 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Inference Adaptively for Multimodal Large Language Models
Mar 13, 2025
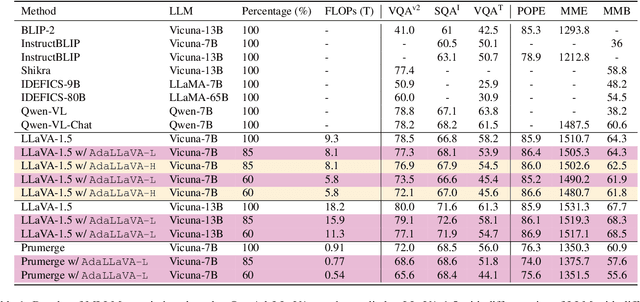
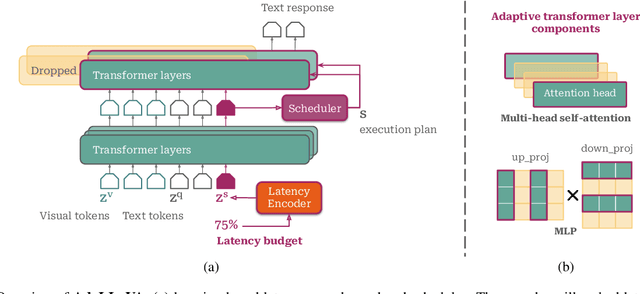
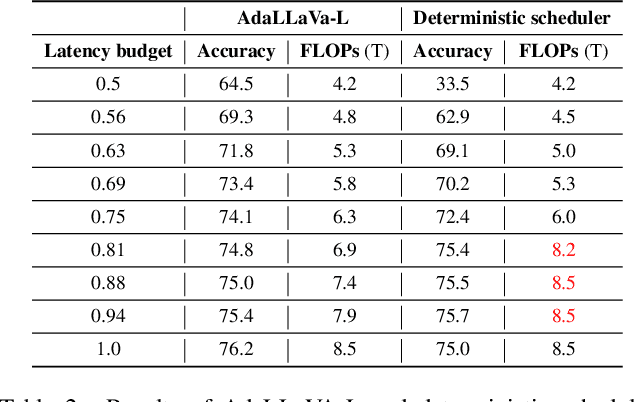
Multimodal Large Language Models (MLLMs) have shown impressive capabilities in reasoning, yet come with substantial computational cost, limiting their deployment in resource-constrained settings. Despite recent efforts on improving the efficiency of MLLMs, prior solutions fall short in responding to varying runtime conditions, in particular changing resource availability (e.g., contention due to the execution of other programs on the device). To bridge this gap, we introduce AdaLLaVA, an adaptive inference framework that learns to dynamically reconfigure operations in an MLLM during inference, accounting for the input data and a latency budget. We conduct extensive experiments across benchmarks involving question-answering, reasoning, and hallucination. Our results show that AdaLLaVA effectively adheres to input latency budget, achieving varying accuracy and latency tradeoffs at runtime. Further, we demonstrate that AdaLLaVA adapts to both input latency and content, can be integrated with token selection for enhanced efficiency, and generalizes across MLLMs.Our project webpage with code release is at https://zhuoyan-xu.github.io/ada-llava/.
Generative Model-driven Structure Aligning Discriminative Embeddings for Transductive Zero-shot Learning
May 09, 2020
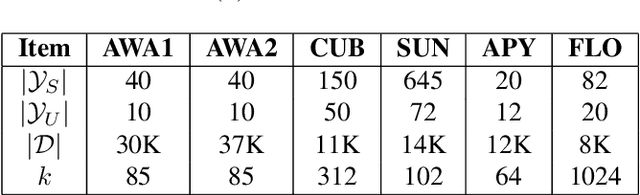
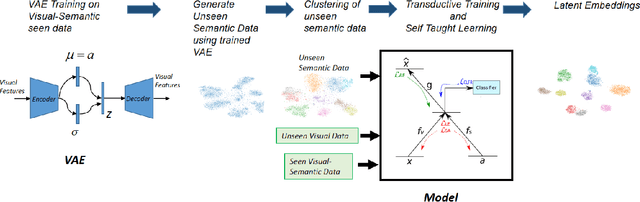
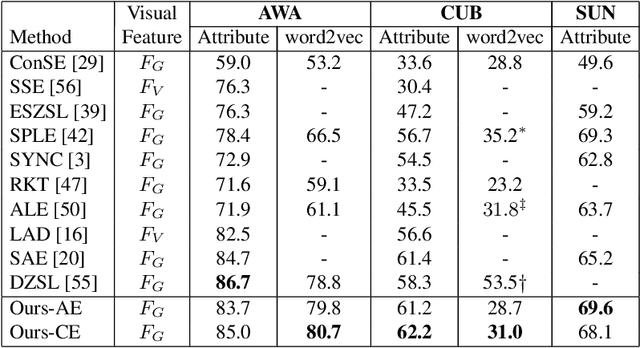
Zero-shot Learning (ZSL) is a transfer learning technique which aims at transferring knowledge from seen classes to unseen classes. This knowledge transfer is possible because of underlying semantic space which is common to seen and unseen classes. Most existing approaches learn a projection function using labelled seen class data which maps visual data to semantic data. In this work, we propose a shallow but effective neural network-based model for learning such a projection function which aligns the visual and semantic data in the latent space while simultaneously making the latent space embeddings discriminative. As the above projection function is learned using the seen class data, the so-called projection domain shift exists. We propose a transductive approach to reduce the effect of domain shift, where we utilize unlabeled visual data from unseen classes to generate corresponding semantic features for unseen class visual samples. While these semantic features are initially generated using a conditional variational auto-encoder, they are used along with the seen class data to improve the projection function. We experiment on both inductive and transductive setting of ZSL and generalized ZSL and show superior performance on standard benchmark datasets AWA1, AWA2, CUB, SUN, FLO, and APY. We also show the efficacy of our model in the case of extremely less labelled data regime on different datasets in the context of ZSL.