 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Confidence Evaluation Measures in Zero-Shot CSS Classification
Oct 16, 2024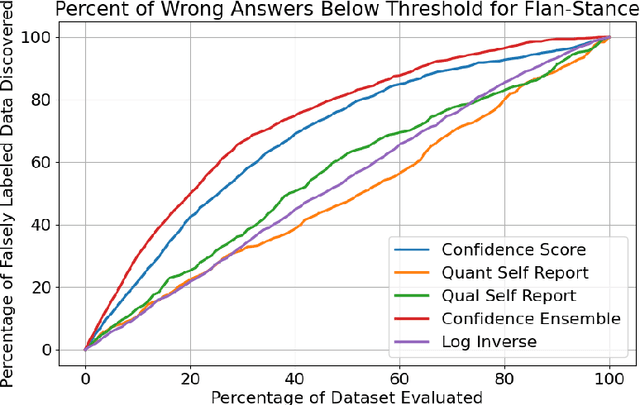
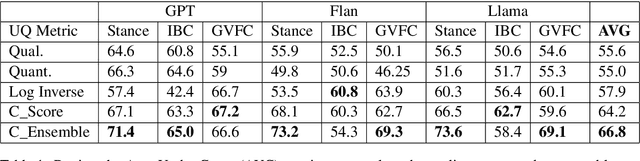
Assessing classification confidence is critical for leveraging large language models (LLMs) in automated labeling tasks, especially in the sensitive domains presented by Computational Social Science (CSS) tasks. In this paper, we make three key contributions: (1) we propose an uncertainty quantification (UQ) performance measure tailored for data annotation tasks, (2) we compare, for the first time, five different UQ strategies across three distinct LLMs and CSS data annotation tasks, (3) we introduce a novel UQ aggregation strategy that effectively identifies low-confidence LLM annotations and disproportionately uncovers data incorrectly labeled by the LLMs. Our results demonstrate that our proposed UQ aggregation strategy improves upon existing methods andcan be used to significantly improve human-in-the-loop data annotation processes.
LLM Chain Ensembles for Scalable and Accurate Data Annotation
Oct 16, 2024
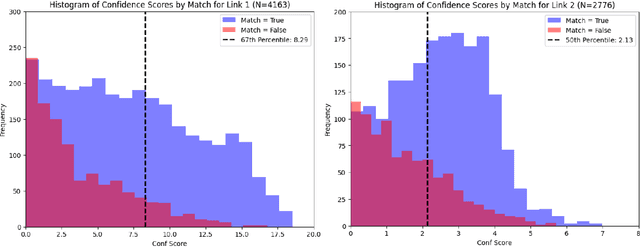

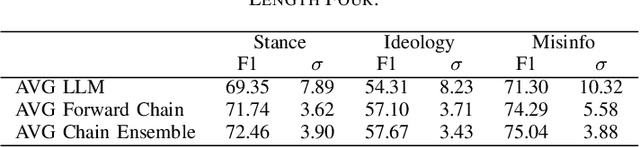
The ability of large language models (LLMs) to perform zero-shot classification makes them viable solutions for data annotation in rapidly evolving domains where quality labeled data is often scarce and costly to obtain. However, the large-scale deployment of LLMs can be prohibitively expensive. This paper introduces an LLM chain ensemble methodology that aligns multiple LLMs in a sequence, routing data subsets to subsequent models based on classification uncertainty. This approach leverages the strengths of individual LLMs within a broader system, allowing each model to handle data points where it exhibits the highest confidence, while forwarding more complex cases to potentially more robust models. Our results show that the chain ensemble method often exceeds the performance of the best individual model in the chain and achieves substantial cost savings, making LLM chain ensembles a practical and efficient solution for large-scale data annotation challenges.
RED-CT: A Systems Design Methodology for Using LLM-labeled Data to Train and Deploy Edge Classifiers for Computational Social Science
Aug 15, 2024Large language models (LLMs) have enhanced our ability to rapidly analyze and classify unstructured natural language data. However, concerns regarding cost, network limitations, and security constraints have posed challenges for their integration into work processes. In this study, we adopt a systems design approach to employing LLMs as imperfect data annotators for downstream supervised learning tasks, introducing novel system intervention measures aimed at improving classification performance. Our methodology outperforms LLM-generated labels in seven of eight tests, demonstrating an effective strategy for incorporating LLMs into the design and deployment of specialized, supervised learning models present in many industry use cases.
Examining the Influence of Political Bias on Large Language Model Performance in Stance Classification
Jul 26, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities in executing tasks based on natural language queries. However, these models, trained on curated datasets, inherently embody biases ranging from racial to national and gender biases. It remains uncertain whether these biases impact the performance of LLMs for certain tasks. In this study, we investigate the political biases of LLMs within the stance classification task, specifically examining whether these models exhibit a tendency to more accurately classify politically-charged stances. Utilizing three datasets, seven LLMs, and four distinct prompting schemes, we analyze the performance of LLMs on politically oriented statements and targets. Our findings reveal a statistically significant difference in the performance of LLMs across various politically oriented stance classification tasks. Furthermore, we observe that this difference primarily manifests at the dataset level, with models and prompting schemes showing statistically similar performances across different stance classification datasets. Lastly, we observe that when there is greater ambiguity in the target the statement is directed towards, LLMs have poorer stance classification accuracy. Code & Dataset: http://doi.org/10.5281/zenodo.12938478
DocNet: Semantic Structure in Inductive Bias Detection Models
Jun 16, 2024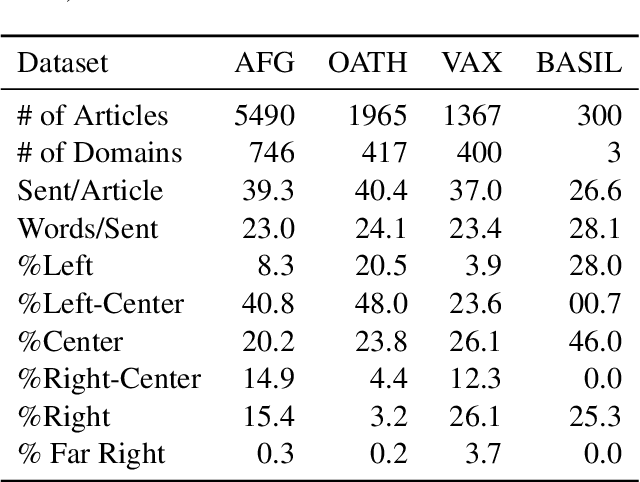

