 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Natural Language Processing
May 22, 2023



Interactive Natural Language Processing (iNLP) has emerged as a novel paradigm within the field of NLP, aimed at addressing limitations in existing frameworks while aligning with the ultimate goals of artificial intelligence. This paradigm considers language models as agents capable of observing, acting, and receiving feedback iteratively from external entities. Specifically, language models in this context can: (1) interact with humans for better understanding and addressing user needs, personalizing responses, aligning with human values, and improving the overall user experience; (2) interact with knowledge bases for enriching language representations with factual knowledge, enhancing the contextual relevance of responses, and dynamically leveraging external information to generate more accurate and informed responses; (3) interact with models and tools for effectively decomposing and addressing complex tasks, leveraging specialized expertise for specific subtasks, and fostering the simulation of social behaviors; and (4) interact with environments for learning grounded representations of language, and effectively tackling embodied tasks such as reasoning, planning, and decision-making in response to environmental observations. This paper offers a comprehensive survey of iNLP, starting by proposing a unified definition and framework of the concept. We then provide a systematic classification of iNLP, dissecting its various components, including interactive objects, interaction interfaces, and interaction methods. We proceed to delve into the evaluation methodologies used in the field, explore its diverse applications, scrutinize its ethical and safety issues, and discuss prospective research directions. This survey serves as an entry point for researchers who are interested in this rapidly evolving area and offers a broad view of the current landscape and future trajectory of iNLP.
1Cademy @ Causal News Corpus 2022: Leveraging Self-Training in Causality Classification of Socio-Political Event Data
Nov 04, 2022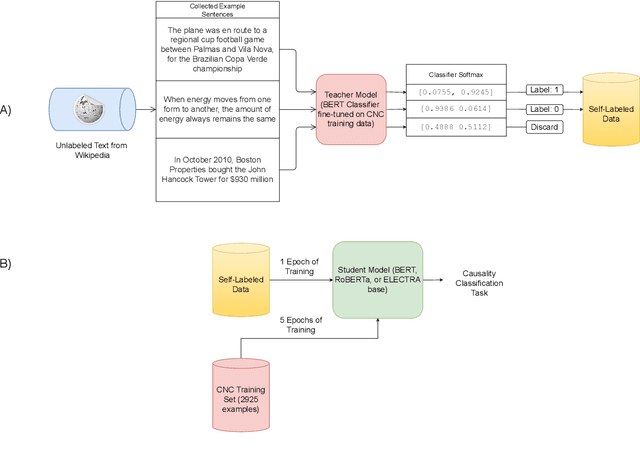
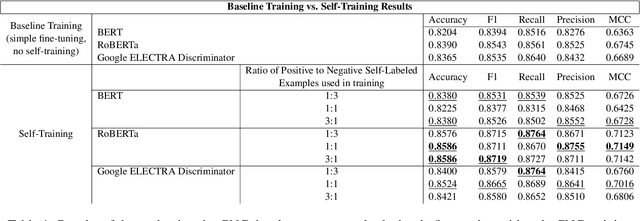
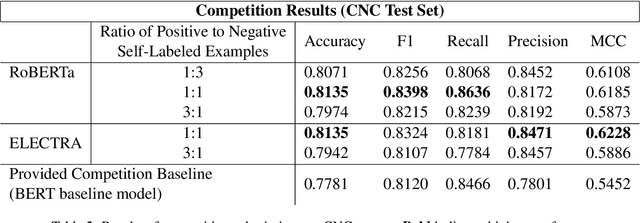
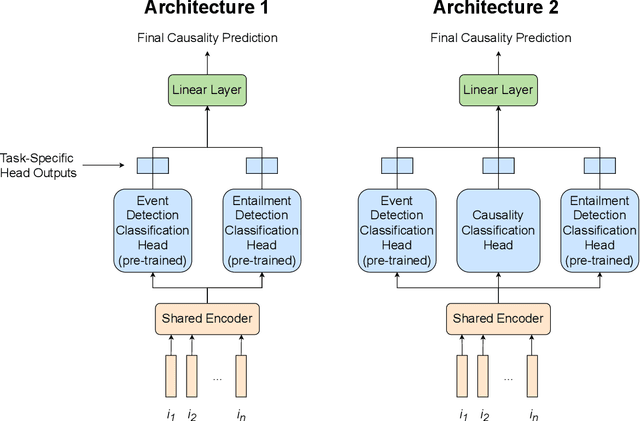
This paper details our participation in the Challenges and Applications of Automated Extraction of Socio-political Events from Text (CASE) workshop @ EMNLP 2022, where we take part in Subtask 1 of Shared Task 3. We approach the given task of event causality detection by proposing a self-training pipeline that follows a teacher-student classifier method. More specifically, we initially train a teacher model on the true, original task data, and use that teacher model to self-label data to be used in the training of a separate student model for the final task prediction. We test how restricting the number of positive or negative self-labeled examples in the self-training process affects classification performance. Our final results show that using self-training produces a comprehensive performance improvement across all models and self-labeled training sets tested within the task of event causality sequence classification. On top of that, we find that self-training performance did not diminish even when restricting either positive/negative examples used in training. Our code is be publicly available at https://github.com/Gzhang-umich/1CademyTeamOfCASE.
1Cademy @ Causal News Corpus 2022: Enhance Causal Span Detection via Beam-Search-based Position Selector
Oct 31, 2022



In this paper, we present our approach and empirical observations for Cause-Effect Signal Span Detection -- Subtask 2 of Shared task 3~\cite{tan-etal-2022-event} at CASE 2022. The shared task aims to extract the cause, effect, and signal spans from a given causal sentence. We model the task as a reading comprehension (RC) problem and apply a token-level RC-based span prediction paradigm to the task as the baseline. We explore different training objectives to fine-tune the model, as well as data augmentation (DA) tricks based on the language model (LM) for performance improvement. Additionally, we propose an efficient beam-search post-processing strategy to due with the drawbacks of span detection to obtain a further performance gain. Our approach achieves an average $F_1$ score of 54.15 and ranks \textbf{$1^{st}$} in the CASE competition. Our code is available at \url{https://github.com/Gzhang-umich/1CademyTeamOfCASE}.