 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVectorized Region Based Brush Strokes for Artistic Rendering
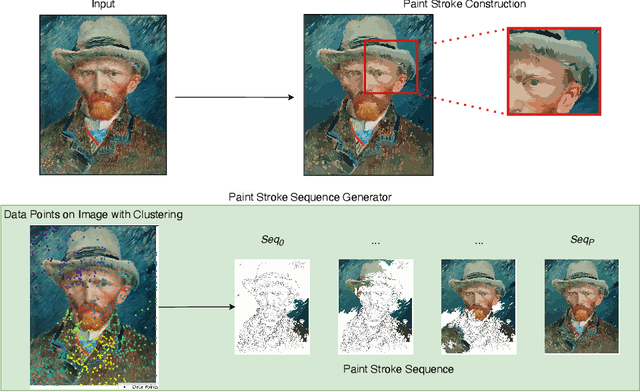
Jun 11, 2025Creating a stroke-by-stroke evolution process of a visual artwork tries to bridge the emotional and educational gap between the finished static artwork and its creation process. Recent stroke-based painting systems focus on capturing stroke details by predicting and iteratively refining stroke parameters to maximize the similarity between the input image and the rendered output. However, these methods often struggle to produce stroke compositions that align with artistic principles and intent. To address this, we explore an image-to-painting method that (i) facilitates semantic guidance for brush strokes in targeted regions, (ii) computes the brush stroke parameters, and (iii) establishes a sequence among segments and strokes to sequentially render the final painting. Experimental results on various input image types, such as face images, paintings, and photographic images, show that our method aligns with a region-based painting strategy while rendering a painting with high fidelity and superior stroke quality.
OrienText: Surface Oriented Textual Image Generation
May 27, 2025Textual content in images is crucial in e-commerce sectors, particularly in marketing campaigns, product imaging, advertising, and the entertainment industry. Current text-to-image (T2I) generation diffusion models, though proficient at producing high-quality images, often struggle to incorporate text accurately onto complex surfaces with varied perspectives, such as angled views of architectural elements like buildings, banners, or walls. In this paper, we introduce the Surface Oriented Textual Image Generation (OrienText) method, which leverages region-specific surface normals as conditional input to T2I generation diffusion model. Our approach ensures accurate rendering and correct orientation of the text within the image context. We demonstrate the effectiveness of the OrienText method on a self-curated dataset of images and compare it against the existing textual image generation methods.
Sketch & Paint: Stroke-by-Stroke Evolution of Visual Artworks
Feb 27, 2025
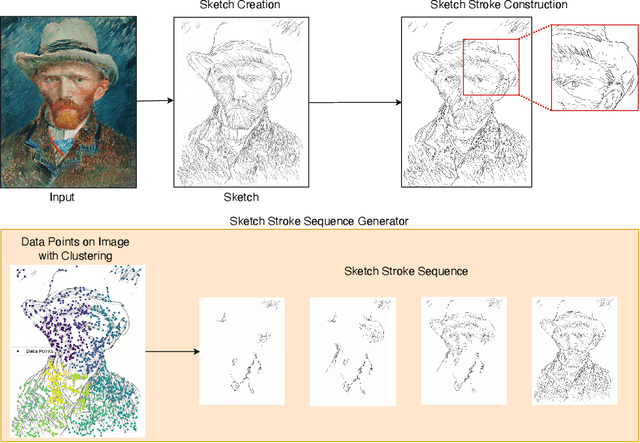

Understanding the stroke-based evolution of visual artworks is useful for advancing artwork learning, appreciation, and interactive display. While the stroke sequence of renowned artworks remains largely unknown, formulating this sequence for near-natural image drawing processes can significantly enhance our understanding of artistic techniques. This paper introduces a novel method for approximating artwork stroke evolution through a proximity-based clustering mechanism. We first convert pixel images into vector images via parametric curves and then explore the clustering approach to determine the sequence order of extracted strokes. Our proposed algorithm demonstrates the potential to infer stroke sequences in unknown artworks. We evaluate the performance of our method using WikiArt data and qualitatively demonstrate the plausible stroke sequences. Additionally, we demonstrate the robustness of our approach to handle a wide variety of input image types such as line art, face sketches, paintings, and photographic images. By exploring stroke extraction and sequence construction, we aim to improve our understanding of the intricacies of the art development techniques and the step-by-step reconstruction process behind visual artworks, thereby enriching our understanding of the creative journey from the initial sketch to the final artwork.
