 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNusaWrites: Constructing High-Quality Corpora for Underrepresented and Extremely Low-Resource Languages
Sep 20, 2023



Democratizing access to natural language processing (NLP) technology is crucial, especially for underrepresented and extremely low-resource languages. Previous research has focused on developing labeled and unlabeled corpora for these languages through online scraping and document translation. While these methods have proven effective and cost-efficient, we have identified limitations in the resulting corpora, including a lack of lexical diversity and cultural relevance to local communities. To address this gap, we conduct a case study on Indonesian local languages. We compare the effectiveness of online scraping, human translation, and paragraph writing by native speakers in constructing datasets. Our findings demonstrate that datasets generated through paragraph writing by native speakers exhibit superior quality in terms of lexical diversity and cultural content. In addition, we present the \datasetname{} benchmark, encompassing 12 underrepresented and extremely low-resource languages spoken by millions of individuals in Indonesia. Our empirical experiment results using existing multilingual large language models conclude the need to extend these models to more underrepresented languages. We release the NusaWrites dataset at https://github.com/IndoNLP/nusa-writes.
Transfer-Learning-Aware Neuro-Evolution for Diseases Detection in Chest X-Ray Images
Apr 15, 2020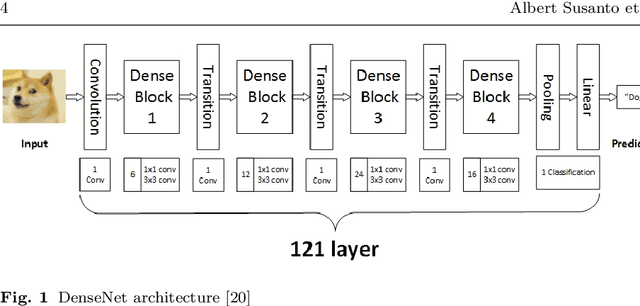
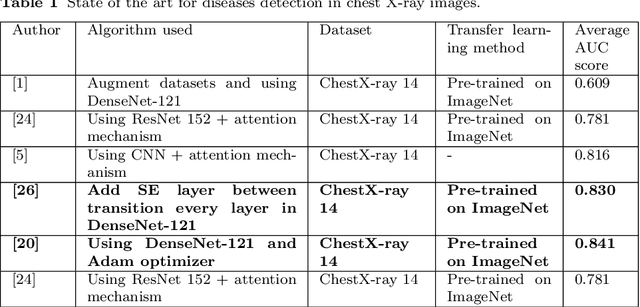
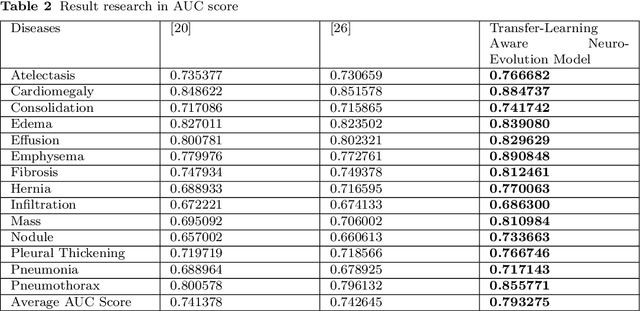
The neural network needs excessive costs of time because of the complexity of architecture when trained on images. Transfer learning and fine-tuning can help improve time and cost efficiency when training a neural network. Yet, Transfer learning and fine-tuning needs a lot of experiment to try with. Therefore, a method to find the best architecture for transfer learning and fine-tuning is needed. To overcome this problem, neuro-evolution using a genetic algorithm can be used to find the best architecture for transfer learning. To check the performance of this study, dataset ChestX-Ray 14 and DenseNet-121 as a base neural network model are used. This study used the AUC score, differences in execution time for training, and McNemar's test to the significance test. In terms of result, this study got a 5% difference in the AUC score, 3 % faster in terms of execution time, and significance in most of the disease detection. Finally, this study gives a concrete summary of how neuro-evolution transfer learning can help in terms of transfer learning and fine-tuning.
Deep Learning for Imbalance Data Classification using Class Expert Generative Adversarial Network
Jul 13, 2018



Without any specific way for imbalance data classification, artificial intelligence algorithm cannot recognize data from minority classes easily. In general, modifying the existing algorithm by assuming that the training data is imbalanced, is the only way to handle imbalance data. However, for a normal data handling, this way mostly produces a deficient result. In this research, we propose a class expert generative adversarial network (CE-GAN) as the solution for imbalance data classification. CE-GAN is a modification in deep learning algorithm architecture that does not have an assumption that the training data is imbalance data. Moreover, CE-GAN is designed to identify more detail about the character of each class before classification step. CE-GAN has been proved in this research to give a good performance for imbalance data classification.