 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Concentration: Learning 100K Object Classifiers in a Single CNN
Nov 23, 2017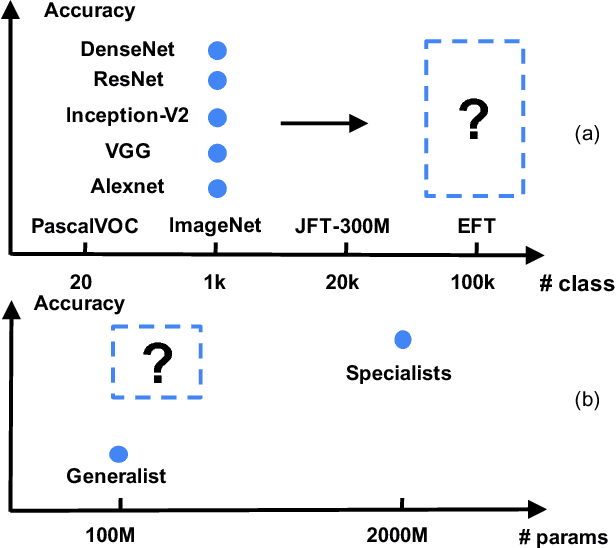

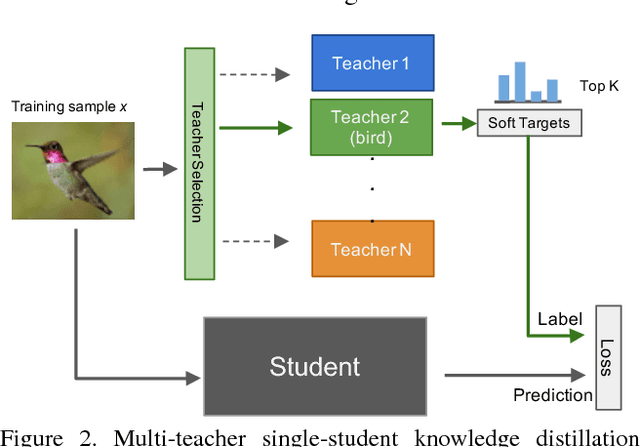

Fine-grained image labels are desirable for many computer vision applications, such as visual search or mobile AI assistant. These applications rely on image classification models that can produce hundreds of thousands (e.g. 100K) of diversified fine-grained image labels on input images. However, training a network at this vocabulary scale is challenging, and suffers from intolerable large model size and slow training speed, which leads to unsatisfying classification performance. A straightforward solution would be training separate expert networks (specialists), with each specialist focusing on learning one specific vertical (e.g. cars, birds...). However, deploying dozens of expert networks in a practical system would significantly increase system complexity and inference latency, and consumes large amounts of computational resources. To address these challenges, we propose a Knowledge Concentration method, which effectively transfers the knowledge from dozens of specialists (multiple teacher networks) into one single model (one student network) to classify 100K object categories. There are three salient aspects in our method: (1) a multi-teacher single-student knowledge distillation framework; (2) a self-paced learning mechanism to allow the student to learn from different teachers at various paces; (3) structurally connected layers to expand the student network capacity with limited extra parameters. We validate our method on OpenImage and a newly collected dataset, Entity-Foto-Tree (EFT), with 100K categories, and show that the proposed model performs significantly better than the baseline generalist model.