 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReduce Indonesian Vocabularies with an Indonesian Sub-word Separator
Jul 01, 2022
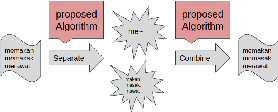


Indonesian is an agglutinative language since it has a compounding process of word-formation. Therefore, the translation model of this language requires a mechanism that is even lower than the word level, referred to as the sub-word level. This compounding process leads to a rare word problem since the number of vocabulary explodes. We propose a strategy to address the unique word problem of the neural machine translation (NMT) system, which uses Indonesian as a pair language. Our approach uses a rule-based method to transform a word into its roots and accompanied affixes to retain its meaning and context. Using a rule-based algorithm has more advantages: it does not require corpus data but only applies the standard Indonesian rules. Our experiments confirm that this method is practical. It reduces the number of vocabulary significantly up to 57\%, and on the English to Indonesian translation, this strategy provides an improvement of up to 5 BLEU points over a similar NMT system that does not use this technique.