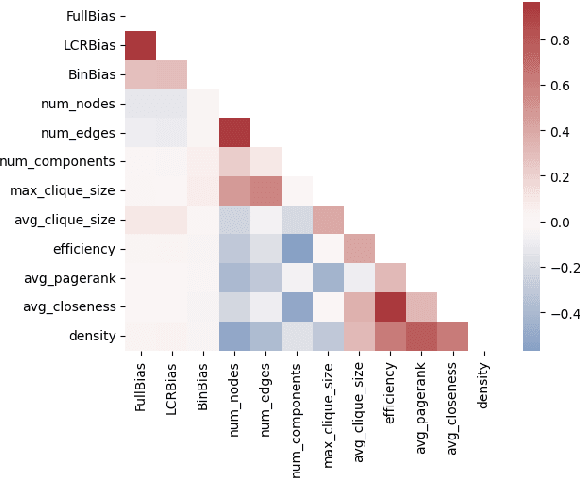
News will have biases so long as people have opinions. However, as social media becomes the primary entry point for news and partisan gaps increase, it is increasingly important for informed citizens to be able to identify bias. People will be able to take action to avoid polarizing echo chambers if they know how the news they are consuming is biased. In this paper, we explore an often overlooked aspect of bias detection in documents: the semantic structure of news articles. We present DocNet, a novel, inductive, and low-resource document embedding and bias detection model that outperforms large language models. We also demonstrate that the semantic structure of news articles from opposing partisan sides, as represented in document-level graph embeddings, have significant similarities. These results can be used to advance bias detection in low-resource environments. Our code and data are made available at https://github.com/nlpresearchanon.
MLTEing Models: Negotiating, Evaluating, and Documenting Model and System Qualities
Mar 03, 2023
Many organizations seek to ensure that machine learning (ML) and artificial intelligence (AI) systems work as intended in production but currently do not have a cohesive methodology in place to do so. To fill this gap, we propose MLTE (Machine Learning Test and Evaluation, colloquially referred to as "melt"), a framework and implementation to evaluate ML models and systems. The framework compiles state-of-the-art evaluation techniques into an organizational process for interdisciplinary teams, including model developers, software engineers, system owners, and other stakeholders. MLTE tooling supports this process by providing a domain-specific language that teams can use to express model requirements, an infrastructure to define, generate, and collect ML evaluation metrics, and the means to communicate results.
Coordinating Narratives and the Capitol Riots on Parler
Sep 02, 2021


Coordinated disinformation campaigns are used to influence social media users, potentially leading to offline violence. In this study, we introduce a general methodology to uncover coordinated messaging through analysis of user parleys on Parler. The proposed method constructs a user-to-user coordination network graph induced by a user-to-text graph and a text-to-text similarity graph. The text-to-text graph is constructed based on the textual similarity of Parler posts. We study three influential groups of users in the 6 January 2020 Capitol riots and detect networks of coordinated user clusters that are all posting similar textual content in support of different disinformation narratives related to the U.S. 2020 elections.