 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-comIQ-ZH: A Human-Aligned Dataset and Benchmark for Fine-Grained Evaluation of E-commerce Posters with Chain-of-Thought
Feb 25, 2026Generative AI is widely used to create commercial posters. However, rapid advances in generation have outpaced automated quality assessment. Existing models emphasize generic esthetics or low level distortions and lack the functional criteria required for e-commerce design. It is especially challenging for Chinese content, where complex characters often produce subtle but critical textual artifacts that are overlooked by existing methods. To address this, we introduce E-comIQ-ZH, a framework for evaluating Chinese e-commerce posters. We build the first dataset E-comIQ-18k to feature multi dimensional scores and expert calibrated Chain of Thought (CoT) rationales. Using this dataset, we train E-comIQ-M, a specialized evaluation model that aligns with human expert judgment. Our framework enables E-comIQ-Bench, the first automated and scalable benchmark for the generation of Chinese e-commerce posters. Extensive experiments show our E-comIQ-M aligns more closely with expert standards and enables scalable automated assessment of e-commerce posters. All datasets, models, and evaluation tools will be released to support future research in this area.Code will be available at https://github.com/4mm7/E-comIQ-ZH.
Deeper detection limits in astronomical imaging using self-supervised spatiotemporal denoising
Feb 19, 2026The detection limit of astronomical imaging observations is limited by several noise sources. Some of that noise is correlated between neighbouring image pixels and exposures, so in principle could be learned and corrected. We present an astronomical self-supervised transformer-based denoising algorithm (ASTERIS), that integrates spatiotemporal information across multiple exposures. Benchmarking on mock data indicates that ASTERIS improves detection limits by 1.0 magnitude at 90% completeness and purity, while preserving the point spread function and photometric accuracy. Observational validation using data from the James Webb Space Telescope (JWST) and Subaru telescope identifies previously undetectable features, including low-surface-brightness galaxy structures and gravitationally-lensed arcs. Applied to deep JWST images, ASTERIS identifies three times more redshift > 9 galaxy candidates, with rest-frame ultraviolet luminosity 1.0 magnitude fainter, than previous methods.
Peptide2Mol: A Diffusion Model for Generating Small Molecules as Peptide Mimics for Targeted Protein Binding
