 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfake Detection of Singing Voices With Whisper Encodings
Jan 31, 2025



The deepfake generation of singing vocals is a concerning issue for artists in the music industry. In this work, we propose a singing voice deepfake detection (SVDD) system, which uses noise-variant encodings of open-AI's Whisper model. As counter-intuitive as it may sound, even though the Whisper model is known to be noise-robust, the encodings are rich in non-speech information, and are noise-variant. This leads us to evaluate Whisper encodings as feature representations for the SVDD task. Therefore, in this work, the SVDD task is performed on vocals and mixtures, and the performance is evaluated in \%EER over varying Whisper model sizes and two classifiers- CNN and ResNet34, under different testing conditions.
Guided Diffusion-based Counterfactual Augmentation for Robust Session-based Recommendation
Oct 29, 2024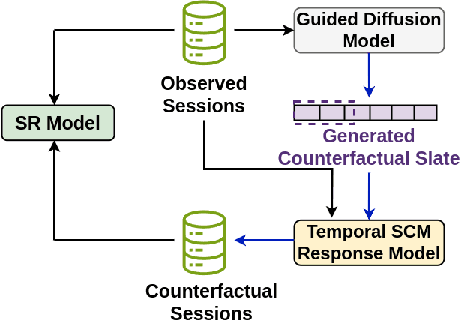
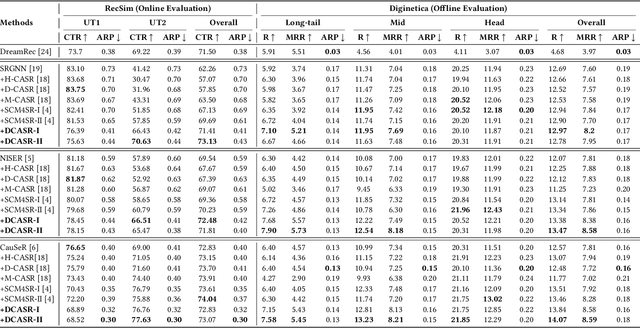
Session-based recommendation (SR) models aim to recommend top-K items to a user, based on the user's behaviour during the current session. Several SR models are proposed in the literature, however,concerns have been raised about their susceptibility to inherent biases in the training data (observed data) such as popularity bias. SR models when trained on the biased training data may encounter performance challenges on out-of-distribution data in real-world scenarios. One way to mitigate popularity bias is counterfactual data augmentation. Compared to prior works that rely on generating data using SR models, we focus on utilizing the capabilities of state-of-the art diffusion models for generating counterfactual data. We propose a guided diffusion-based counterfactual augmentation framework for SR. Through a combination of offline and online experiments on a real-world and simulated dataset, respectively, we show that our approach performs significantly better than the baseline SR models and other state-of-the art augmentation frameworks. More importantly, our framework shows significant improvement on less popular target items, by achieving up to 20% gain in Recall and 13% gain in CTR on real-world and simulated datasets,respectively.
