 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Dialogue Summarization via Skeleton-Assisted Prompt Transfer
May 20, 2023
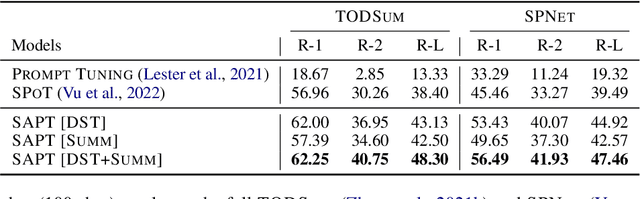
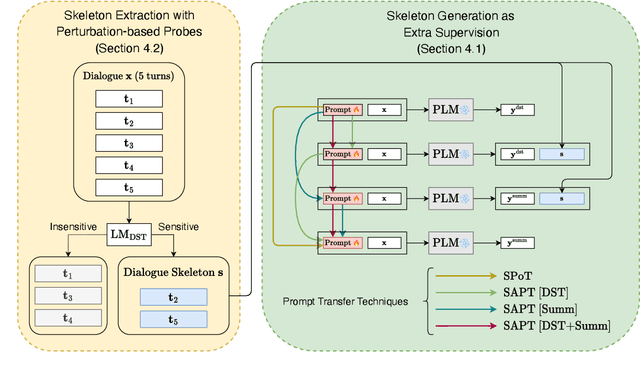
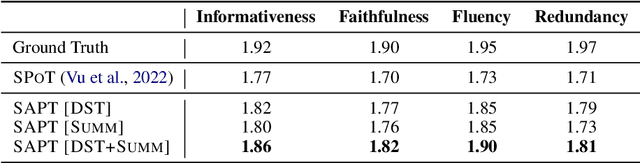
In real-world scenarios, labeled samples for dialogue summarization are usually limited (i.e., few-shot) due to high annotation costs for high-quality dialogue summaries. To efficiently learn from few-shot samples, previous works have utilized massive annotated data from other downstream tasks and then performed prompt transfer in prompt tuning so as to enable cross-task knowledge transfer. However, existing general-purpose prompt transfer techniques lack consideration for dialogue-specific information. In this paper, we focus on improving the prompt transfer from dialogue state tracking to dialogue summarization and propose Skeleton-Assisted Prompt Transfer (SAPT), which leverages skeleton generation as extra supervision that functions as a medium connecting the distinct source and target task and resulting in the model's better consumption of dialogue state information. To automatically extract dialogue skeletons as supervised training data for skeleton generation, we design a novel approach with perturbation-based probes requiring neither annotation effort nor domain knowledge. Training the model on such skeletons can also help preserve model capability during prompt transfer. Our method significantly outperforms existing baselines. In-depth analyses demonstrate the effectiveness of our method in facilitating cross-task knowledge transfer in few-shot dialogue summarization.
Lerna: Transformer Architectures for Configuring Error Correction Tools for Short- and Long-Read Genome Sequencing
Dec 19, 2021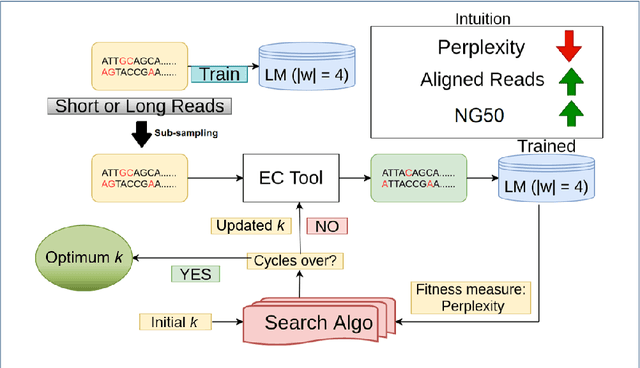
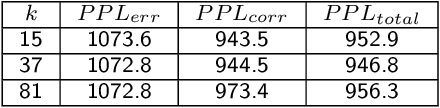
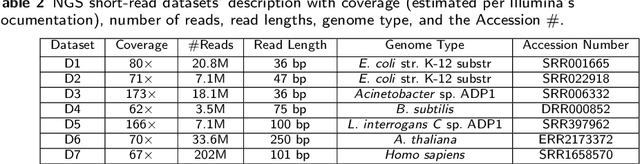
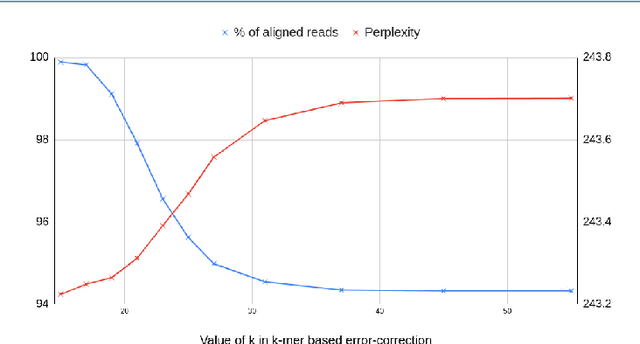
Sequencing technologies are prone to errors, making error correction (EC) necessary for downstream applications. EC tools need to be manually configured for optimal performance. We find that the optimal parameters (e.g., k-mer size) are both tool- and dataset-dependent. Moreover, evaluating the performance (i.e., Alignment-rate or Gain) of a given tool usually relies on a reference genome, but quality reference genomes are not always available. We introduce Lerna for the automated configuration of k-mer-based EC tools. Lerna first creates a language