Nov 07, 2025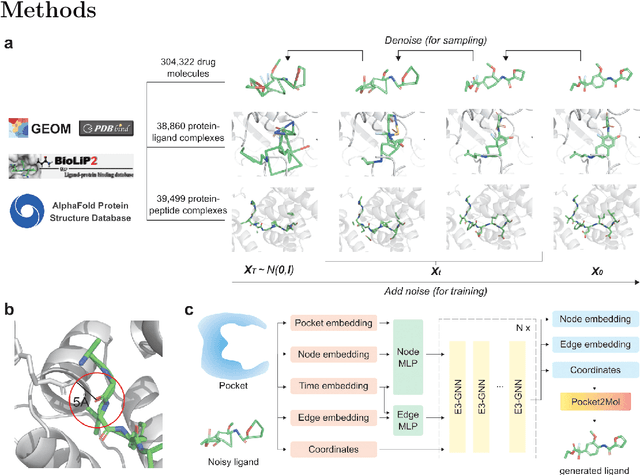
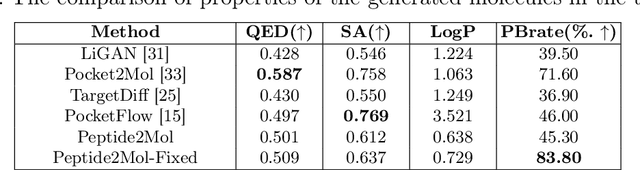
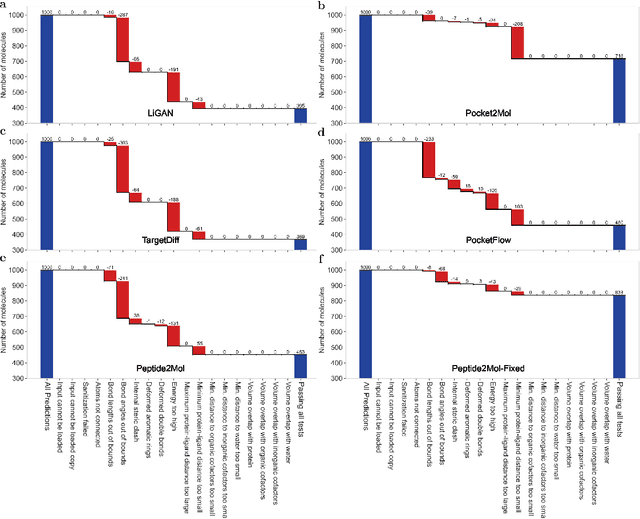
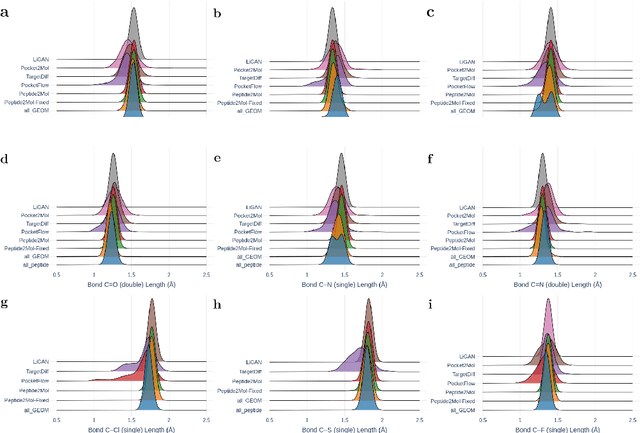
Structure-based drug design has seen significant advancements with the integration of artificial intelligence (AI), particularly in the generation of hit and lead compounds. However, most AI-driven approaches neglect the importance of endogenous protein interactions with peptides, which may result in suboptimal molecule designs. In this work, we present Peptide2Mol, an E(3)-equivariant graph neural network diffusion model that generates small molecules by referencing both the original peptide binders and their surrounding protein pocket environments. Trained on large datasets and leveraging sophisticated modeling techniques, Peptide2Mol not only achieves state-of-the-art performance in non-autoregressive generative tasks, but also produces molecules with similarity to the original peptide binder. Additionally, the model allows for molecule optimization and peptidomimetic design through a partial diffusion process. Our results highlight Peptide2Mol as an effective deep generative model for generating and optimizing bioactive small molecules from protein binding pockets.
A Case for Declarative LLM-friendly Interfaces for Improved Efficiency of Computer-Use Agents
Oct 06, 2025Computer-use agents (CUAs) powered by large language models (LLMs) have emerged as a promising approach to automating computer tasks, yet they struggle with graphical user interfaces (GUIs). GUIs, designed for humans, force LLMs to decompose high-level goals into lengthy, error-prone sequences of fine-grained actions, resulting in low success rates and an excessive number of LLM calls. We propose Goal-Oriented Interface (GOI), a novel abstraction that transforms existing GUIs into three declarative primitives: access, state, and observation, which are better suited for LLMs. Our key idea is policy-mechanism separation: LLMs focus on high-level semantic planning (policy) while GOI handles low-level navigation and interaction (mechanism). GOI does not require modifying the application source code or relying on application programming interfaces (APIs). We evaluate GOI with Microsoft Office Suite (Word, PowerPoint, Excel) on Windows. Compared to a leading GUI-based agent baseline, GOI improves task success rates by 67% and reduces interaction steps by 43.5%. Notably, GOI completes over 61% of successful tasks with a single LLM call.
