 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReduce Indonesian Vocabularies with an Indonesian Sub-word Separator
Jul 01, 2022


Indonesian is an agglutinative language since it has a compounding process of word-formation. Therefore, the translation model of this language requires a mechanism that is even lower than the word level, referred to as the sub-word level. This compounding process leads to a rare word problem since the number of vocabulary explodes. We propose a strategy to address the unique word problem of the neural machine translation (NMT) system, which uses Indonesian as a pair language. Our approach uses a rule-based method to transform a word into its roots and accompanied affixes to retain its meaning and context. Using a rule-based algorithm has more advantages: it does not require corpus data but only applies the standard Indonesian rules. Our experiments confirm that this method is practical. It reduces the number of vocabulary significantly up to 57\%, and on the English to Indonesian translation, this strategy provides an improvement of up to 5 BLEU points over a similar NMT system that does not use this technique.
Exploring Explainable Selection to Control Abstractive Generation
Apr 24, 2020
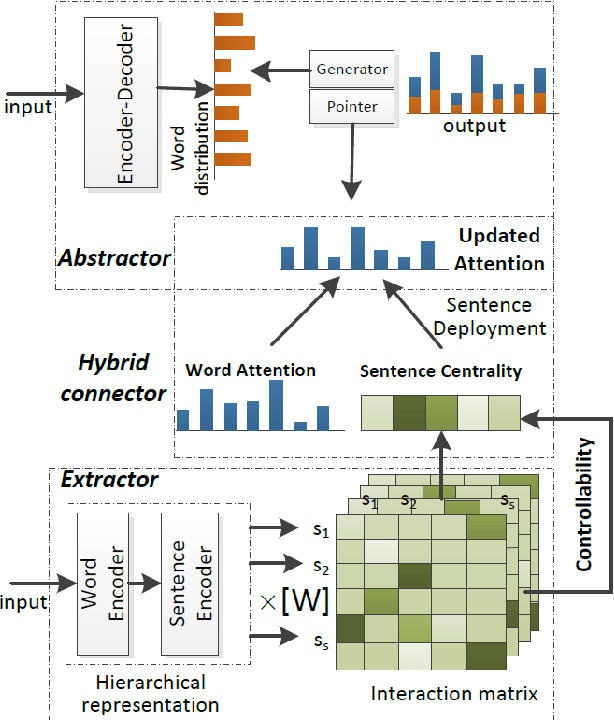
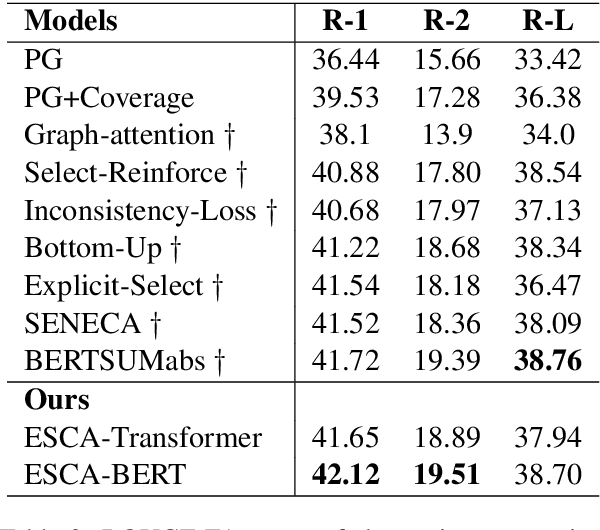
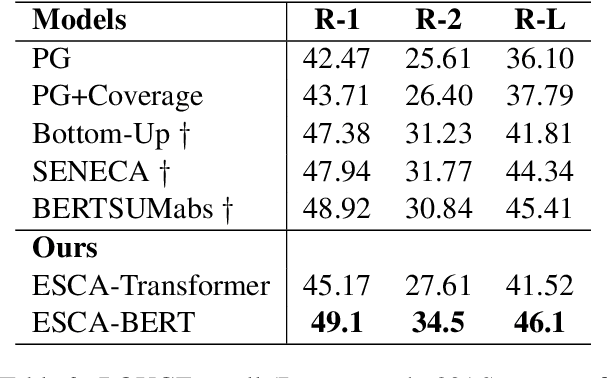
It is a big challenge to model long-range input for document summarization. In this paper, we target using a select and generate paradigm to enhance the capability of selecting explainable contents (i.e., interpret the selection given its semantics, novelty, relevance) and then guiding to control the abstract generation. Specifically, a newly designed pair-wise extractor is proposed to capture the sentence pair interactions and their centrality. Furthermore, the generator is hybrid with the selected content and is jointly integrated with a pointer distribution that is derived from a sentence deployment's attention. The abstract generation can be controlled by an explainable mask matrix that determines to what extent the content can be included in the summary. Encoders are adaptable with both Transformer-based and BERT-based configurations. Overall, both results based on ROUGE metrics and human evaluation gain outperformance over several state-of-the-art models on two benchmark CNN/DailyMail and NYT datasets.
Concept Pointer Network for Abstractive Summarization
Oct 18, 2019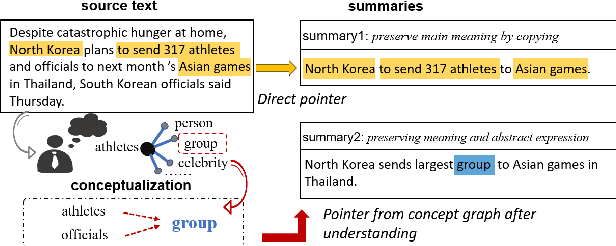
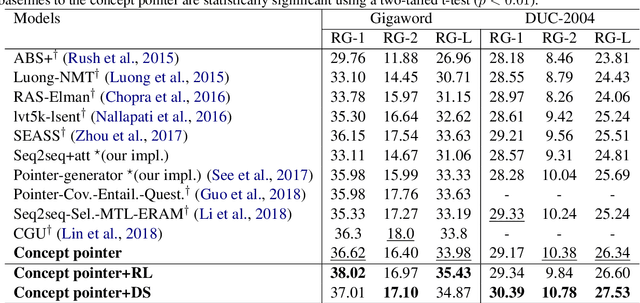


A quality abstractive summary should not only copy salient source texts as summaries but should also tend to generate new conceptual words to express concrete details. Inspired by the popular pointer generator sequence-to-sequence model, this paper presents a concept pointer network for improving these aspects of abstractive summarization. The network leverages knowledge-based, context-aware conceptualizations to derive an extended set of candidate concepts. The model then points to the most appropriate choice using both the concept set and original source text. This joint approach generates abstractive summaries with higher-level semantic concepts. The training model is also optimized in a way that adapts to different data, which is based on a novel method of distantly-supervised learning guided by reference summaries and testing set. Overall, the proposed approach provides statistically significant improvements over several state-of-the-art models on both the DUC-2004 and Gigaword datasets. A human evaluation of the model's abstractive abilities also supports the quality of the summaries produced within this framework.