 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElements of Robot Morphology: Supporting Designers in Robot Form Exploration
Feb 09, 2026Robot morphology, the form, shape, and structure of robots, is a key design space in human-robot interaction (HRI), shaping how robots function, express themselves, and interact with people. Yet, despite its importance, little is known about how design frameworks can guide systematic form exploration. To address this gap, we introduce Elements of Robot Morphology, a framework that identifies five fundamental elements: perception, articulation, end effectors, locomotion, and structure. Derived from an analysis of existing robots, the framework supports structured exploration of diverse robot forms. To operationalize the framework, we developed Morphology Exploration Blocks (MEB), a set of tangible blocks that enable hands-on, collaborative experimentation with robot morphologies. We evaluate the framework and toolkit through a case study and design workshops, showing how they support analysis, ideation, reflection, and collaborative robot design.
Do Large Language Models know who did what to whom?
Apr 23, 2025

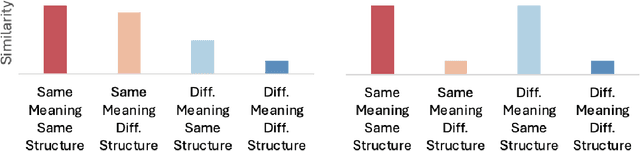

Large Language Models (LLMs) are commonly criticized for not understanding language. However, many critiques focus on cognitive abilities that, in humans, are distinct from language processing. Here, we instead study a kind of understanding tightly linked to language: inferring who did what to whom (thematic roles) in a sentence. Does the central training objective of LLMs-word prediction-result in sentence representations that capture thematic roles? In two experiments, we characterized sentence representations in four LLMs. In contrast to human similarity judgments, in LLMs the overall representational similarity of sentence pairs reflected syntactic similarity but not whether their agent and patient assignments were identical vs. reversed. Furthermore, we found little evidence that thematic role information was available in any subset of hidden units. However, some attention heads robustly captured thematic roles, independently of syntax. Therefore, LLMs can extract thematic roles but, relative to humans, this information influences their representations more weakly.
Building Real-time Awareness of Out-of-distribution in Trajectory Prediction for Autonomous Vehicles
Sep 25, 2024



Trajectory prediction describes the motions of surrounding moving obstacles for an autonomous vehicle; it plays a crucial role in enabling timely decision-making, such as collision avoidance and trajectory replanning. Accurate trajectory planning is the key to reliable vehicle deployments in open-world environment, where unstructured obstacles bring in uncertainties that are impossible to fully capture by training data. For traditional machine learning tasks, such uncertainties are often addressed reasonably well via methods such as continual learning. On the one hand, naively applying those methods to trajectory prediction can result in continuous data collection and frequent model updates, which can be resource-intensive. On the other hand, the predicted trajectories can be far away from the true trajectories, leading to unsafe decision-making. In this paper, we aim to establish real-time awareness of out-of-distribution in trajectory prediction for autonomous vehicles. We focus on the challenging and practically relevant setting where the out-of-distribution is deceptive, that is, the one not easily detectable by human intuition. Drawing on the well-established techniques of sequential analysis, we build real-time awareness of out-of-distribution by monitoring prediction errors using the quickest change point detection (QCD). Our solutions are lightweight and can handle the occurrence of out-of-distribution at any time during trajectory prediction inference. Experimental results on multiple real-world datasets using a benchmark trajectory prediction model demonstrate the effectiveness of our methods.
StressNet: Deep Learning to Predict Stress With Fracture Propagation in Brittle Materials
Nov 20, 2020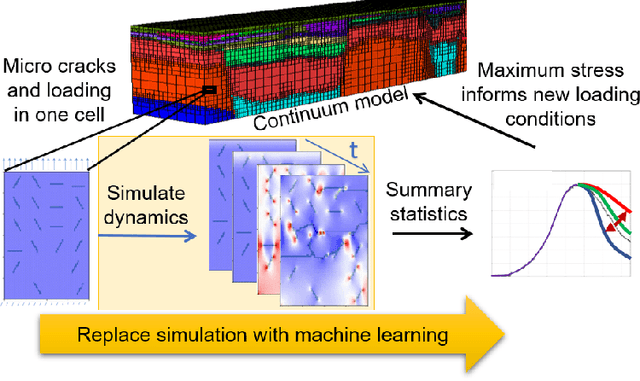

