 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIP: DRop unImportant data Points -- Enhancing Machine Learning Efficiency with Grad-CAM-Based Real-Time Data Prioritization for On-Device Training
Apr 11, 2025Selecting data points for model training is critical in machine learning. Effective selection methods can reduce the labeling effort, optimize on-device training for embedded systems with limited data storage, and enhance the model performance. This paper introduces a novel algorithm that uses Grad-CAM to make online decisions about retaining or discarding data points. Optimized for embedded devices, the algorithm computes a unique DRIP Score to quantify the importance of each data point. This enables dynamic decision-making on whether a data point should be stored for potential retraining or discarded without compromising model performance. Experimental evaluations on four benchmark datasets demonstrate that our approach can match or even surpass the accuracy of models trained on the entire dataset, all while achieving storage savings of up to 39\%. To our knowledge, this is the first algorithm that makes online decisions about data point retention without requiring access to the entire dataset.
PerCoV2: Improved Ultra-Low Bit-Rate Perceptual Image Compression with Implicit Hierarchical Masked Image Modeling
Mar 12, 2025We introduce PerCoV2, a novel and open ultra-low bit-rate perceptual image compression system designed for bandwidth- and storage-constrained applications. Building upon prior work by Careil et al., PerCoV2 extends the original formulation to the Stable Diffusion 3 ecosystem and enhances entropy coding efficiency by explicitly modeling the discrete hyper-latent image distribution. To this end, we conduct a comprehensive comparison of recent autoregressive methods (VAR and MaskGIT) for entropy modeling and evaluate our approach on the large-scale MSCOCO-30k benchmark. Compared to previous work, PerCoV2 (i) achieves higher image fidelity at even lower bit-rates while maintaining competitive perceptual quality, (ii) features a hybrid generation mode for further bit-rate savings, and (iii) is built solely on public components. Code and trained models will be released at https://github.com/Nikolai10/PerCoV2.
PerCo (SD): Open Perceptual Compression
Sep 30, 2024



We introduce PerCo (SD), a perceptual image compression method based on Stable Diffusion v2.1, targeting the ultra-low bit range. PerCo (SD) serves as an open and competitive alternative to the state-of-the-art method PerCo, which relies on a proprietary variant of GLIDE and remains closed to the public. In this work, we review the theoretical foundations, discuss key engineering decisions in adapting PerCo to the Stable Diffusion ecosystem, and provide a comprehensive comparison, both quantitatively and qualitatively. On the MSCOCO-30k dataset, PerCo (SD) demonstrates improved perceptual characteristics at the cost of higher distortion. We partly attribute this gap to the different model capacities being used (866M vs. 1.4B). We hope our work contributes to a deeper understanding of the underlying mechanisms and paves the way for future advancements in the field. Code and trained models will be released at https://github.com/Nikolai10/PerCo.
A Continual and Incremental Learning Approach for TinyML On-device Training Using Dataset Distillation and Model Size Adaption
Sep 11, 2024A new algorithm for incremental learning in the context of Tiny Machine learning (TinyML) is presented, which is optimized for low-performance and energy efficient embedded devices. TinyML is an emerging field that deploys machine learning models on resource-constrained devices such as microcontrollers, enabling intelligent applications like voice recognition, anomaly detection, predictive maintenance, and sensor data processing in environments where traditional machine learning models are not feasible. The algorithm solve the challenge of catastrophic forgetting through the use of knowledge distillation to create a small, distilled dataset. The novelty of the method is that the size of the model can be adjusted dynamically, so that the complexity of the model can be adapted to the requirements of the task. This offers a solution for incremental learning in resource-constrained environments, where both model size and computational efficiency are critical factors. Results show that the proposed algorithm offers a promising approach for TinyML incremental learning on embedded devices. The algorithm was tested on five datasets including: CIFAR10, MNIST, CORE50, HAR, Speech Commands. The findings indicated that, despite using only 43% of Floating Point Operations (FLOPs) compared to a larger fixed model, the algorithm experienced a negligible accuracy loss of just 1%. In addition, the presented method is memory efficient. While state-of-the-art incremental learning is usually very memory intensive, the method requires only 1% of the original data set.
Advancing On-Device Neural Network Training with TinyPropv2: Dynamic, Sparse, and Efficient Backpropagation
Sep 11, 2024This study introduces TinyPropv2, an innovative algorithm optimized for on-device learning in deep neural networks, specifically designed for low-power microcontroller units. TinyPropv2 refines sparse backpropagation by dynamically adjusting the level of sparsity, including the ability to selectively skip training steps. This feature significantly lowers computational effort without substantially compromising accuracy. Our comprehensive evaluation across diverse datasets CIFAR 10, CIFAR100, Flower, Food, Speech Command, MNIST, HAR, and DCASE2020 reveals that TinyPropv2 achieves near-parity with full training methods, with an average accuracy drop of only around 1 percent in most cases. For instance, against full training, TinyPropv2's accuracy drop is minimal, for example, only 0.82 percent on CIFAR 10 and 1.07 percent on CIFAR100. In terms of computational effort, TinyPropv2 shows a marked reduction, requiring as little as 10 percent of the computational effort needed for full training in some scenarios, and consistently outperforms other sparse training methodologies. These findings underscore TinyPropv2's capacity to efficiently manage computational resources while maintaining high accuracy, positioning it as an advantageous solution for advanced embedded device applications in the IoT ecosystem.
