 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-efficient Trajectory Prediction via Coreset Selection
Paper and Code
Sep 25, 2024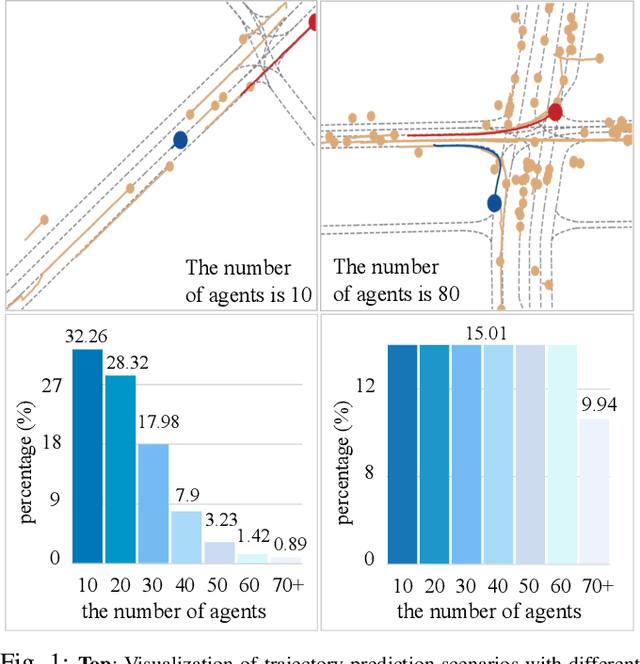
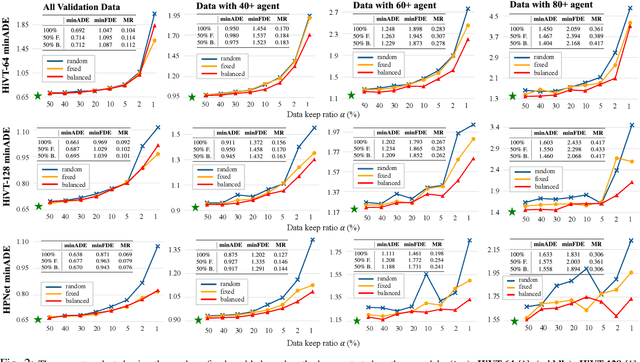
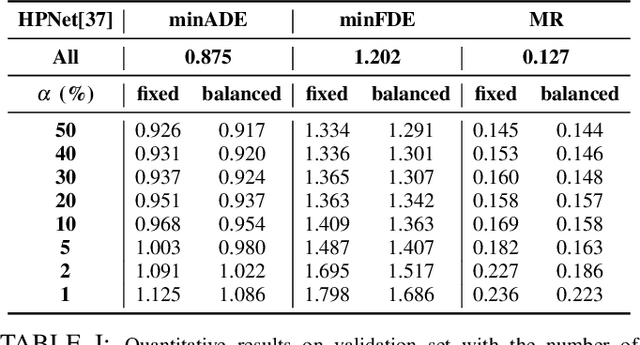
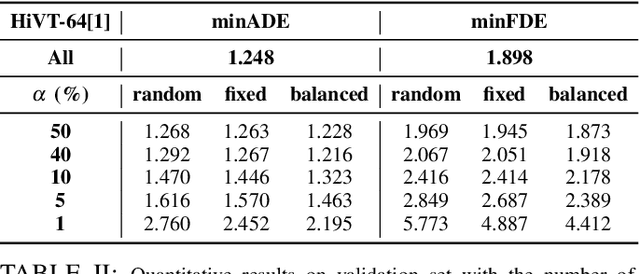
Modern vehicles are equipped with multiple information-collection devices such as sensors and cameras, continuously generating a large volume of raw data. Accurately predicting the trajectories of neighboring vehicles is a vital component in understanding the complex driving environment. Yet, training trajectory prediction models is challenging in two ways. Processing the large-scale data is computation-intensive. Moreover, easy-medium driving scenarios often overwhelmingly dominate the dataset, leaving challenging driving scenarios such as dense traffic under-represented. For example, in the Argoverse motion prediction dataset, there are very few instances with $\ge 50$ agents, while scenarios with $10 \thicksim 20$ agents are far more common. In this paper, to mitigate data redundancy in the over-represented driving scenarios and to reduce the bias rooted in the data scarcity of complex ones, we propose a novel data-efficient training method based on coreset selection. This method strategically selects a small but representative subset of data while balancing the proportions of different scenario difficulties. To the best of our knowledge, we are the first to introduce a method capable of effectively condensing large-scale trajectory dataset, while achieving a state-of-the-art compression ratio. Notably, even when using only 50% of the Argoverse dataset, the model can be trained with little to no decline in performance. Moreover, the selected coreset maintains excellent generalization ability.