model (LM) of the uncorrected genomic reads; then, calculates the perplexity metric to evaluate the corrected reads for different parameter choices. Next, it finds the one that produces the highest alignment rate without using a reference genome. The fundamental intuition of our approach is that the perplexity metric is inversely correlated with the quality of the assembly after error correction. Results: First, we show that the best k-mer value can vary for different datasets, even for the same EC tool. Second, we show the gains of our LM using its component attention-based transformers. We show the model's estimation of the perplexity metric before and after error correction. The lower the perplexity after correction, the better the k-mer size. We also show that the alignment rate and assembly quality computed for the corrected reads are strongly negatively correlated with the perplexity, enabling the automated selection of k-mer values for better error correction, and hence, improved assembly quality. Additionally, we show that our attention-based models have significant runtime improvement for the entire pipeline -- 18X faster than previous works, due to parallelizing the attention mechanism and the use of JIT compilation for GPU inferencing.
Graph Deep Factors for Forecasting
Oct 14, 2020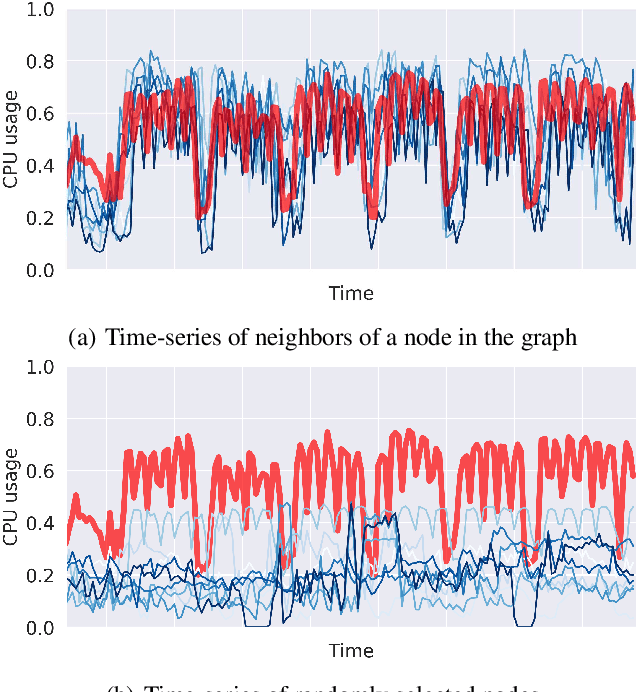
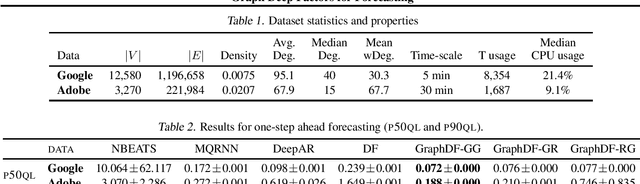

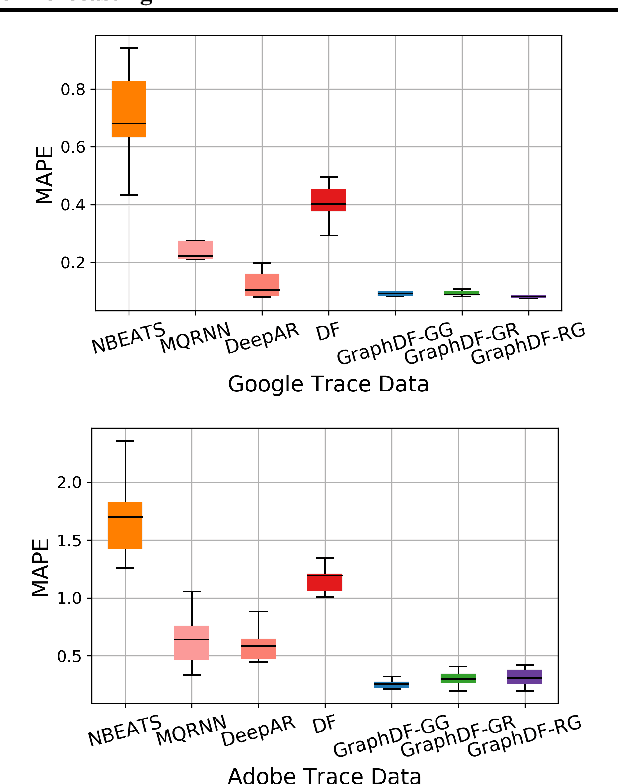
Deep probabilistic forecasting techniques have recently been proposed for modeling large collections of time-series. However, these techniques explicitly assume either complete independence (local model) or complete dependence (global model) between time-series in the collection. This corresponds to the two extreme cases where every time-series is disconnected from every other time-series in the collection or likewise, that every time-series is related to every other time-series resulting in a completely connected graph. In this work, we propose a deep hybrid probabilistic graph-based forecasting framework called Graph Deep Factors (GraphDF) that goes beyond these two extremes by allowing nodes and their time-series to be connected to others in an arbitrary fashion. GraphDF is a hybrid forecasting framework that consists of a relational global and relational local model. In particular, we propose a relational global model that learns complex non-linear time-series patterns globally using the structure of the graph to improve both forecasting