LETS-GZSL: A Latent Embedding Model for Time Series Generalized Zero Shot Learning
Jul 25, 2022
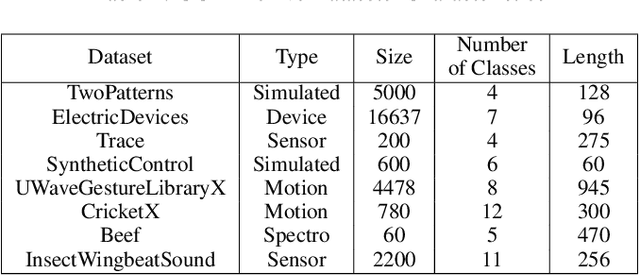
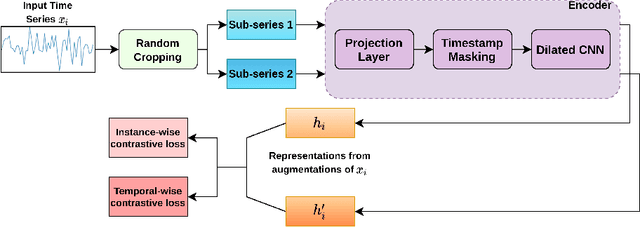
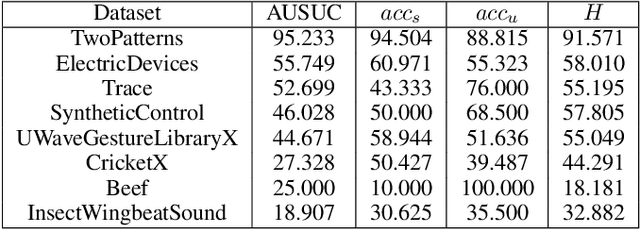
One of the recent developments in deep learning is generalized zero-shot learning (GZSL), which aims to recognize objects from both seen and unseen classes, when only the labeled examples from seen classes are provided. Over the past couple of years, GZSL has picked up traction and several models have been proposed to solve this problem. Whereas an extensive amount of research on GZSL has been carried out in fields such as computer vision and natural language processing, no such research has been carried out to deal with time series data. GZSL is used for applications such as detecting abnormalities from ECG and EEG data and identifying unseen classes from sensor, spectrograph and other devices' data. In this regard, we propose a Latent Embedding for Time Series - GZSL (LETS-GZSL) model that can solve the problem of GZSL for time series classification (TSC). We utilize an embedding-based approach and combine it with attribute vectors to predict the final class labels. We report our results on the widely popular UCR archive datasets. Our framework is able to achieve a harmonic mean value of at least 55% on most of the datasets except when the number of unseen classes is greater than 3 or the amount of data is very low (less than 100 training examples).
Similarity Learning based Few Shot Learning for ECG Time Series Classification
Jan 31, 2022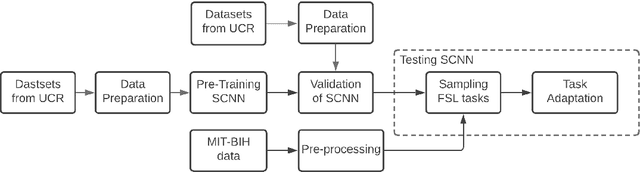
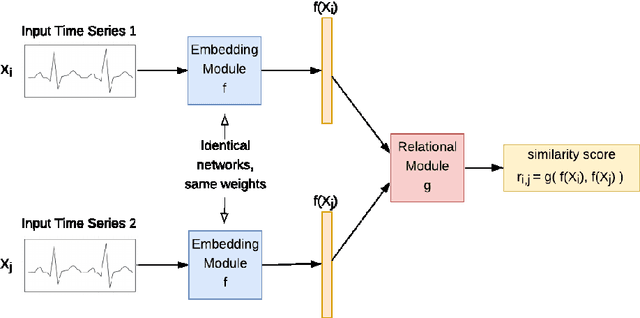


Using deep learning models to classify time series data generated from the Internet of Things (IoT) devices requires a large amount of labeled data. However, due to constrained resources available in IoT devices, it is often difficult to accommodate training using large data sets. This paper proposes and demonstrates a Similarity Learning-based Few Shot Learning for ECG arrhythmia classification using Siamese Convolutional Neural Networks. Few shot learning resolves the data scarcity issue by identifying novel classes from very few labeled examples. Few Shot Learning relies first on pretraining the model on a related relatively large database, and then the learning is used for further adaptation towards few examples available per class. Our experiments evaluate the performance accuracy with respect to K (number of instances per class) for ECG time series data classification. The accuracy with 5- shot learning is 92.25% which marginally improves with further increase in K. We also compare the performance of our method against other well-established similarity learning techniques such as Dynamic Time Warping (DTW), Euclidean Distance (ED), and a deep learning model - Long Short Term Memory Fully Convolutional Network (LSTM-FCN) with the same amount of data and conclude that our method outperforms them for a limited dataset size. For K=5, the accuracies obtained are 57%, 54%, 33%, and 92% approximately for ED, DTW, LSTM-FCN, and SCNN, respectively.