Communications to Circulations: 3D Wind Field Retrieval and Real-Time Prediction Using 5G GNSS Signals and Deep Learning
Sep 19, 2025



Accurate atmospheric wind field information is crucial for various applications, including weather forecasting, aviation safety, and disaster risk reduction. However, obtaining high spatiotemporal resolution wind data remains challenging due to limitations in traditional in-situ observations and remote sensing techniques, as well as the computational expense and biases of numerical weather prediction (NWP) models. This paper introduces G-WindCast, a novel deep learning framework that leverages signal strength variations from 5G Global Navigation Satellite System (GNSS) signals to retrieve and forecast three-dimensional (3D) atmospheric wind fields. The framework utilizes Forward Neural Networks (FNN) and Transformer networks to capture complex, nonlinear, and spatiotemporal relationships between GNSS-derived features and wind dynamics. Our preliminary results demonstrate promising accuracy in both wind retrieval and short-term wind forecasting (up to 30 minutes lead time), with skill scores comparable to high-resolution NWP outputs in certain scenarios. The model exhibits robustness across different forecast horizons and pressure levels, and its predictions for wind speed and direction show superior agreement with observations compared to concurrent ERA5 reanalysis data. Furthermore, we show that the system can maintain excellent performance for localized forecasting even with a significantly reduced number of GNSS stations (e.g., around 100), highlighting its cost-effectiveness and scalability. This interdisciplinary approach underscores the transformative potential of exploiting non-traditional data sources and deep learning for advanced environmental monitoring and real-time atmospheric applications.
A Survey of Context Engineering for Large Language Models
Jul 17, 2025The performance of Large Language Models (LLMs) is fundamentally determined by the contextual information provided during inference. This survey introduces Context Engineering, a formal discipline that transcends simple prompt design to encompass the systematic optimization of information payloads for LLMs. We present a comprehensive taxonomy decomposing Context Engineering into its foundational components and the sophisticated implementations that integrate them into intelligent systems. We first examine the foundational components: context