EGIC: Enhanced Low-Bit-Rate Generative Image Compression Guided by Semantic Segmentation
Sep 06, 2023We introduce EGIC, a novel generative image compression method that allows traversing the distortion-perception curve efficiently from a single model. Specifically, we propose an implicitly encoded variant of image interpolation that predicts the residual between a MSE-optimized and GAN-optimized decoder output. On the receiver side, the user can then control the impact of the residual on the GAN-based reconstruction. Together with improved GAN-based building blocks, EGIC outperforms a wide-variety of perception-oriented and distortion-oriented baselines, including HiFiC, MRIC and DIRAC, while performing almost on par with VTM-20.0 on the distortion end. EGIC is simple to implement, very lightweight (e.g. 0.18x model parameters compared to HiFiC) and provides excellent interpolation characteristics, which makes it a promising candidate for practical applications targeting the low bit range.
TinyProp -- Adaptive Sparse Backpropagation for Efficient TinyML On-device Learning
Aug 17, 2023Training deep neural networks using backpropagation is very memory and computationally intensive. This makes it difficult to run on-device learning or fine-tune neural networks on tiny, embedded devices such as low-power micro-controller units (MCUs). Sparse backpropagation algorithms try to reduce the computational load of on-device learning by training only a subset of the weights and biases. Existing approaches use a static number of weights to train. A poor choice of this so-called backpropagation ratio limits either the computational gain or can lead to severe accuracy losses. In this paper we present TinyProp, the first sparse backpropagation method that dynamically adapts the back-propagation ratio during on-device training for each training step. TinyProp induces a small calculation overhead to sort the elements of the gradient, which does not significantly impact the computational gains. TinyProp works particularly well on fine-tuning trained networks on MCUs, which is a typical use case for embedded applications. For typical datasets from three datasets MNIST, DCASE2020 and CIFAR10, we are 5 times faster compared to non-sparse training with an accuracy loss of on average 1%. On average, TinyProp is 2.9 times faster than existing, static sparse backpropagation algorithms and the accuracy loss is reduced on average by 6 % compared to a typical static setting of the back-propagation ratio.
MLonMCU: TinyML Benchmarking with Fast Retargeting
Jun 15, 2023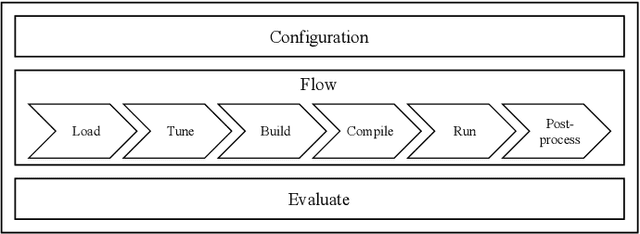



While there exist many ways to deploy machine learning models on microcontrollers, it is non-trivial to choose the optimal combination of frameworks and targets for a given application. Thus, automating the end-to-end benchmarking flow is of high relevance nowadays. A tool called MLonMCU is proposed in this paper and demonstrated by benchmarking the state-of-the-art TinyML frameworks TFLite for Microcontrollers and TVM effortlessly with a large number of configurations in a low amount of time.
Fused Depthwise Tiling for Memory Optimization in TinyML Deep Neural Network Inference
Mar 31, 2023Memory optimization for deep neural network (DNN) inference gains high relevance with the emergence of TinyML, which refers to the deployment of DNN inference tasks on tiny, low-power microcontrollers. Applications such as audio keyword detection or radar-based gesture recognition are heavily constrained by the limited memory on such tiny devices because DNN inference requires large intermediate run-time buffers to store activations and other intermediate data, which leads to high memory usage. In this paper, we propose a new Fused Depthwise Tiling (FDT) method for the memory optimization of DNNs, which, compared to existing tiling methods, reduces memory usage without inducing any run time overhead. FDT applies to a larger variety of network layers than existing tiling methods that focus on convolutions. It improves TinyML memory optimization significantly by reducing memory of models where this was not possible before and additionally providing alternative design points for models that show high run time overhead with existing methods. In order to identify the best tiling configuration, an end-to-end flow with a new path discovery method is proposed, which applies FDT and existing tiling methods in a fully automated way, including the scheduling of the operations and planning of the layout of buffers in memory. Out of seven evaluated models, FDT achieved significant memory reduction for two models by 76.2% and 18.1% where existing tiling methods could not be applied. Two other models showed a significant run time overhead with existing methods and FDT provided alternative design points with no overhead but reduced memory savings.