 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Convergence Rates of Federated Q-Learning across Heterogeneous Environments
Sep 05, 2024
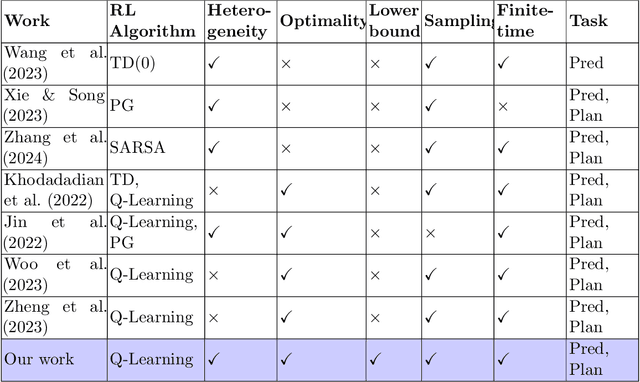
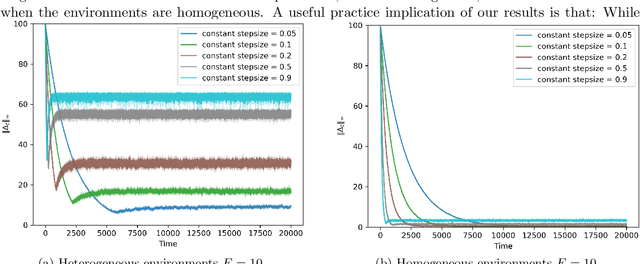

Large-scale multi-agent systems are often deployed across wide geographic areas, where agents interact with heterogeneous environments. There is an emerging interest in understanding the role of heterogeneity in the performance of the federated versions of classic reinforcement learning algorithms. In this paper, we study synchronous federated Q-learning, which aims to learn an optimal Q-function by having $K$ agents average their local Q-estimates per $E$ iterations. We observe an interesting phenomenon on the convergence speeds in terms of $K$ and $E$. Similar to the homogeneous environment settings, there is a linear speed-up concerning $K$ in reducing the errors that arise from sampling randomness. Yet, in sharp contrast to the homogeneous settings, $E>1$ leads to significant performance degradation. Specifically, we provide a fine-grained characterization of the error evolution in the presence of environmental heterogeneity, which decay to zero as the number of iterations $T$ increases. The slow convergence of having $E>1$ turns out to be fundamental rather than an artifact of our analysis. We prove that, for a wide range of stepsizes, the $\ell_{\infty}$ norm of the error cannot decay faster than $\Theta (E/T)$. In addition, our experiments demonstrate that the convergence exhibits an interesting two-phase phenomenon. For any given stepsize, there is a sharp phase-transition of the convergence: the error decays rapidly in the beginning yet later bounces up and stabilizes. Provided that the phase-transition time can be estimated, choosing different stepsizes for the two phases leads to faster overall convergence.