 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Representation Learning in Speech Processing: Challenges, Recent Advances, and Future Trends
Paper and Code
Jan 02, 2020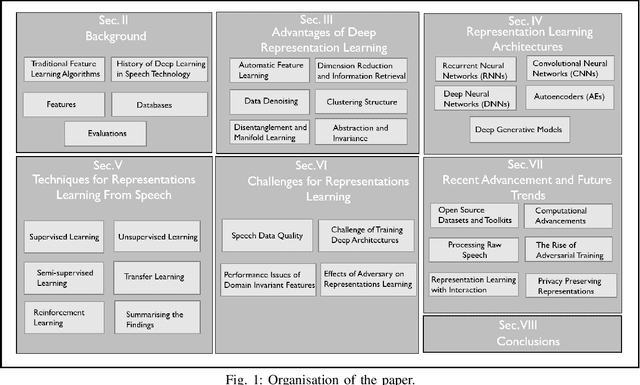
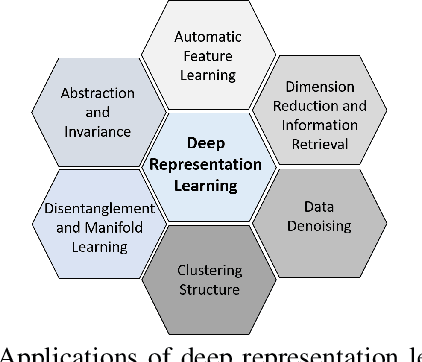
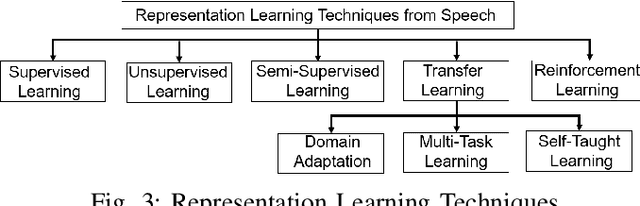
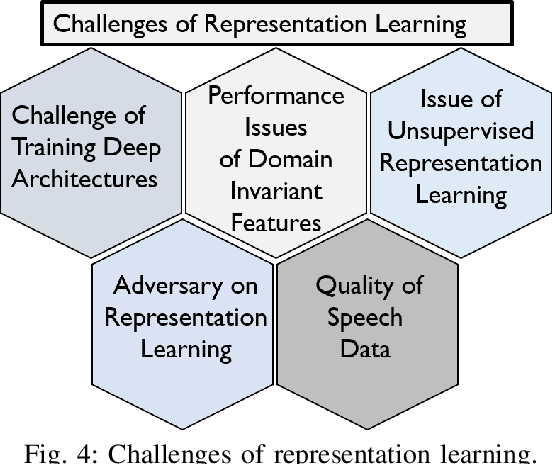
Research on speech processing has traditionally considered the task of designing hand-engineered acoustic features (feature engineering) as a separate distinct problem from the task of designing efficient machine learning (ML) models to make prediction and classification decisions. There are two main drawbacks to this approach: firstly, the feature engineering being manual is cumbersome and requires human knowledge; and secondly, the designed features might not be best for the objective at hand. This has motivated the adoption of a recent trend in speech community towards utilisation of representation learning techniques, which can learn an intermediate representation of the input signal automatically that better suits the task at hand and hence lead to improved performance. The significance of representation learning has increased with advances in deep learning (DL), where the representations are more useful and less dependent on human knowledge, making it very conducive for tasks like classification, prediction, etc. The main contribution of this paper is to present an up-to-date and comprehensive survey on different techniques of speech representation learning by bringing together the scattered research across three distinct research areas including Automatic Speech Recognition (ASR), Speaker Recognition (SR), and Speaker Emotion Recognition (SER). Recent reviews in speech have been conducted for ASR, SR, and SER, however, none of these has focused on the representation learning from speech---a gap that our survey aims to bridge.