 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurbo Coded OFDM-OQAM Using Hilbert Transform
Sep 18, 2023Orthogonal frequency division multiplexing (OFDM) with offset quadrature amplitude modulation (OQAM) has been widely discussed in the literature and is considered a popular waveform for 5th generation (5G) wireless telecommunications and beyond. In this work, we show that OFDM-OQAM can be generated using the Hilbert transform and is equivalent to single sideband modulation (SSB), that has roots in analog telecommunications. The transmit filter for OFDM-OQAM is complex valued whose real part is given by the pulse corresponding to the root raised cosine spectrum and the imaginary part is the Hilbert transform of the real part. The real-valued digital information (message) are passed through the transmit filter and frequency division multiplexed on orthogonal subcarriers. The message bandwidth corresponding to each subcarrier is assumed to be narrow enough so that the channel can be considered ideal. Therefore, at the receiver, a matched filter can used to recover the message. Turbo coding is used to achieve bit-error-rate (BER) as low as $10^{-5}$ at an average signal-to-noise ratio (SNR) per bit close to 0 db. The system has been simulated in discrete time.
An Empirical Study on Predictability of Software Code Smell Using Deep Learning Models
Aug 08, 2021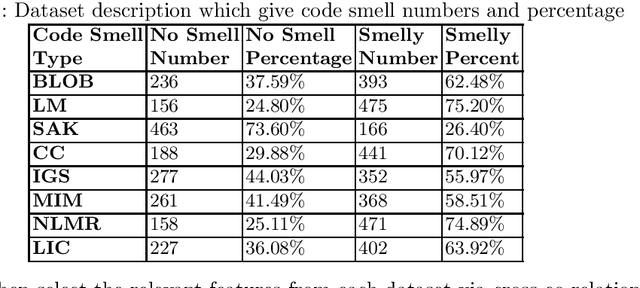


Code Smell, similar to a bad smell, is a surface indication of something tainted but in terms of software writing practices. This metric is an indication of a deeper problem lies within the code and is associated with an issue which is prominent to experienced software developers with acceptable coding practices. Recent studies have often observed that codes having code smells are often prone to a higher probability of change in the software development cycle. In this paper, we developed code smell prediction models with the help of features extracted from source code to predict eight types of code smell. Our work also presents the application of data sampling techniques to handle class imbalance problem and feature selection techniques to find relevant feature sets. Previous studies had made use of techniques such as Naive - Bayes and Random forest but had not explored deep learning methods to predict code smell. A total of 576 distinct Deep Learning models were trained using the features and datasets mentioned above. The study concluded that the deep learning models which used data from Synthetic Minority Oversampling Technique gave better results in terms of accuracy, AUC with the accuracy of some models improving from 88.47 to 96.84.
* 12 pages, 6 Figures, 3 Tables, Accepted in the 35th International Conference on Advanced Information Networking and Applications (AINA-2021)
Empirical Analysis on Effectiveness of NLP Methods for Predicting Code Smell
Aug 08, 2021

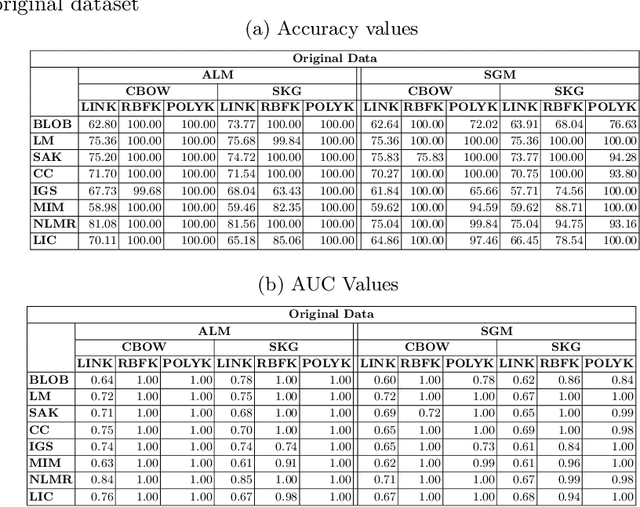
A code smell is a surface indicator of an inherent problem in the system, most often due to deviation from standard coding practices on the developers part during the development phase. Studies observe that code smells made the code more susceptible to call for modifications and corrections than code that did not contain code smells. Restructuring the code at the early stage of development saves the exponentially increasing amount of effort it would require to address the issues stemming from the presence of these code smells. Instead of using traditional features to detect code smells, we use user comments to manually construct features to predict code smells. We use three Extreme learning machine kernels over 629 packages to identify eight code smells by leveraging feature engineering aspects and using sampling techniques. Our findings indicate that the radial basis functional kernel performs best out of the three kernel methods with a mean accuracy of 98.52.