 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Adaptive Composition for Machine Learning as a Service (MLaaS) in IoT Environments
Jun 05, 2026The dynamic nature of Internet of Things (IoT) environments affects the long-term effectiveness of Machine Learning as a Service (MLaaS) compositions. Existing adaptive composition methods are mainly based on service replacement or re-composition, where identifying suitable substitutes is difficult and time-consuming. To address this, we propose a novel Test-Time Adaptive (TTA) composition framework for MLaaS in IoT environments. First, we introduce a TTA-aware composability model to determine whether adapted services remain compatible with the existing composition. Next, we design a service-level adaptation model to adjust individual services during inference while preserving composition performance. Experimental results demonstrate that the proposed framework reduces computational time more effectively than traditional adaptive approaches.
Machine Learning as a Service (MLaaS) Dataset Generator Framework for IoT Environments
Jan 18, 2026We propose a novel MLaaS Dataset Generator (MDG) framework that creates configurable and reproducible datasets for evaluating Machine Learning as a Service (MLaaS) selection and composition. MDG simulates realistic MLaaS behaviour by training and evaluating diverse model families across multiple real-world datasets and data distribution settings. It records detailed functional attributes, quality of service metrics, and composition-specific indicators, enabling systematic analysis of service performance and cross-service behaviour. Using MDG, we generate more than ten thousand MLaaS service instances and construct a large-scale benchmark dataset suitable for downstream evaluation. We also implement a built-in composition mechanism that models how services interact under varied Internet of Things conditions. Experiments demonstrate that datasets generated by MDG enhance selection accuracy and composition quality compared to existing baselines. MDG provides a practical and extensible foundation for advancing data-driven research on MLaaS selection and composition
Tabular foundation model to detect empathy from visual cues
Apr 15, 2025Detecting empathy from video interactions is an emerging area of research. Video datasets, however, are often released as extracted features (i.e., tabular data) rather than raw footage due to privacy and ethical concerns. Prior research on such tabular datasets established tree-based classical machine learning approaches as the best-performing models. Motivated by the recent success of textual foundation models (i.e., large language models), we explore the use of tabular foundation models in empathy detection from tabular visual features. We experiment with two recent tabular foundation models $-$ TabPFN v2 and TabICL $-$ through in-context learning and fine-tuning setups. Our experiments on a public human-robot interaction benchmark demonstrate a significant boost in cross-subject empathy detection accuracy over several strong baselines (accuracy: $0.590 \rightarrow 0.730$; AUC: $0.564 \rightarrow 0.669$). In addition to performance improvement, we contribute novel insights and an evaluation setup to ensure generalisation on unseen subjects in this public benchmark. As the practice of releasing video features as tabular datasets is likely to persist due to privacy constraints, our findings will be widely applicable to future empathy detection video datasets as well.
Reinforcement Learning Controlled Adaptive PSO for Task Offloading in IIoT Edge Computing
Jan 25, 2025


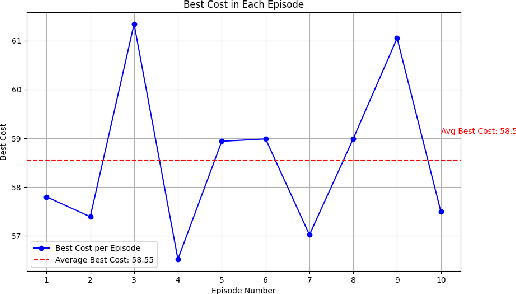
Industrial Internet of Things (IIoT) applications demand efficient task offloading to handle heavy data loads with minimal latency. Mobile Edge Computing (MEC) brings computation closer to devices to reduce latency and server load, optimal performance requires advanced optimization techniques. We propose a novel solution combining Adaptive Particle Swarm Optimization (APSO) with Reinforcement Learning, specifically Soft Actor Critic (SAC), to enhance task offloading decisions in MEC environments. This hybrid approach leverages swarm intelligence and predictive models to adapt to dynamic variables such as human interactions and environmental changes. Our method improves resource management and service quality, achieving optimal task offloading and resource distribution in IIoT edge computing.
