 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSejarah dan Perkembangan Teknik Natural Language Processing (NLP) Bahasa Indonesia: Tinjauan tentang sejarah, perkembangan teknologi, dan aplikasi NLP dalam bahasa Indonesia
Mar 28, 2023


This study provides an overview of the history of the development of Natural Language Processing (NLP) in the context of the Indonesian language, with a focus on the basic technologies, methods, and practical applications that have been developed. This review covers developments in basic NLP technologies such as stemming, part-of-speech tagging, and related methods; practical applications in cross-language information retrieval systems, information extraction, and sentiment analysis; and methods and techniques used in Indonesian language NLP research, such as machine learning, statistics-based machine translation, and conflict-based approaches. This study also explores the application of NLP in Indonesian language industry and research and identifies challenges and opportunities in Indonesian language NLP research and development. Recommendations for future Indonesian language NLP research and development include developing more efficient methods and technologies, expanding NLP applications, increasing sustainability, further research into the potential of NLP, and promoting interdisciplinary collaboration. It is hoped that this review will help researchers, practitioners, and the government to understand the development of Indonesian language NLP and identify opportunities for further research and development.
Reduce Indonesian Vocabularies with an Indonesian Sub-word Separator
Jul 01, 2022


Indonesian is an agglutinative language since it has a compounding process of word-formation. Therefore, the translation model of this language requires a mechanism that is even lower than the word level, referred to as the sub-word level. This compounding process leads to a rare word problem since the number of vocabulary explodes. We propose a strategy to address the unique word problem of the neural machine translation (NMT) system, which uses Indonesian as a pair language. Our approach uses a rule-based method to transform a word into its roots and accompanied affixes to retain its meaning and context. Using a rule-based algorithm has more advantages: it does not require corpus data but only applies the standard Indonesian rules. Our experiments confirm that this method is practical. It reduces the number of vocabulary significantly up to 57\%, and on the English to Indonesian translation, this strategy provides an improvement of up to 5 BLEU points over a similar NMT system that does not use this technique.
Location-based Twitter Filtering for the Creation of Low-Resource Language Datasets in Indonesian Local Languages
Jun 15, 2022



Twitter contains an abundance of linguistic data from the real world. We examine Twitter for user-generated content in low-resource languages such as local Indonesian. For NLP to work in Indonesian, it must consider local dialects, geographic context, and regional culture influence Indonesian languages. This paper identifies the problems we faced when constructing a Local Indonesian NLP dataset. Furthermore, we are developing a framework for creating, collecting, and classifying Local Indonesian datasets for NLP. Using twitter's geolocation tool for automatic annotating.
Synthetic Source Language Augmentation for Colloquial Neural Machine Translation
Dec 30, 2020

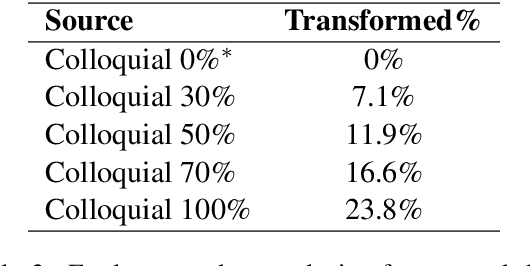
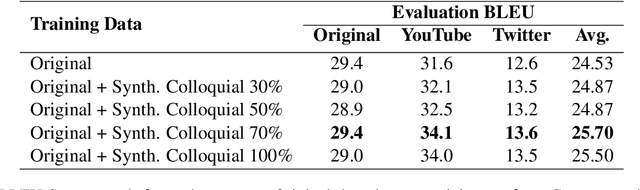
Neural machine translation (NMT) is typically domain-dependent and style-dependent, and it requires lots of training data. State-of-the-art NMT models often fall short in handling colloquial variations of its source language and the lack of parallel data in this regard is a challenging hurdle in systematically improving the existing models. In this work, we develop a novel colloquial Indonesian-English test-set collected from YouTube transcript and Twitter. We perform synthetic style augmentation to the source of formal Indonesian language and show that it improves the baseline Id-En models (in BLEU) over the new test data.