Batch-Constrained Distributional Reinforcement Learning for Session-based Recommendation
Dec 16, 2020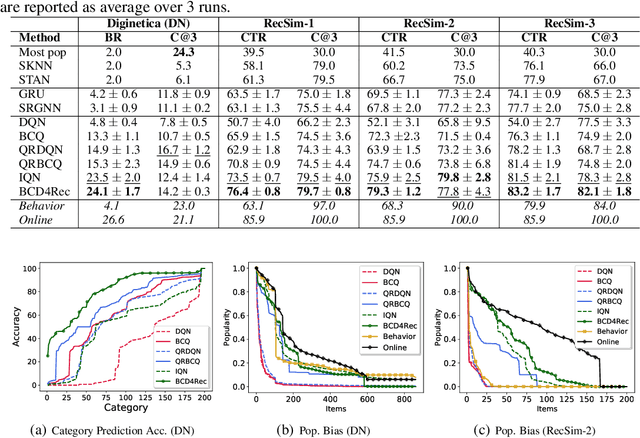
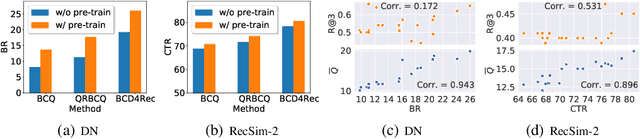

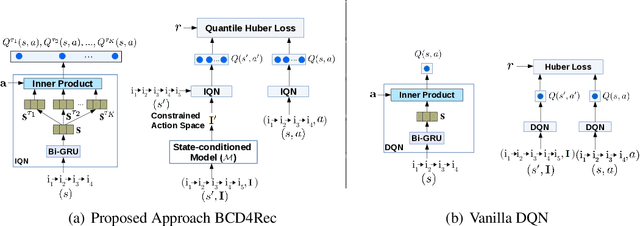
Most of the existing deep reinforcement learning (RL) approaches for session-based recommendations either rely on costly online interactions with real users, or rely on potentially biased rule-based or data-driven user-behavior models for learning. In this work, we instead focus on learning recommendation policies in the pure batch or offline setting, i.e. learning policies solely from offline historical interaction logs or batch data generated from an unknown and sub-optimal behavior policy, without further access to data from the real-world or user-behavior models. We propose BCD4Rec: Batch-Constrained Distributional RL for Session-based Recommendations. BCD4Rec builds upon the recent advances in batch (offline) RL and distributional RL to learn from offline logs while dealing with the intrinsically stochastic nature of rewards from the users due to varied latent interest preferences (environments). We demonstrate that BCD4Rec significantly improves upon the behavior policy as well as strong RL and non-RL baselines in the batch setting in terms of standard performance metrics like Click Through Rates or Buy Rates. Other useful properties of BCD4Rec include: i. recommending items from the correct latent categories indicating better value estimates despite large action space (of the order of number of items), and ii. overcoming popularity bias in clicked or bought items typically present in the offline logs.
NISER: Normalized Item and Session Representations with Graph Neural Networks
Sep 13, 2019
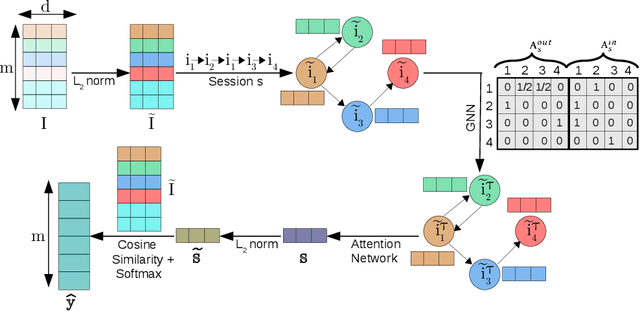

The goal of session-based recommendation (SR) models is to utilize the information from past actions (e.g. item/product clicks) in a session to recommend items that a user is likely to click next. Recently it has been shown that the sequence of item interactions in a session can be modeled as graph-structured data to better account for complex item transitions. Graph neural networks (GNNs) can learn useful representations for such session-graphs, and have been shown to improve over sequential models such as recurrent neural networks [14]. However, we note that these GNN-based recommendation models suffer from popularity bias: the models are biased towards recommending popular items, and fail to recommend relevant long-tail items (less popular or less frequent items). Therefore, these models perform poorly for the less popular new items arriving daily in a practical online setting. We demonstrate that this issue is, in part, related to the magnitude or norm of the learned item and session-graph representations (embedding vectors). We propose a training procedure that mitigates this issue by using normalized representations. The models using normalized item and session-graph representations perform significantly better: i. for the less popular long-tail items in the offline setting, and ii. for the less popular newly introduced items in the online setting. Furthermore, our approach significantly improves upon existing state-of-the-art on three benchmark datasets.
