 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLerna: Transformer Architectures for Configuring Error Correction Tools for Short- and Long-Read Genome Sequencing
Dec 19, 2021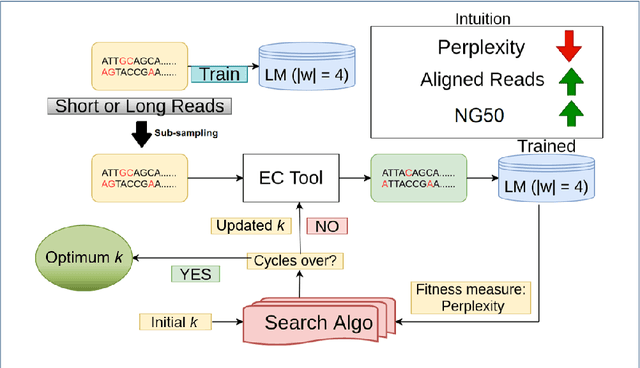
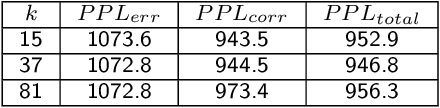
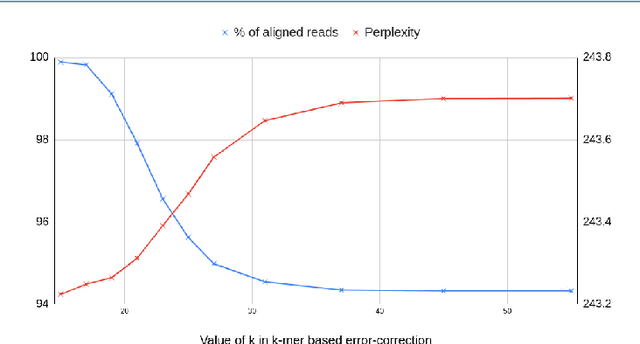
Sequencing technologies are prone to errors, making error correction (EC) necessary for downstream applications. EC tools need to be manually configured for optimal performance. We find that the optimal parameters (e.g., k-mer size) are both tool- and dataset-dependent. Moreover, evaluating the performance (i.e., Alignment-rate or Gain) of a given tool usually relies on a reference genome, but quality reference genomes are not always available. We introduce Lerna for the automated configuration of k-mer-based EC tools. Lerna first creates a language model (LM) of the uncorrected genomic reads; then, calculates the perplexity metric to evaluate the corrected reads for different parameter choices. Next, it finds the one that produces the highest alignment rate without using a reference genome. The fundamental intuition of our approach is that the perplexity metric is inversely correlated with the quality of the assembly after error correction. Results: First, we show that the best k-mer value can vary for different datasets, even for the same EC tool. Second, we show the gains of our LM using its component attention-based transformers. We show the model's estimation of the perplexity metric before and after error correction. The lower the perplexity after correction, the better the k-mer size. We also show that the alignment rate and assembly quality computed for the corrected reads are strongly negatively correlated with the perplexity, enabling the automated selection of k-mer values for better error correction, and hence, improved assembly quality. Additionally, we show that our attention-based models have significant runtime improvement for the entire pipeline -- 18X faster than previous works, due to parallelizing the attention mechanism and the use of JIT compilation for GPU inferencing.
Federated Action Recognition on Heterogeneous Embedded Devices
Jul 18, 2021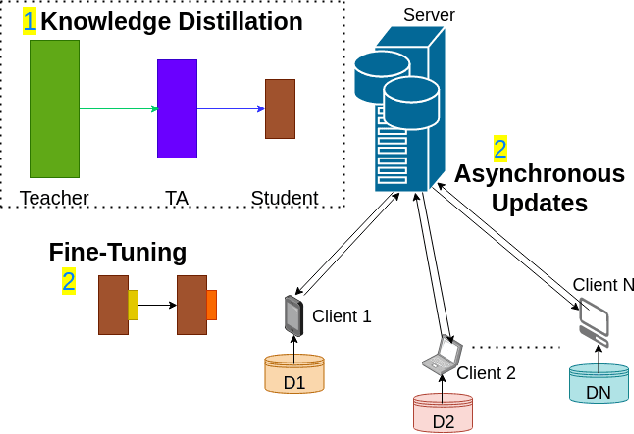
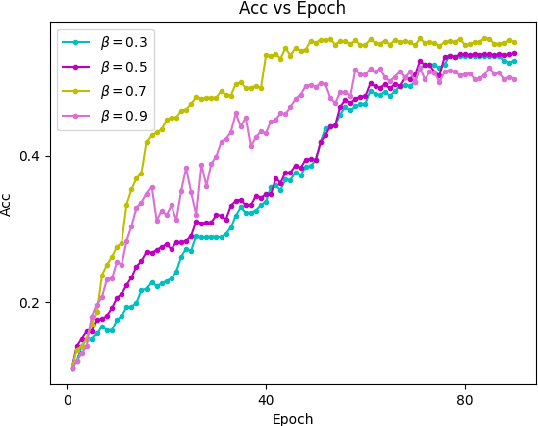
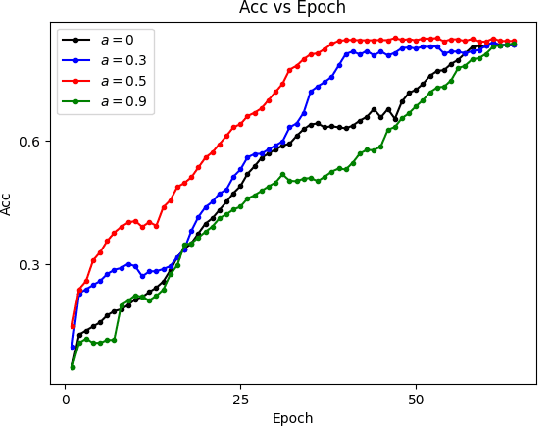
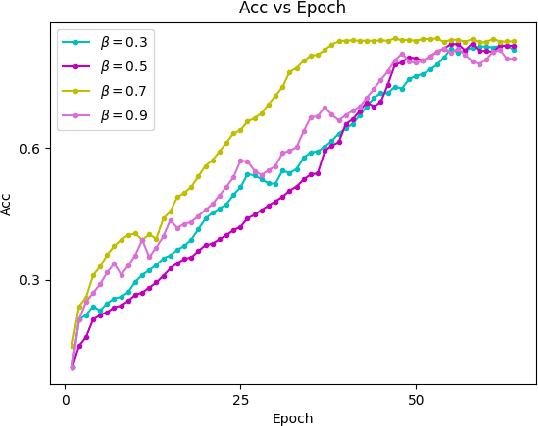
Federated learning allows a large number of devices to jointly learn a model without sharing data. In this work, we enable clients with limited computing power to perform action recognition, a computationally heavy task. We first perform model compression at the central server through knowledge distillation on a large dataset. This allows the model to learn complex features and serves as an initialization for model fine-tuning. The fine-tuning is required because the limited data present in smaller datasets is not adequate for action recognition models to learn complex spatio-temporal features. Because the clients present are often heterogeneous in their computing resources, we use an asynchronous federated optimization and we further show a convergence bound. We compare our approach to two baseline approaches: fine-tuning at the central server (no clients) and fine-tuning using (heterogeneous) clients using synchronous federated averaging. We empirically show on a testbed of heterogeneous embedded devices that we can perform action recognition with comparable accuracy to the two baselines above, while our asynchronous learning strategy reduces the training time by 40%, relative to synchronous learning.
* 13 pages, 12 figures