 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Action Recognition on Heterogeneous Embedded Devices
Paper and Code
Jul 18, 2021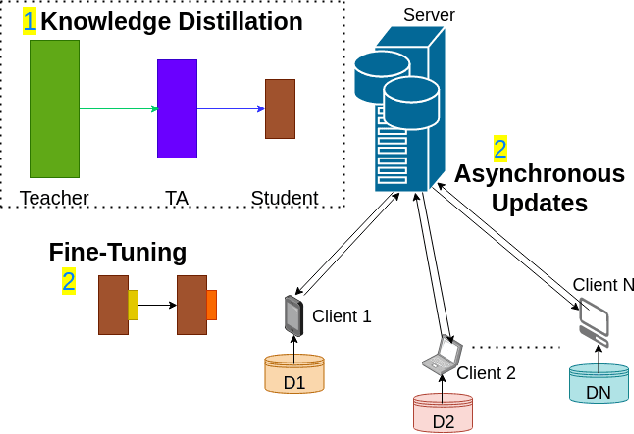
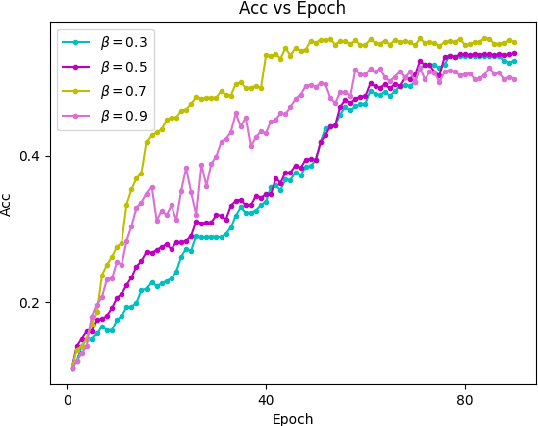
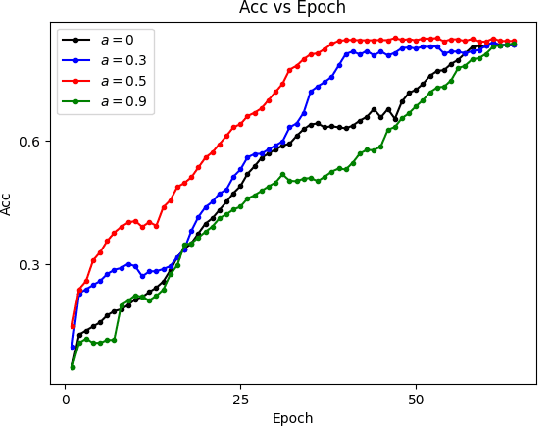
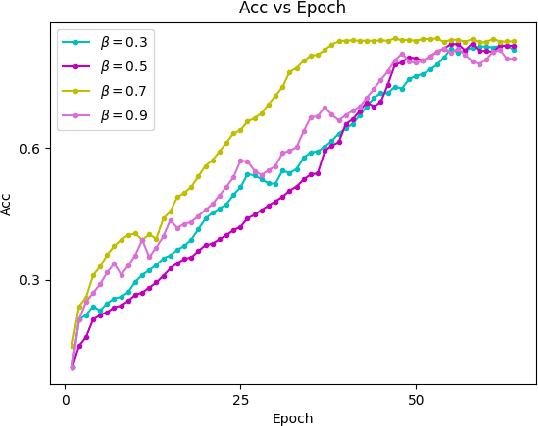
Federated learning allows a large number of devices to jointly learn a model without sharing data. In this work, we enable clients with limited computing power to perform action recognition, a computationally heavy task. We first perform model compression at the central server through knowledge distillation on a large dataset. This allows the model to learn complex features and serves as an initialization for model fine-tuning. The fine-tuning is required because the limited data present in smaller datasets is not adequate for action recognition models to learn complex spatio-temporal features. Because the clients present are often heterogeneous in their computing resources, we use an asynchronous federated optimization and we further show a convergence bound. We compare our approach to two baseline approaches: fine-tuning at the central server (no clients) and fine-tuning using (heterogeneous) clients using synchronous federated averaging. We empirically show on a testbed of heterogeneous embedded devices that we can perform action recognition with comparable accuracy to the two baselines above, while our asynchronous learning strategy reduces the training time by 40%, relative to synchronous learning.