accuracy and computational efficiency. Similarly, instead of modeling every time-series independently, we learn a relational local model that not only considers its individual time-series but also the time-series of nodes that are connected in the graph. The experiments demonstrate the effectiveness of the proposed deep hybrid graph-based forecasting model compared to the state-of-the-art methods in terms of its forecasting accuracy, runtime, and scalability. Our case study reveals that GraphDF can successfully generate cloud usage forecasts and opportunistically schedule workloads to increase cloud cluster utilization by 47.5% on average.
A Context Integrated Relational Spatio-Temporal Model for Demand and Supply Forecasting
Sep 25, 2020
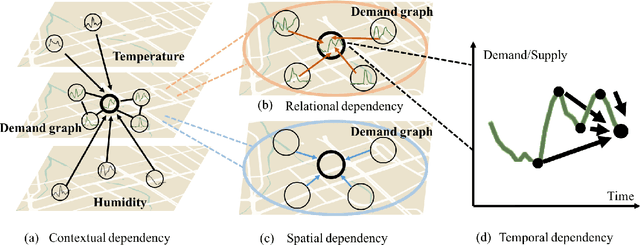

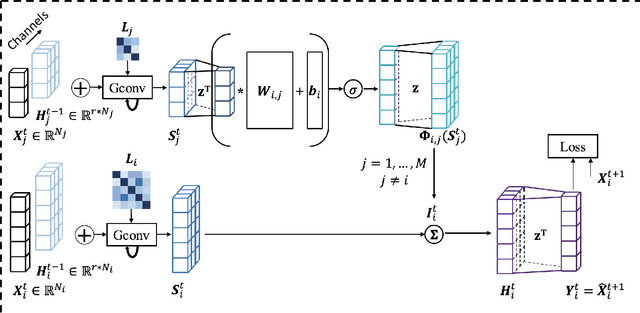
Traditional methods for demand forecasting only focus on modeling the temporal dependency. However, forecasting on spatio-temporal data requires modeling of complex nonlinear relational and spatial dependencies. In addition, dynamic contextual information can have a significant impact on the demand values, and therefore needs to be captured. For example, in a bike-sharing system, bike usage can be impacted by weather. Existing methods assume the contextual impact is fixed. However, we note that the contextual impact evolves over time. We propose a novel context integrated relational model, Context Integrated Graph Neural Network (CIGNN), which leverages the temporal, relational, spatial, and dynamic contextual dependencies for multi-step ahead demand forecasting. Our approach considers the demand network over various geographical locations and represents the network as a graph. We define a demand graph, where nodes represent demand time-series, and context graphs (one for each type of context), where nodes represent contextual time-series. Assuming that various contexts evolve and have a dynamic impact on the fluctuation of demand, our proposed CIGNN model employs a fusion mechanism that jointly learns from all available types of contextual information. To the best of our knowledge, this is the first approach that integrates dynamic contexts with graph neural networks for spatio-temporal demand forecasting, thereby increasing prediction accuracy. We present empirical results on two real-world datasets, demonstrating that CIGNN consistently outperforms state-of-the-art baselines, in both periodic and irregular time-series networks.
