 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Opinions at Scale: Incremental Opinion Summarization using XL-OPSUMM
Jun 16, 2024



Opinion summarization in e-commerce encapsulates the collective views of numerous users about a product based on their reviews. Typically, a product on an e-commerce platform has thousands of reviews, each review comprising around 10-15 words. While Large Language Models (LLMs) have shown proficiency in summarization tasks, they struggle to handle such a large volume of reviews due to context limitations. To mitigate, we propose a scalable framework called Xl-OpSumm that generates summaries incrementally. However, the existing test set, AMASUM has only 560 reviews per product on average. Due to the lack of a test set with thousands of reviews, we created a new test set called Xl-Flipkart by gathering data from the Flipkart website and generating summaries using GPT-4. Through various automatic evaluations and extensive analysis, we evaluated the framework's efficiency on two datasets, AMASUM and Xl-Flipkart. Experimental results show that our framework, Xl-OpSumm powered by Llama-3-8B-8k, achieves an average ROUGE-1 F1 gain of 4.38% and a ROUGE-L F1 gain of 3.70% over the next best-performing model.
Transformers are Expressive, But Are They Expressive Enough for Regression?
Feb 23, 2024


Transformers have become pivotal in Natural Language Processing, demonstrating remarkable success in applications like Machine Translation and Summarization. Given their widespread adoption, several works have attempted to analyze the expressivity of Transformers. Expressivity of a neural network is the class of functions it can approximate. A neural network is fully expressive if it can act as a universal function approximator. We attempt to analyze the same for Transformers. Contrary to existing claims, our findings reveal that Transformers struggle to reliably approximate continuous functions, relying on piecewise constant approximations with sizable intervals. The central question emerges as: "\textit{Are Transformers truly Universal Function Approximators}?" To address this, we conduct a thorough investigation, providing theoretical insights and supporting evidence through experiments. Our contributions include a theoretical analysis pinpointing the root of Transformers' limitation in function approximation and extensive experiments to verify the limitation. By shedding light on these challenges, we advocate a refined understanding of Transformers' capabilities.
Leveraging Domain Knowledge for Efficient Reward Modelling in RLHF: A Case-Study in E-Commerce Opinion Summarization
Feb 23, 2024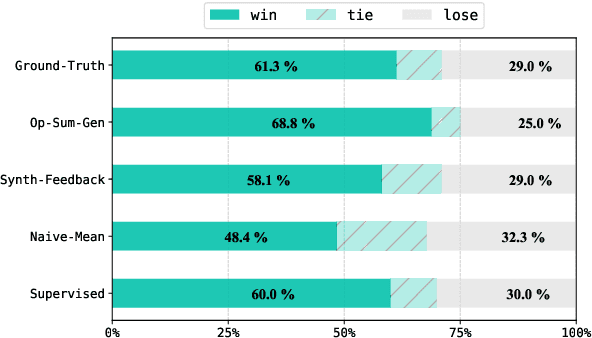



Reinforcement Learning from Human Feedback (RLHF) has become a dominating strategy in steering Language Models (LMs) towards human values/goals. The key to the strategy is employing a reward model ({$\varphi$}) which can reflect a latent reward model with humans. While this strategy has proven to be effective, the training methodology requires a lot of human preference annotation (usually of the order of tens of thousands) to train {$\varphi$}. Such large-scale preference annotations can be achievable if the reward model can be ubiquitously used. However, human values/goals are subjective and depend on the nature of the task. This poses a challenge in collecting diverse preferences for downstream applications. To address this, we propose a novel methodology to infuse domain knowledge into {$\varphi$}, which reduces the size of preference annotation required. We validate our approach in E-Commerce Opinion Summarization, with a significant reduction in dataset size (just $940$ samples) while advancing the state-of-the-art. Our contributions include a novel Reward Modelling technique, a new dataset (PromptOpinSumm) for Opinion Summarization, and a human preference dataset (OpinPref). The proposed methodology opens avenues for efficient RLHF, making it more adaptable to diverse applications with varying human values. We release the artifacts for usage under MIT License.
One Prompt To Rule Them All: LLMs for Opinion Summary Evaluation
Feb 18, 2024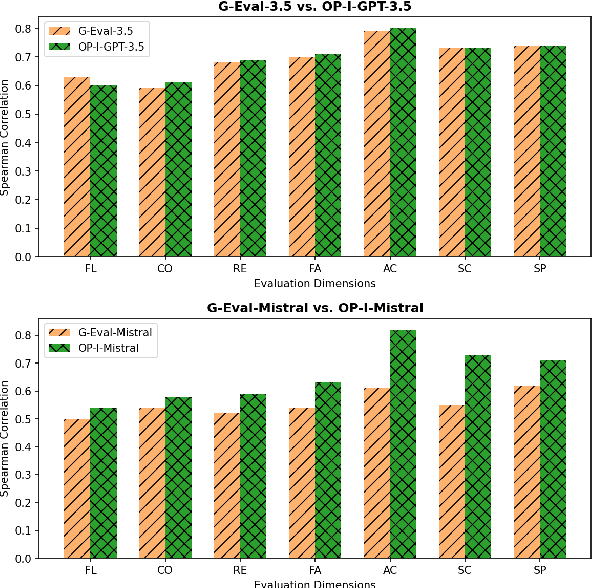



Evaluation of opinion summaries using conventional reference-based metrics rarely provides a holistic evaluation and has been shown to have a relatively low correlation with human judgments. Recent studies suggest using Large Language Models (LLMs) as reference-free metrics for NLG evaluation, however, they remain unexplored for opinion summary evaluation. Moreover, limited opinion summary evaluation datasets inhibit progress. To address this, we release the SUMMEVAL-OP dataset covering 7 dimensions related to the evaluation of opinion summaries: fluency, coherence, relevance, faithfulness, aspect coverage, sentiment consistency, and specificity. We investigate Op-I-Prompt a dimension-independent prompt, and Op-Prompts, a dimension-dependent set of prompts for opinion summary evaluation. Experiments indicate that Op-I-Prompt emerges as a good alternative for evaluating opinion summaries achieving an average Spearman correlation of 0.70 with humans, outperforming all previous approaches. To the best of our knowledge, we are the first to investigate LLMs as evaluators on both closed-source and open-source models in the opinion summarization domain.
Reinforcement Replaces Supervision: Query focused Summarization using Deep Reinforcement Learning
Nov 29, 2023Query-focused Summarization (QfS) deals with systems that generate summaries from document(s) based on a query. Motivated by the insight that Reinforcement Learning (RL) provides a generalization to Supervised Learning (SL) for Natural Language Generation, and thereby performs better (empirically) than SL, we use an RL-based approach for this task of QfS. Additionally, we also resolve the conflict of employing RL in Transformers with Teacher Forcing. We develop multiple Policy Gradient networks, trained on various reward signals: ROUGE, BLEU, and Semantic Similarity, which lead to a 10-point improvement over the State-of-the-Art approach on the ROUGE-L metric for a benchmark dataset (ELI5). We also show performance of our approach in zero-shot setting for another benchmark dataset (DebatePedia) -- our approach leads to results comparable to baselines, which were specifically trained on DebatePedia. To aid the RL training, we propose a better semantic similarity reward, enabled by a novel Passage Embedding scheme developed using Cluster Hypothesis. Lastly, we contribute a gold-standard test dataset to further research in QfS and Long-form Question Answering (LfQA).