 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLonMCU: TinyML Benchmarking with Fast Retargeting
Jun 15, 2023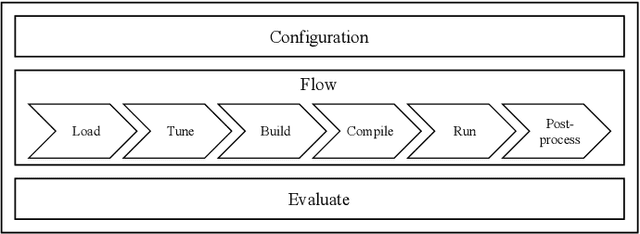



While there exist many ways to deploy machine learning models on microcontrollers, it is non-trivial to choose the optimal combination of frameworks and targets for a given application. Thus, automating the end-to-end benchmarking flow is of high relevance nowadays. A tool called MLonMCU is proposed in this paper and demonstrated by benchmarking the state-of-the-art TinyML frameworks TFLite for Microcontrollers and TVM effortlessly with a large number of configurations in a low amount of time.
Fused Depthwise Tiling for Memory Optimization in TinyML Deep Neural Network Inference
Mar 31, 2023Memory optimization for deep neural network (DNN) inference gains high relevance with the emergence of TinyML, which refers to the deployment of DNN inference tasks on tiny, low-power microcontrollers. Applications such as audio keyword detection or radar-based gesture recognition are heavily constrained by the limited memory on such tiny devices because DNN inference requires large intermediate run-time buffers to store activations and other intermediate data, which leads to high memory usage. In this paper, we propose a new Fused Depthwise Tiling (FDT) method for the memory optimization of DNNs, which, compared to existing tiling methods, reduces memory usage without inducing any run time overhead. FDT applies to a larger variety of network layers than existing tiling methods that focus on convolutions. It improves TinyML memory optimization significantly by reducing memory of models where this was not possible before and additionally providing alternative design points for models that show high run time overhead with existing methods. In order to identify the best tiling configuration, an end-to-end flow with a new path discovery method is proposed, which applies FDT and existing tiling methods in a fully automated way, including the scheduling of the operations and planning of the layout of buffers in memory. Out of seven evaluated models, FDT achieved significant memory reduction for two models by 76.2% and 18.1% where existing tiling methods could not be applied. Two other models showed a significant run time overhead with existing methods and FDT provided alternative design points with no overhead but reduced memory savings.