 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Just Demo, Teach Me the Principles: A Principle-Based Multi-Agent Prompting Strategy for Text Classification
Feb 11, 2025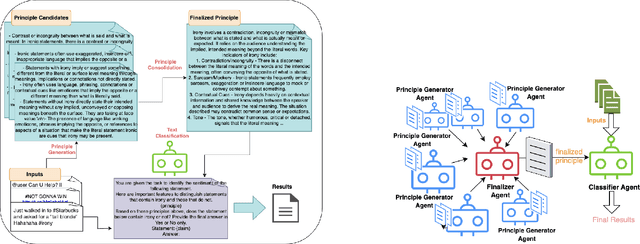
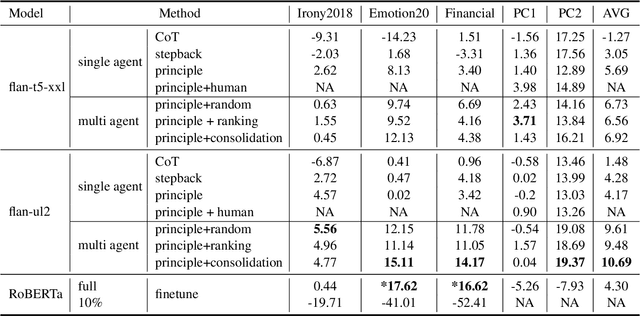
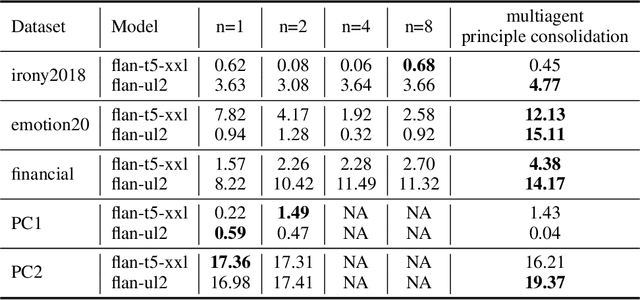
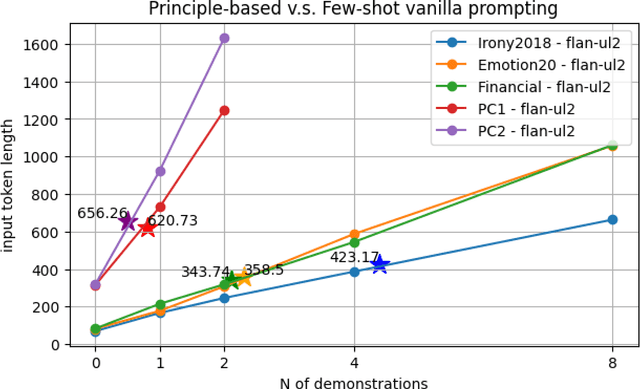
We present PRINCIPLE-BASED PROMPTING, a simple but effective multi-agent prompting strategy for text classification. It first asks multiple LLM agents to independently generate candidate principles based on analysis of demonstration samples with or without labels, consolidates them into final principles via a finalizer agent, and then sends them to a classifier agent to perform downstream classification tasks. Extensive experiments on binary and multi-class classification datasets with different sizes of LLMs show that our approach not only achieves substantial performance gains (1.55% - 19.37%) over zero-shot prompting on macro-F1 score but also outperforms other strong baselines (CoT and stepback prompting). Principles generated by our approach help LLMs perform better on classification tasks than human crafted principles on two private datasets. Our multi-agent PRINCIPLE-BASED PROMPTING approach also shows on-par or better performance compared to demonstration-based few-shot prompting approaches, yet with substantially lower inference costs. Ablation studies show that label information and the multi-agent cooperative LLM framework play an important role in generating high-quality principles to facilitate downstream classification tasks.
NICE: CVPR 2023 Challenge on Zero-shot Image Captioning
Sep 11, 2023



In this report, we introduce NICE (New frontiers for zero-shot Image Captioning Evaluation) project and share the results and outcomes of 2023 challenge. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.
A First Look: Towards Explainable TextVQA Models via Visual and Textual Explanations
Apr 29, 2021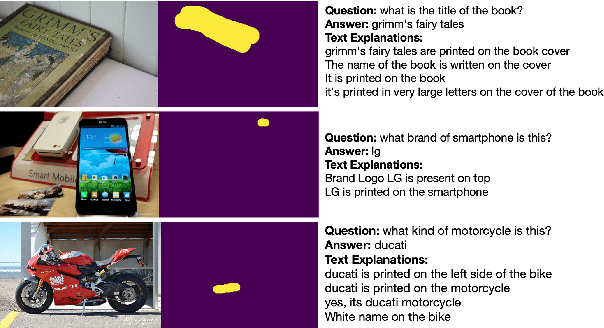
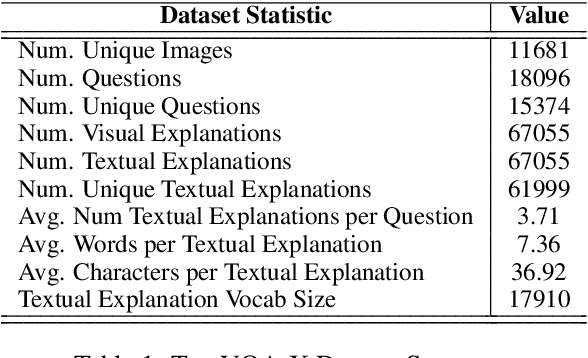
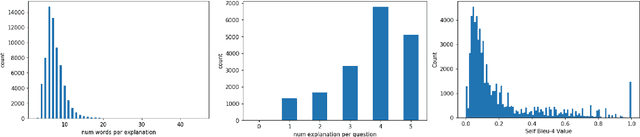
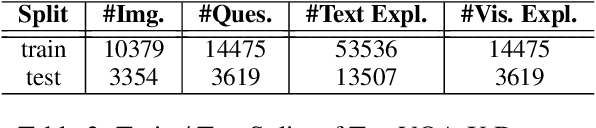
Explainable deep learning models are advantageous in many situations. Prior work mostly provide unimodal explanations through post-hoc approaches not part of the original system design. Explanation mechanisms also ignore useful textual information present in images. In this paper, we propose MTXNet, an end-to-end trainable multimodal architecture to generate multimodal explanations, which focuses on the text in the image. We curate a novel dataset TextVQA-X, containing ground truth visual and multi-reference textual explanations that can be leveraged during both training and evaluation. We then quantitatively show that training with multimodal explanations complements model performance and surpasses unimodal baselines by up to 7% in CIDEr scores and 2% in IoU. More importantly, we demonstrate that the multimodal explanations are consistent with human interpretations, help justify the models' decision, and provide useful insights to help diagnose an incorrect prediction. Finally, we describe a real-world e-commerce application for using the generated multimodal explanations.