retrieval and generation, context processing and context management. We then explore how these components are architecturally integrated to create sophisticated system implementations: retrieval-augmented generation (RAG), memory systems and tool-integrated reasoning, and multi-agent systems. Through this systematic analysis of over 1300 research papers, our survey not only establishes a technical roadmap for the field but also reveals a critical research gap: a fundamental asymmetry exists between model capabilities. While current models, augmented by advanced context engineering, demonstrate remarkable proficiency in understanding complex contexts, they exhibit pronounced limitations in generating equally sophisticated, long-form outputs. Addressing this gap is a defining priority for future research. Ultimately, this survey provides a unified framework for both researchers and engineers advancing context-aware AI.
Designing Cyclic Peptides via Harmonic SDE with Atom-Bond Modeling
May 27, 2025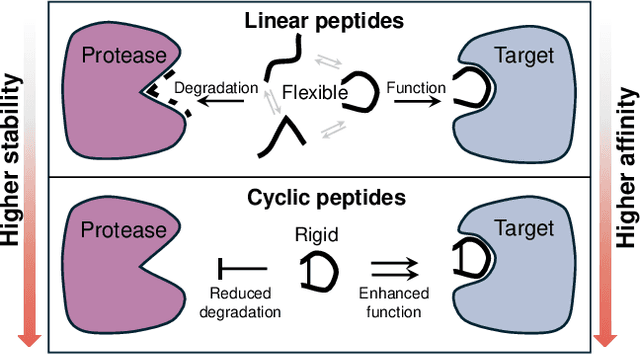
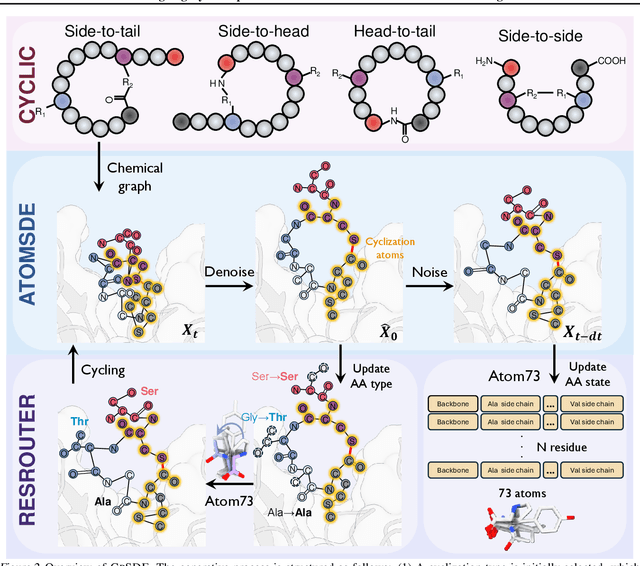
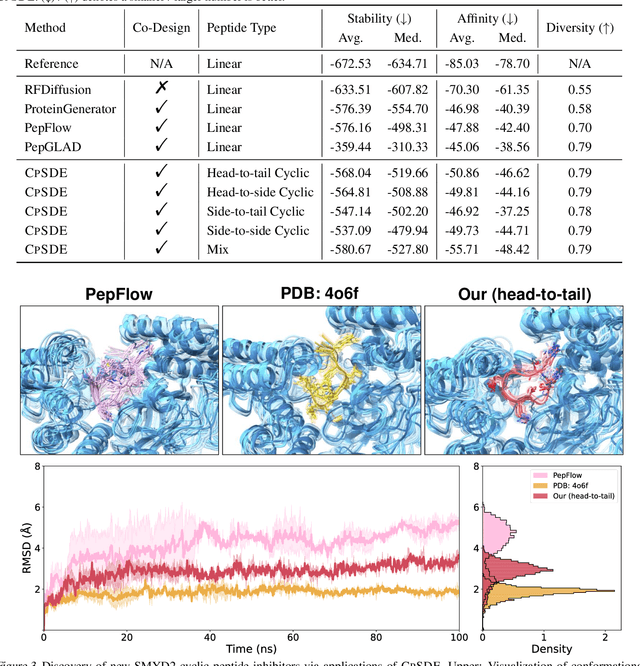
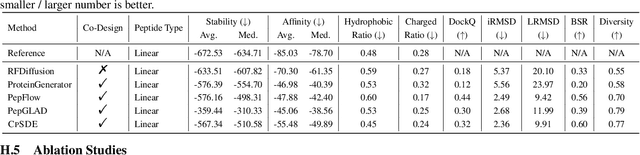
Cyclic peptides offer inherent advantages in pharmaceuticals. For example, cyclic peptides are more resistant to enzymatic hydrolysis compared to linear peptides and usually exhibit excellent stability and affinity. Although deep generative models have achieved great success in linear peptide design, several challenges prevent the development of computational methods for designing diverse types of cyclic peptides. These challenges include the scarcity of 3D structural data on target proteins and associated cyclic peptide ligands, the geometric constraints that cyclization imposes, and the involvement of non-canonical amino acids in cyclization. To address the above challenges, we introduce CpSDE, which consists of two key components: AtomSDE, a generative structure prediction model based on harmonic SDE, and ResRouter, a residue type predictor. Utilizing a routed sampling algorithm that alternates between these two models to iteratively update sequences and structures, CpSDE facilitates the generation of cyclic peptides. By employing explicit all-atom and bond modeling, CpSDE overcomes existing data limitations and is proficient in designing a wide variety of cyclic peptides. Our experimental results demonstrate that the cyclic peptides designed by our method exhibit reliable stability and affinity.
