 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEDCNet: A Lightweight and Efficient Semantic Segmentation Algorithm Using Dual Context Module for Extracting Ground Objects from UAV Aerial Remote Sensing Images
Paper and Code



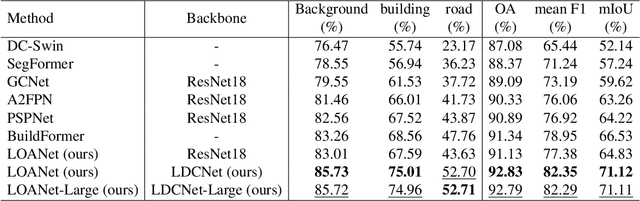
Semantic segmentation for extracting ground objects, such as road and house, from UAV remote sensing images by deep learning becomes a more efficient and convenient method than traditional manual segmentation in surveying and mapping field. In recent years, with the deepening of layers and boosting of complexity, the number of parameters in convolution-based semantic segmentation neural networks considerably increases, which is obviously not conducive to the wide application especially in the industry. In order to make the model lightweight and improve the model accuracy, a new lightweight and efficient network for the extraction of ground objects from UAV remote sensing images, named LEDCNet, is proposed. The proposed network adopts an encoder-decoder architecture in which a powerful lightweight backbone network called LDCNet is developed as the encoder. We would extend the LDCNet become a new generation backbone network of lightweight semantic segmentation algorithms. In the decoder part, the dual multi-scale context modules which consist of the ASPP module and the OCR module are designed to capture more context information from feature maps of UAV remote sensing images. Between ASPP and OCR, a FPN module is used to and fuse multi-scale features extracting from ASPP. A private dataset of remote sensing images taken by UAV which contains 2431 training sets, 945 validation sets, and 475 test sets is constructed. The proposed model performs well on this dataset, with only 1.4M parameters and 5.48G FLOPs, achieving an mIoU of 71.12%. The more extensive experiments on the public LoveDA dataset and CITY-OSM dataset to further verify the effectiveness of the proposed model with excellent results on mIoU of 65.27% and 74.39%, respectively. All the experimental results show the proposed model can not only lighten the network with few parameters but also improve the segmentation performance.