 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs your LLM trapped in a Mental Set? Investigative study on how mental sets affect the reasoning capabilities of LLMs
Jan 21, 2025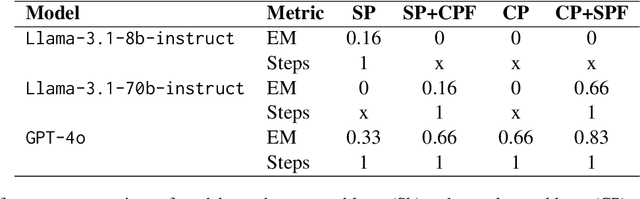
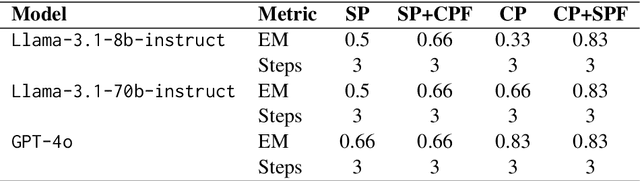

In this paper, we present an investigative study on how Mental Sets influence the reasoning capabilities of LLMs. LLMs have excelled in diverse natural language processing (NLP) tasks, driven by advancements in parameter-efficient fine-tuning (PEFT) and emergent capabilities like in-context learning (ICL). For complex reasoning tasks, selecting the right model for PEFT or ICL is critical, often relying on scores on benchmarks such as MMLU, MATH, and GSM8K. However, current evaluation methods, based on metrics like F1 Score or reasoning chain assessments by larger models, overlook a key dimension: adaptability to unfamiliar situations and overcoming entrenched thinking patterns. In cognitive psychology, Mental Set refers to the tendency to persist with previously successful strategies, even when they become inefficient - a challenge for problem solving and reasoning. We compare the performance of LLM models like Llama-3.1-8B-Instruct, Llama-3.1-70B-Instruct and GPT-4o in the presence of mental sets. To the best of our knowledge, this is the first study to integrate cognitive psychology concepts into the evaluation of LLMs for complex reasoning tasks, providing deeper insights into their adaptability and problem-solving efficacy.
IndicIRSuite: Multilingual Dataset and Neural Information Models for Indian Languages
Dec 15, 2023
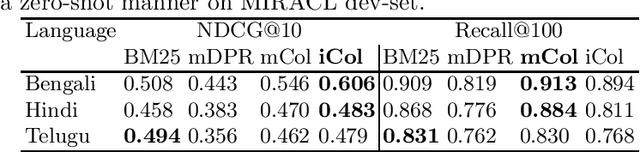
In this paper, we introduce Neural Information Retrieval resources for 11 widely spoken Indian Languages (Assamese, Bengali, Gujarati, Hindi, Kannada, Malayalam, Marathi, Oriya, Punjabi, Tamil, and Telugu) from two major Indian language families (Indo-Aryan and Dravidian). These resources include (a) INDIC-MARCO, a multilingual version of the MSMARCO dataset in 11 Indian Languages created using Machine Translation, and (b) Indic-ColBERT, a collection of 11 distinct Monolingual Neural Information Retrieval models, each trained on one of the 11 languages in the INDIC-MARCO dataset. To the best of our knowledge, IndicIRSuite is the first attempt at building large-scale Neural Information Retrieval resources for a large number of Indian languages, and we hope that it will help accelerate research in Neural IR for Indian Languages. Experiments demonstrate that Indic-ColBERT achieves 47.47% improvement in the MRR@10 score averaged over the INDIC-MARCO baselines for all 11 Indian languages except Oriya, 12.26% improvement in the NDCG@10 score averaged over the MIRACL Bengali and Hindi Language baselines, and 20% improvement in the MRR@100 Score over the Mr.Tydi Bengali Language baseline. IndicIRSuite is available at https://github.com/saifulhaq95/IndicIRSuite
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Oct 05, 2023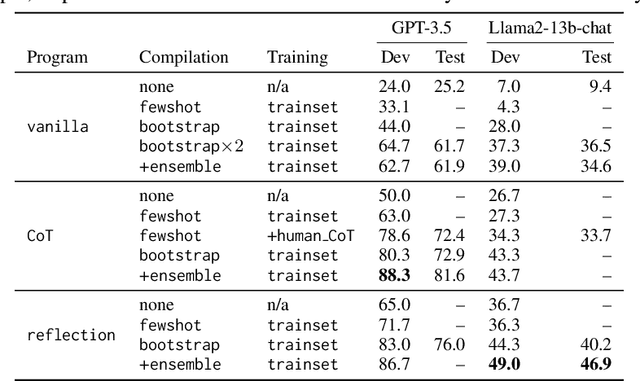

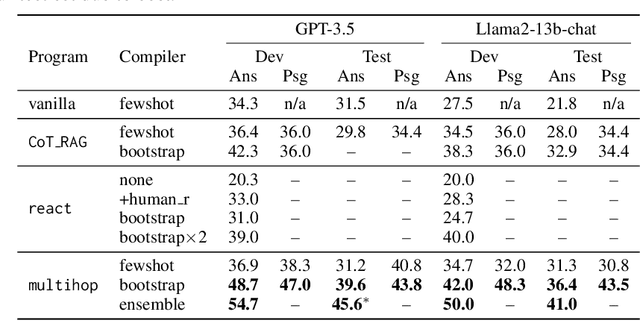

The ML community is rapidly exploring techniques for prompting language models (LMs) and for stacking them into pipelines that solve complex tasks. Unfortunately, existing LM pipelines are typically implemented using hard-coded "prompt templates", i.e. lengthy strings discovered via trial and error. Toward a more systematic approach for developing and optimizing LM pipelines, we introduce DSPy, a programming model that abstracts LM pipelines as text transformation graphs, i.e. imperative computational graphs where LMs are invoked through declarative modules. DSPy modules are parameterized, meaning they can learn (by creating and collecting demonstrations) how to apply compositions of prompting, finetuning, augmentation, and reasoning techniques. We design a compiler that will optimize any DSPy pipeline to maximize a given metric. We conduct two case studies, showing that succinct DSPy programs can express and optimize sophisticated LM pipelines that reason about math word problems, tackle multi-hop retrieval, answer complex questions, and control agent loops. Within minutes of compiling, a few lines of DSPy allow GPT-3.5 and llama2-13b-chat to self-bootstrap pipelines that outperform standard few-shot prompting (generally by over 25% and 65%, respectively) and pipelines with expert-created demonstrations (by up to 5-46% and 16-40%, respectively). On top of that, DSPy programs compiled to open and relatively small LMs like 770M-parameter T5 and llama2-13b-chat are competitive with approaches that rely on expert-written prompt chains for proprietary GPT-3.5. DSPy is available at https://github.com/stanfordnlp/dspy