Deciphering the unique dynamic activation pathway in a G protein-coupled receptor enables unveiling biased signaling and identifying cryptic allosteric sites in conformational intermediates
Apr 24, 2025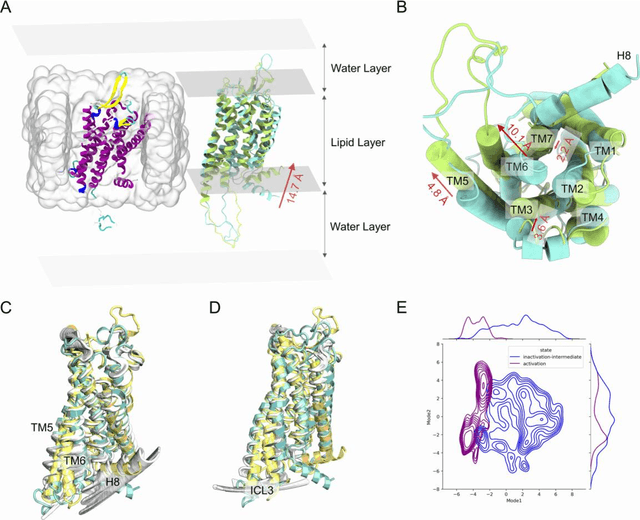
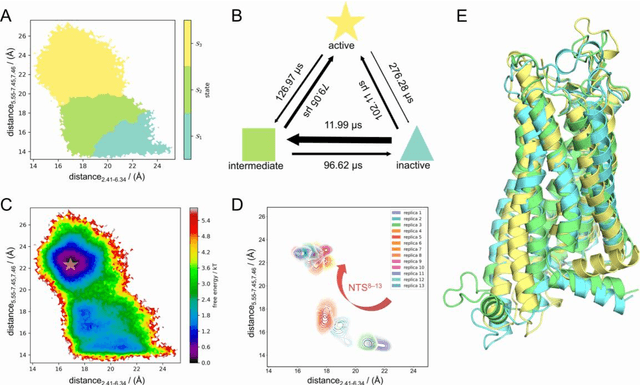
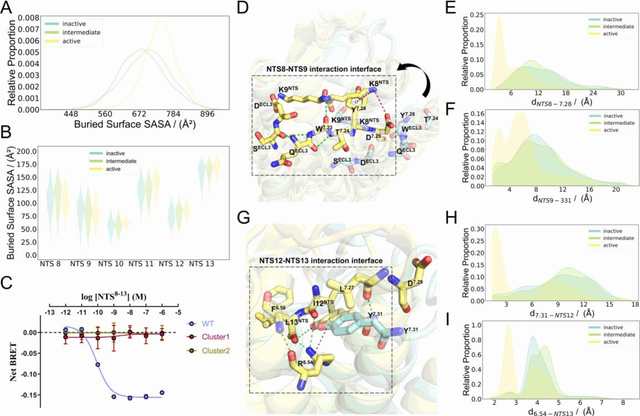
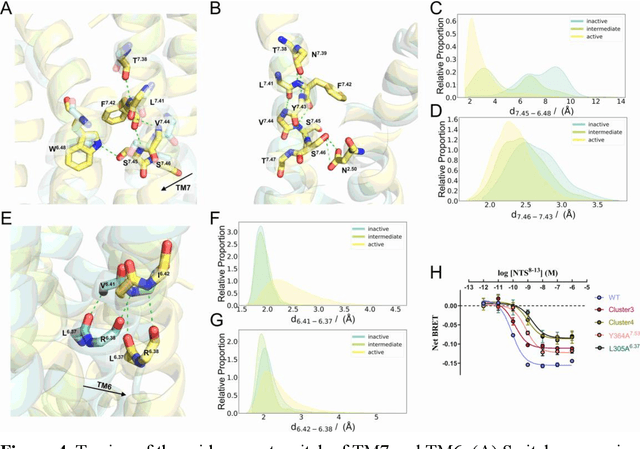
Neurotensin receptor 1 (NTSR1), a member of the Class A G protein-coupled receptor superfamily, plays an important role in modulating dopaminergic neuronal activity and eliciting opioid-independent analgesia. Recent studies suggest that promoting \{beta}-arrestin-biased signaling in NTSR1 may diminish drugs of abuse, such as psychostimulants, thereby offering a potential avenue for treating human addiction-related disorders. In this study, we utilized a novel computational and experimental approach that combined nudged elastic band-based molecular dynamics simulations, Markov state models, temporal communication network analysis, site-directed mutagenesis, and conformational biosensors, to explore the intricate mechanisms underlying NTSR1 activation and biased signaling. Our study reveals a dynamic stepwise transition mechanism and activated transmission network associated with NTSR1 activation. It also yields valuable insights into the complex interplay between the unique polar network, non-conserved ion locks, and aromatic clusters in NTSR1 signaling. Moreover, we identified a cryptic allosteric site located in the intracellular region of the receptor that exists in an intermediate state within the activation pathway. Collectively, these findings contribute to a more profound understanding of NTSR1 activation and biased signaling at the atomic level, thereby providing a potential strategy for the development of NTSR1 allosteric modulators in the realm of G protein-coupled receptor biology, biophysics, and medicine.