Labels Generated by Large Language Model Helps Measuring People's Empathy in Vitro
Jan 01, 2025Large language models (LLMs) have revolutionised numerous fields, with LLM-as-a-service (LLMSaaS) having a strong generalisation ability that offers accessible solutions directly without the need for costly training. In contrast to the widely studied prompt engineering for task solving directly (in vivo), this paper explores its potential in in-vitro applications. These involve using LLM to generate labels to help the supervised training of mainstream models by (1) noisy label correction and (2) training data augmentation with LLM-generated labels. In this paper, we evaluate this approach in the emerging field of empathy computing -- automating the prediction of psychological questionnaire outcomes from inputs like text sequences. Specifically, crowdsourced datasets in this domain often suffer from noisy labels that misrepresent underlying empathy. By leveraging LLM-generated labels to train pre-trained language models (PLMs) like RoBERTa, we achieve statistically significant accuracy improvements over baselines, achieving a state-of-the-art Pearson correlation coefficient of 0.648 on NewsEmp benchmarks. In addition, we bring insightful discussions, including current challenges in empathy computing, data biases in training data and evaluation metric selection. Code and LLM-generated data are available at https://github.com/hasan-rakibul/LLMPathy (available once the paper is accepted).
An Empirical Study on Predictability of Software Code Smell Using Deep Learning Models
Aug 08, 2021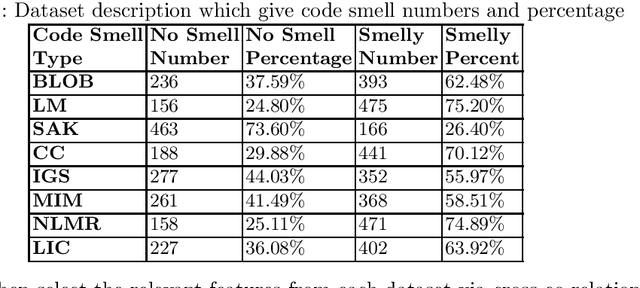
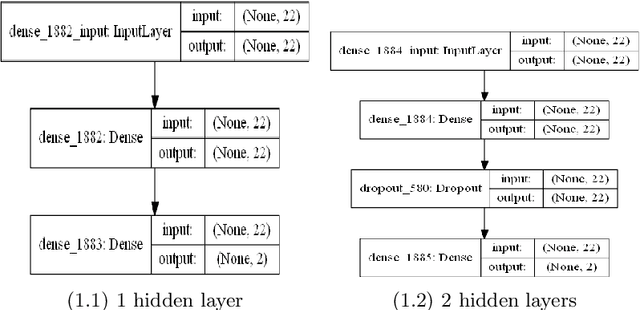


Code Smell, similar to a bad smell, is a surface indication of something tainted but in terms of software writing practices. This metric is an indication of a deeper problem lies within the code and is associated with an issue which is prominent to experienced software developers with acceptable coding practices. Recent studies have often observed that codes having code smells are often prone to a higher probability of change in the software development cycle. In this paper, we developed code smell prediction models with the help of features extracted from source code to predict eight types of code smell. Our work also presents the application of data sampling techniques to handle class imbalance problem and feature selection techniques to find relevant feature sets. Previous studies had made use of techniques such as Naive - Bayes and Random forest but had not explored deep learning methods to predict code smell. A total of 576 distinct Deep Learning models were trained using the features and datasets mentioned above. The study concluded that the deep learning models which used data from Synthetic Minority Oversampling Technique gave better results in terms of accuracy, AUC with the accuracy of some models improving from 88.47 to 96.84.
* 12 pages, 6 Figures, 3 Tables, Accepted in the 35th International Conference on Advanced Information Networking and Applications (AINA-2021)