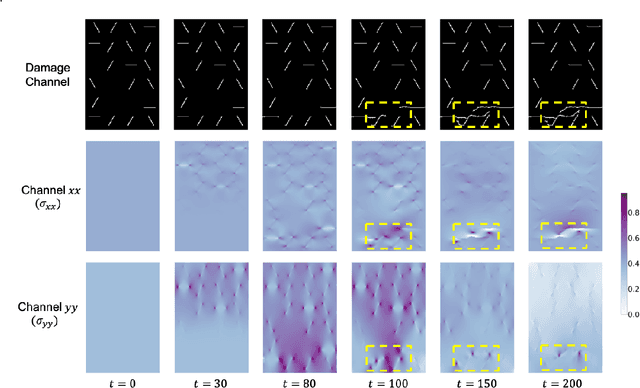

Catastrophic failure in brittle materials is often due to the rapid growth and coalescence of cracks aided by high internal stresses. Hence, accurate prediction of maximum internal stress is critical to predicting time to failure and improving the fracture resistance and reliability of materials. Existing high-fidelity methods, such as the Finite-Discrete Element Model (FDEM), are limited by their high computational cost. Therefore, to reduce computational cost while preserving accuracy, a novel deep learning model, "StressNet," is proposed to predict the entire sequence of maximum internal stress based on fracture propagation and the initial stress data. More specifically, the Temporal Independent Convolutional Neural Network (TI-CNN) is designed to capture the spatial features of fractures like fracture path and spall regions, and the Bidirectional Long Short-term Memory (Bi-LSTM) Network is adapted to capture the temporal features. By fusing these features, the evolution in time of the maximum internal stress can be accurately predicted. Moreover, an adaptive loss function is designed by dynamically integrating the Mean Squared Error (MSE) and the Mean Absolute Percentage Error (MAPE), to reflect the fluctuations in maximum internal stress. After training, the proposed model is able to compute accurate multi-step predictions of maximum internal stress in approximately 20 seconds, as compared to the FDEM run time of 4 hours, with an average MAPE of 2% relative to test data.
CPAC-Conv: CP-decomposition to Approximately Compress Convolutional Layers in Deep Learning
May 28, 2020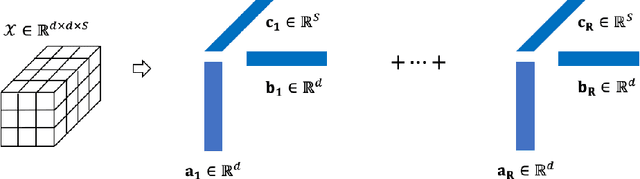