PathSeqSAM: Sequential Modeling for Pathology Image Segmentation with SAM2
Apr 12, 2025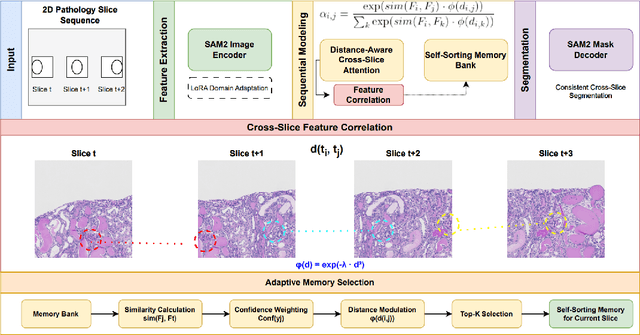
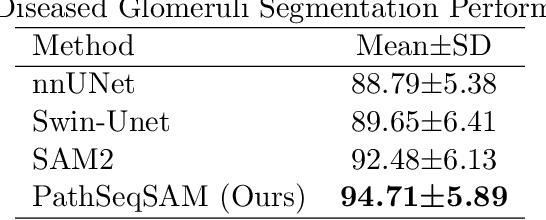
Current methods for pathology image segmentation typically treat 2D slices independently, ignoring valuable cross-slice information. We present PathSeqSAM, a novel approach that treats 2D pathology slices as sequential video frames using SAM2's memory mechanisms. Our method introduces a distance-aware attention mechanism that accounts for variable physical distances between slices and employs LoRA for domain adaptation. Evaluated on the KPI Challenge 2024 dataset for glomeruli segmentation, PathSeqSAM demonstrates improved segmentation quality, particularly in challenging cases that benefit from cross-slice context. We have publicly released our code at https://github.com/JackyyyWang/PathSeqSAM.
F$^3$low: Frame-to-Frame Coarse-grained Molecular Dynamics with SE Guided Flow Matching
May 01, 2024



Molecular dynamics (MD) is a crucial technique for simulating biological systems, enabling the exploration of their dynamic nature and fostering an understanding of their functions and properties. To address exploration inefficiency, emerging enhanced sampling approaches like coarse-graining (CG) and generative models have been employed. In this work, we propose a \underline{Frame-to-Frame} generative model with guided \underline{Flow}-matching (F$3$low) for enhanced sampling, which (a) extends the domain of CG modeling to the SE(3) Riemannian manifold; (b) retreating CGMD simulations as autoregressively sampling guided by the former frame via flow-matching models; (c) targets the protein backbone, offering improved insights into secondary structure formation and intricate folding pathways. Compared to previous methods, F$3$low allows for broader exploration of conformational space. The ability to rapidly generate diverse conformations via force-free generative paradigm on SE(3) paves the way toward efficient enhanced sampling methods.