Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Source Language Augmentation for Colloquial Neural Machine Translation
Paper and Code


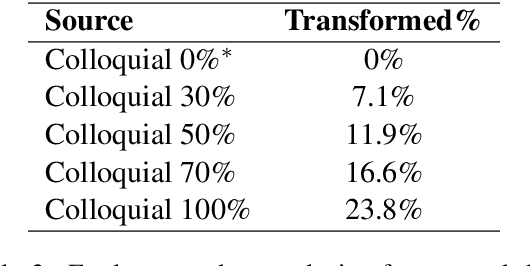
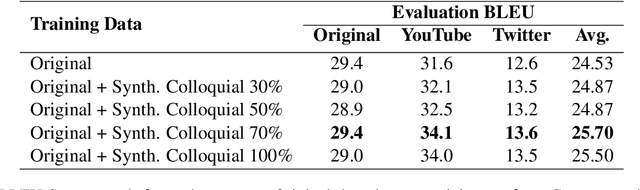
Neural machine translation (NMT) is typically domain-dependent and style-dependent, and it requires lots of training data. State-of-the-art NMT models often fall short in handling colloquial variations of its source language and the lack of parallel data in this regard is a challenging hurdle in systematically improving the existing models. In this work, we develop a novel colloquial Indonesian-English test-set collected from YouTube transcript and Twitter. We perform synthetic style augmentation to the source of formal Indonesian language and show that it improves the baseline Id-En models (in BLEU) over the new test data.
* 5 pages
View paper on