Fast Distributed Bandits for Online Recommendation Systems
Jul 16, 2020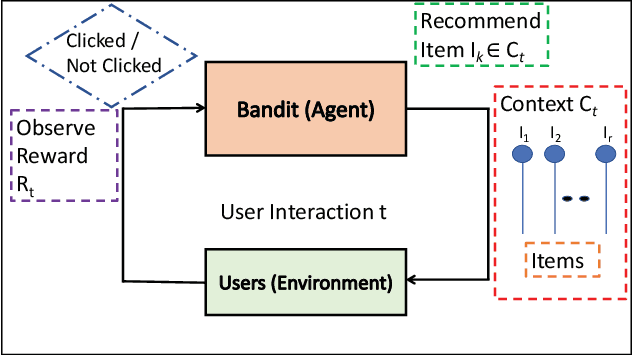
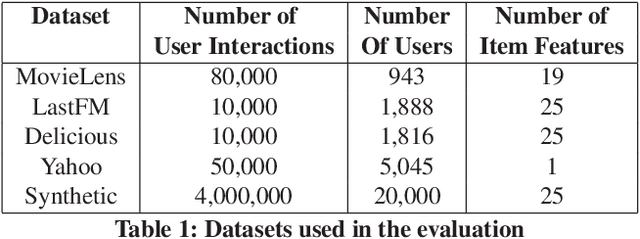
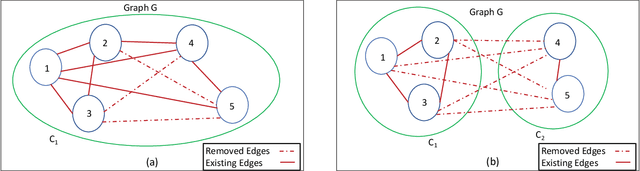
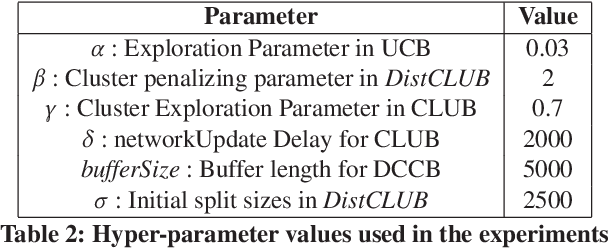
Contextual bandit algorithms are commonly used in recommender systems, where content popularity can change rapidly. These algorithms continuously learn latent mappings between users and items, based on contexts associated with them both. Recent recommendation algorithms that learn clustering or social structures between users have exhibited higher recommendation accuracy. However, as the number of users and items in the environment increases, the time required to generate recommendations deteriorates significantly. As a result, these cannot be deployed in practice. The state-of-the-art distributed bandit algorithm - DCCB - relies on a peer-to-peer net-work to share information among distributed workers. However, this approach does not scale well with the increasing number of users. Furthermore, it suffers from slow discovery of clusters, resulting in accuracy degradation. To address the above issues, this paper proposes a novel distributed bandit-based algorithm called DistCLUB. This algorithm lazily creates clusters in a distributed manner, and dramatically reduces the network data sharing requirement, achieving high scalability. Additionally, DistCLUB finds clusters much faster, achieving better accuracy than the state-of-the-art algorithm. Evaluation over both real-world benchmarks and synthetic datasets shows that DistCLUB is on average 8.87x faster than DCCB, and achieves 14.5% higher normalized prediction performance.