Style Based Clustering of Visual Artworks
Sep 12, 2024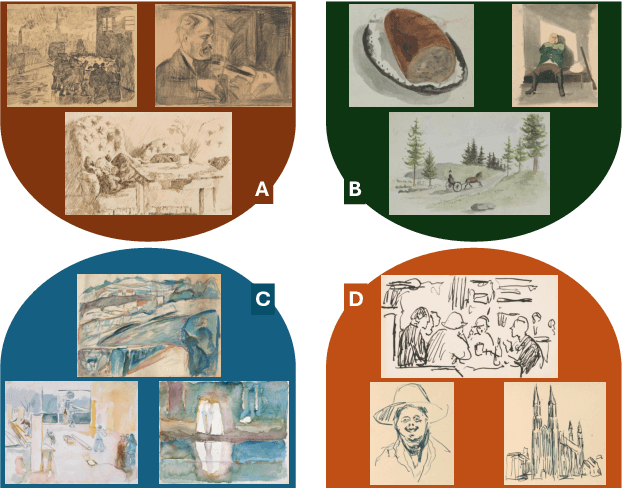
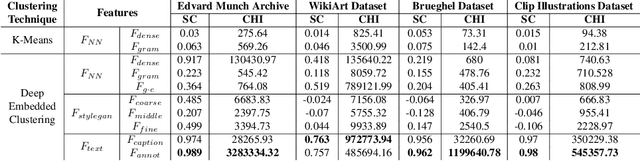
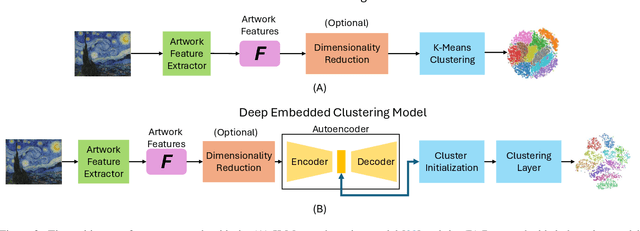
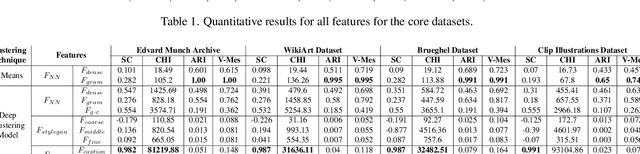
Clustering artworks based on style has many potential real-world applications like art recommendations, style-based search and retrieval, and the study of artistic style evolution in an artwork corpus. However, clustering artworks based on style is largely an unaddressed problem. A few present methods for clustering artworks principally rely on generic image feature representations derived from deep neural networks and do not specifically deal with the artistic style. In this paper, we introduce and deliberate over the notion of style-based clustering of visual artworks. Our main objective is to explore neural feature representations and architectures that can be used for style-based clustering and observe their impact and effectiveness. We develop different methods and assess their relative efficacy for style-based clustering through qualitative and quantitative analysis by applying them to four artwork corpora and four curated synthetically styled datasets. Our analysis provides some key novel insights on architectures, feature representations, and evaluation methods suitable for style-based clustering.
Multi-Subject Personalization
May 21, 2024Creative story illustration requires a consistent interplay of multiple characters or objects. However, conventional text-to-image models face significant challenges while producing images featuring multiple personalized subjects. For example, they distort the subject rendering, or the text descriptions fail to render coherent subject interactions. We present Multi-Subject Personalization (MSP) to alleviate some of these challenges. We implement MSP using Stable Diffusion and assess our approach against other text-to-image models, showcasing its consistent generation of good-quality images representing intended subjects and interactions.
CustomText: Customized Textual Image Generation using Diffusion Models
May 21, 2024Textual image generation spans diverse fields like advertising, education, product packaging, social media, information visualization, and branding. Despite recent strides in language-guided image synthesis using diffusion models, current models excel in image generation but struggle with accurate text rendering and offer limited control over font attributes. In this paper, we aim to enhance the synthesis of high-quality images with precise text customization, thereby contributing to the advancement of image generation models. We call our proposed method CustomText. Our implementation leverages a pre-trained TextDiffuser model to enable control over font color, background, and types. Additionally, to address the challenge of accurately rendering small-sized fonts, we train the ControlNet model for a consistency decoder, significantly enhancing text-generation performance. We assess the performance of CustomText in comparison to previous methods of textual image generation on the publicly available CTW-1500 dataset and a self-curated dataset for small-text generation, showcasing superior results.
Composite Diffusion | whole >= Σparts
Jul 25, 2023For an artist or a graphic designer, the spatial layout of a scene is a critical design choice. However, existing text-to-image diffusion models provide limited support for incorporating spatial information. This paper introduces Composite Diffusion as a means for artists to generate high-quality images by composing from the sub-scenes. The artists can specify the arrangement of these sub-scenes through a flexible free-form segment layout. They can describe the content of each sub-scene primarily using natural text and additionally by utilizing reference images or control inputs such as line art, scribbles, human pose, canny edges, and more. We provide a comprehensive and modular method for Composite Diffusion that enables alternative ways of generating, composing, and harmonizing sub-scenes. Further, we wish to evaluate the composite image for effectiveness in both image quality and achieving the artist's intent. We argue that existing image quality metrics lack a holistic evaluation of image composites. To address this, we propose novel quality criteria especially relevant to composite generation. We believe that our approach provides an intuitive method of art creation. Through extensive user surveys, quantitative and qualitative analysis, we show how it achieves greater spatial, semantic, and creative control over image generation. In addition, our methods do not need to retrain or modify the architecture of the base diffusion models and can work in a plug-and-play manner with the fine-tuned models.