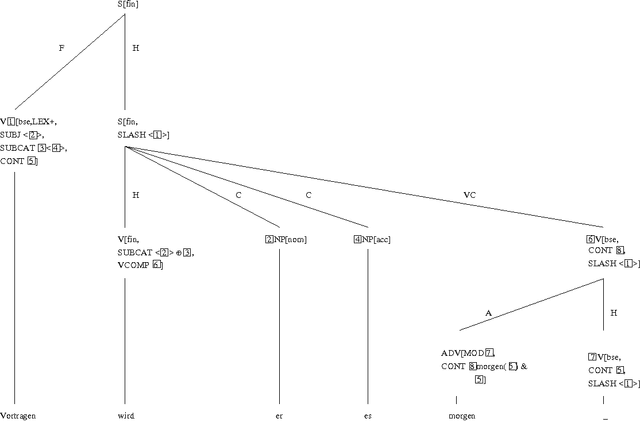
I describe a very simple HPSG analysis for partial verb phrase fronting. I will argue that the presented account is more adequate than others made during the past years because it allows the description of constituents in fronted positions with their modifier remaining in the non-fronted part of the sentence. A problem with ill-formed signs that are admitted by all HPSG accounts for partial verb phrase fronting known so far will be explained and a solution will be suggested that uses the difference between combinatoric relations of signs and their representation in word order domains.