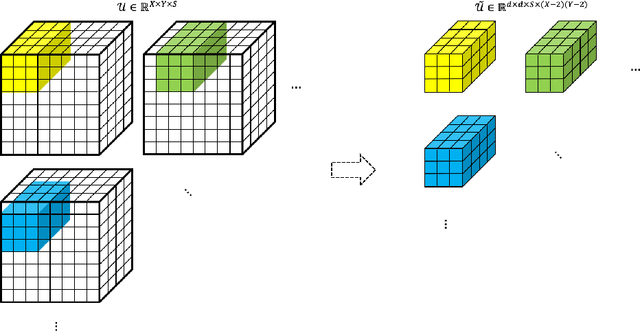
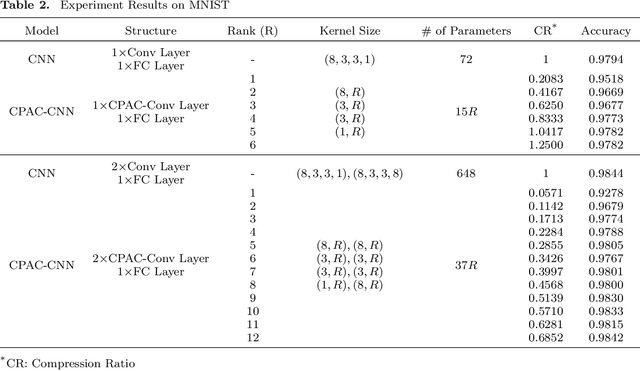
Feature extraction for tensor data serves as an important step in many tasks such as anomaly detection, process monitoring, image classification, and quality control. Although many methods have been proposed for tensor feature extraction, there are still two challenges that need to be addressed: 1) how to reduce the computation cost for high dimensional and large volume tensor data; 2) how to interpret the output features and evaluate their significance. Although the most recent methods in deep learning, such as Convolutional Neural Network (CNN), have shown outstanding performance in analyzing tensor data, their wide adoption is still hindered by model complexity and lack of interpretability. To fill this research gap, we propose to use CP-decomposition to approximately compress the convolutional layer (CPAC-Conv layer) in deep learning. The contributions of our work could be summarized into three aspects: 1) we adapt CP-decomposition to compress convolutional kernels and derive the expressions of both forward and backward propagations for our proposed CPAC-Conv layer; 2) compared with the original convolutional layer, the proposed CPAC-Conv layer can reduce the number of parameters without decaying prediction performance. It can combine with other layers to build novel Neural Networks; 3) the value of decomposed kernels indicates the significance of the corresponding feature map, which increases model interpretability and provides us insights to guide feature selection.
Knowledge Concentration: Learning 100K Object Classifiers in a Single CNN
Nov 23, 2017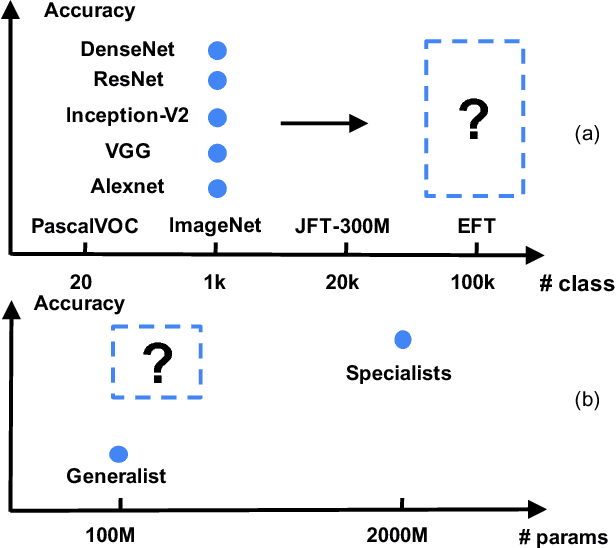

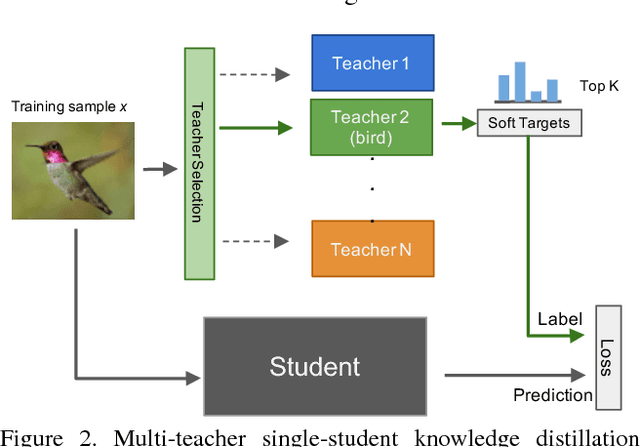

Fine-grained image labels are desirable for many computer vision applications, such as visual search or mobile AI assistant. These applications rely on image classification models that can produce hundreds of thousands (e.g. 100K) of diversified fine-grained image labels on input images. However, training a network at this vocabulary scale is challenging, and suffers from intolerable large model size and slow training speed, which leads to unsatisfying classification performance. A straightforward solution would be training separate expert networks (specialists), with each specialist focusing on learning one specific vertical (e.g. cars, birds...). However, deploying dozens of expert networks in a practical system would significantly increase system complexity and inference latency, and consumes large amounts of computational resources. To address these challenges, we propose a Knowledge Concentration method, which effectively transfers the knowledge from dozens of specialists (multiple teacher networks) into one single model (one student network) to classify 100K object categories. There are three salient aspects in our method: (1) a multi-teacher single-student knowledge distillation framework; (2) a self-paced learning mechanism to allow the student to learn from different teachers at various paces; (3) structurally connected layers to expand the student network capacity with limited extra parameters. We validate our method on OpenImage and a newly collected dataset, Entity-Foto-Tree (EFT), with 100K categories, and show that the proposed model performs significantly better than the baseline generalist model.