 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Confidence Evaluation Measures in Zero-Shot CSS Classification
Oct 16, 2024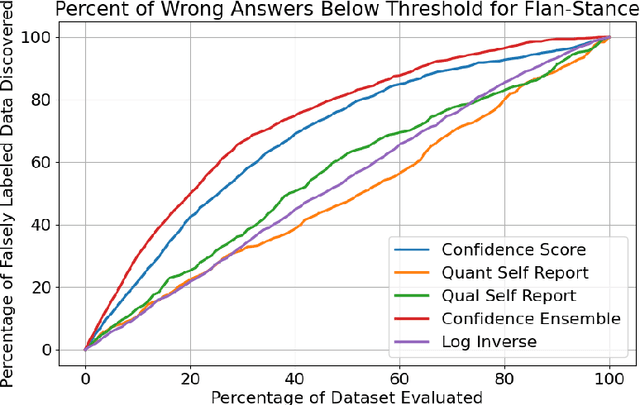
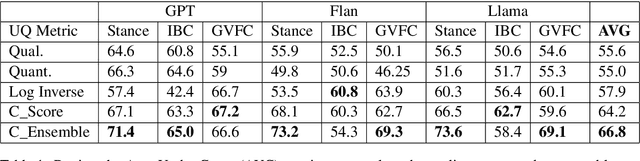
Assessing classification confidence is critical for leveraging large language models (LLMs) in automated labeling tasks, especially in the sensitive domains presented by Computational Social Science (CSS) tasks. In this paper, we make three key contributions: (1) we propose an uncertainty quantification (UQ) performance measure tailored for data annotation tasks, (2) we compare, for the first time, five different UQ strategies across three distinct LLMs and CSS data annotation tasks, (3) we introduce a novel UQ aggregation strategy that effectively identifies low-confidence LLM annotations and disproportionately uncovers data incorrectly labeled by the LLMs. Our results demonstrate that our proposed UQ aggregation strategy improves upon existing methods andcan be used to significantly improve human-in-the-loop data annotation processes.
LLM Chain Ensembles for Scalable and Accurate Data Annotation
Oct 16, 2024
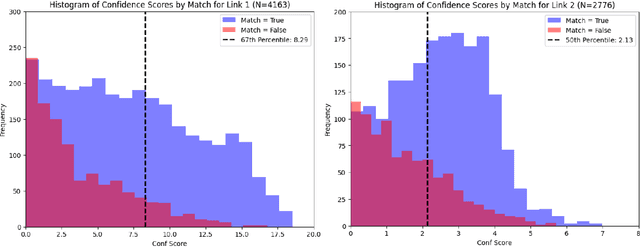

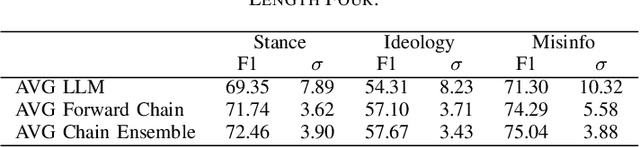
The ability of large language models (LLMs) to perform zero-shot classification makes them viable solutions for data annotation in rapidly evolving domains where quality labeled data is often scarce and costly to obtain. However, the large-scale deployment of LLMs can be prohibitively expensive. This paper introduces an LLM chain ensemble methodology that aligns multiple LLMs in a sequence, routing data subsets to subsequent models based on classification uncertainty. This approach leverages the strengths of individual LLMs within a broader system, allowing each model to handle data points where it exhibits the highest confidence, while forwarding more complex cases to potentially more robust models. Our results show that the chain ensemble method often exceeds the performance of the best individual model in the chain and achieves substantial cost savings, making LLM chain ensembles a practical and efficient solution for large-scale data annotation challenges.
RED-CT: A Systems Design Methodology for Using LLM-labeled Data to Train and Deploy Edge Classifiers for Computational Social Science
Aug 15, 2024Large language models (LLMs) have enhanced our ability to rapidly analyze and classify unstructured natural language data. However, concerns regarding cost, network limitations, and security constraints have posed challenges for their integration into work processes. In this study, we adopt a systems design approach to employing LLMs as imperfect data annotators for downstream supervised learning tasks, introducing novel system intervention measures aimed at improving classification performance. Our methodology outperforms LLM-generated labels in seven of eight tests, demonstrating an effective strategy for incorporating LLMs into the design and deployment of specialized, supervised learning models present in many industry use cases.