Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Machine Translation via Binary Code Prediction
Paper and Code
Apr 23, 2017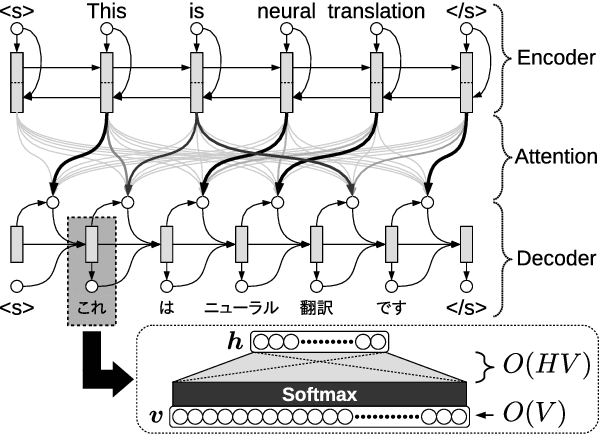
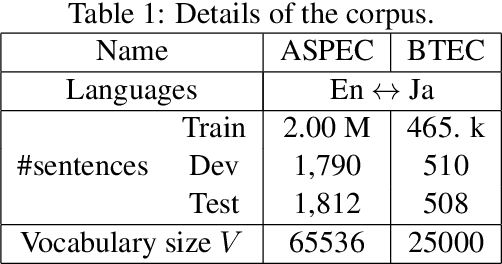

In this paper, we propose a new method for calculating the output layer in neural machine translation systems. The method is based on predicting a binary code for each word and can reduce computation time/memory requirements of the output layer to be logarithmic in vocabulary size in the best case. In addition, we also introduce two advanced approaches to improve the robustness of the proposed model: using error-correcting codes and combining softmax and binary codes. Experiments on two English-Japanese bidirectional translation tasks show proposed models achieve BLEU scores that approach the softmax, while reducing memory usage to the order of less than 1/10 and improving decoding speed on CPUs by x5 to x10.
* Accepted as a long paper at ACL2017
View paper on