 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's the Best Way to Retrieve Slides? A Comparative Study of Multimodal, Caption-Based, and Hybrid Retrieval Techniques
Sep 18, 2025Slide decks, serving as digital reports that bridge the gap between presentation slides and written documents, are a prevalent medium for conveying information in both academic and corporate settings. Their multimodal nature, combining text, images, and charts, presents challenges for retrieval-augmented generation systems, where the quality of retrieval directly impacts downstream performance. Traditional approaches to slide retrieval often involve separate indexing of modalities, which can increase complexity and lose contextual information. This paper investigates various methodologies for effective slide retrieval, including visual late-interaction embedding models like ColPali, the use of visual rerankers, and hybrid retrieval techniques that combine dense retrieval with BM25, further enhanced by textual rerankers and fusion methods like Reciprocal Rank Fusion. A novel Vision-Language Models-based captioning pipeline is also evaluated, demonstrating significantly reduced embedding storage requirements compared to visual late-interaction techniques, alongside comparable retrieval performance. Our analysis extends to the practical aspects of these methods, evaluating their runtime performance and storage demands alongside retrieval efficacy, thus offering practical guidance for the selection and development of efficient and robust slide retrieval systems for real-world applications.
Don't Just Demo, Teach Me the Principles: A Principle-Based Multi-Agent Prompting Strategy for Text Classification
Feb 11, 2025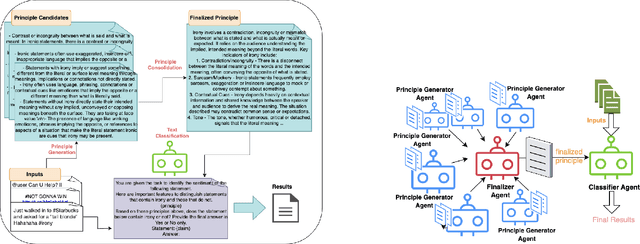
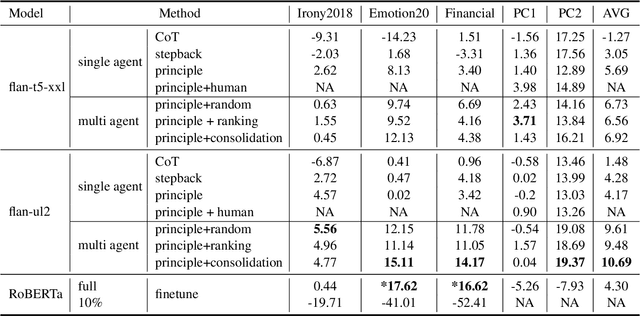
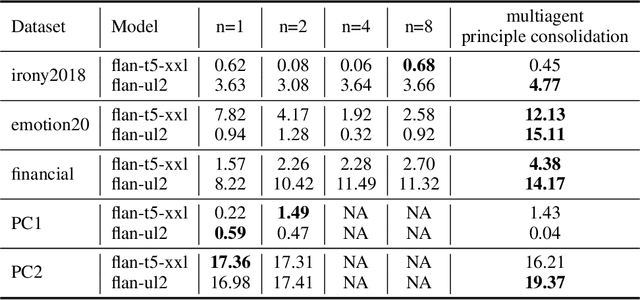
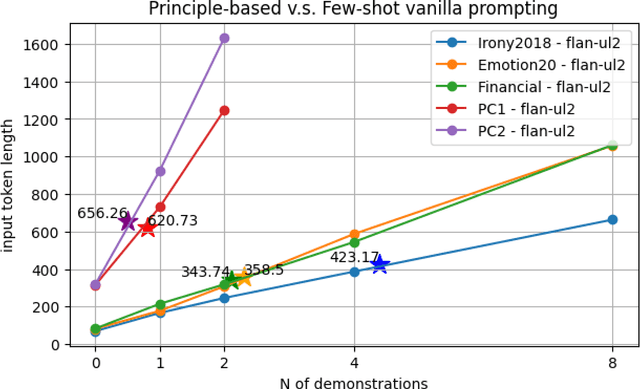
We present PRINCIPLE-BASED PROMPTING, a simple but effective multi-agent prompting strategy for text classification. It first asks multiple LLM agents to independently generate candidate principles based on analysis of demonstration samples with or without labels, consolidates them into final principles via a finalizer agent, and then sends them to a classifier agent to perform downstream classification tasks. Extensive experiments on binary and multi-class classification datasets with different sizes of LLMs show that our approach not only achieves substantial performance gains (1.55% - 19.37%) over zero-shot prompting on macro-F1 score but also outperforms other strong baselines (CoT and stepback prompting). Principles generated by our approach help LLMs perform better on classification tasks than human crafted principles on two private datasets. Our multi-agent PRINCIPLE-BASED PROMPTING approach also shows on-par or better performance compared to demonstration-based few-shot prompting approaches, yet with substantially lower inference costs. Ablation studies show that label information and the multi-agent cooperative LLM framework play an important role in generating high-quality principles to facilitate downstream classification tasks.
Federated Learning Privacy: Attacks, Defenses, Applications, and Policy Landscape - A Survey
May 06, 2024Deep learning has shown incredible potential across a vast array of tasks and accompanying this growth has been an insatiable appetite for data. However, a large amount of data needed for enabling deep learning is stored on personal devices and recent concerns on privacy have further highlighted challenges for accessing such data. As a result, federated learning (FL) has emerged as an important privacy-preserving technology enabling collaborative training of machine learning models without the need to send the raw, potentially sensitive, data to a central server. However, the fundamental premise that sending model updates to a server is privacy-preserving only holds if the updates cannot be "reverse engineered" to infer information about the private training data. It has been shown under a wide variety of settings that this premise for privacy does {\em not} hold. In this survey paper, we provide a comprehensive literature review of the different privacy attacks and defense methods in FL. We identify the current limitations of these attacks and highlight the settings in which FL client privacy can be broken. We dissect some of the successful industry applications of FL and draw lessons for future successful adoption. We survey the emerging landscape of privacy regulation for FL. We conclude with future directions for taking FL toward the cherished goal of generating accurate models while preserving the privacy of the data from its participants.