Transfer Learning for Clinical Time Series Analysis using Deep Neural Networks
Apr 01, 2019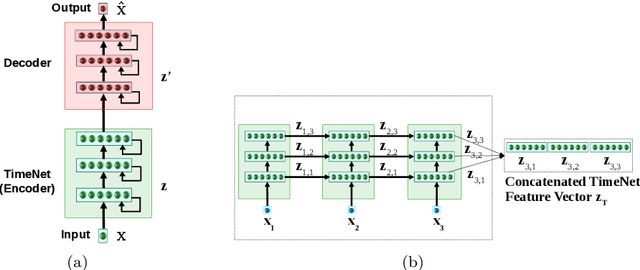
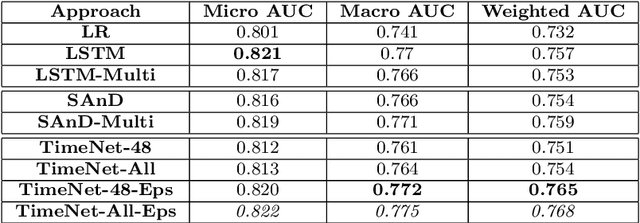
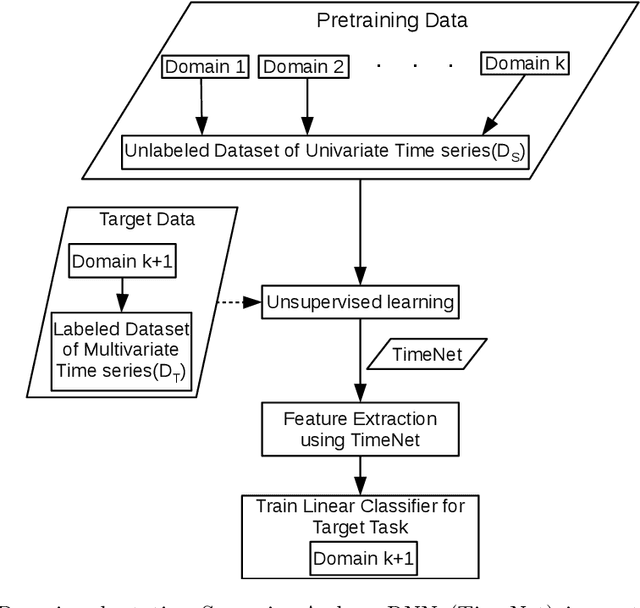

Deep neural networks have shown promising results for various clinical prediction tasks. However, training deep networks such as those based on Recurrent Neural Networks (RNNs) requires large labeled data, significant hyper-parameter tuning effort and expertise, and high computational resources. In this work, we investigate as to what extent can transfer learning address these issues when using deep RNNs to model multivariate clinical time series. We consider two scenarios for transfer learning using RNNs: i) domain-adaptation, i.e., leveraging a deep RNN - namely, TimeNet - pre-trained for feature extraction on time series from diverse domains, and adapting it for feature extraction and subsequent target tasks in healthcare domain, ii) task-adaptation, i.e., pre-training a deep RNN - namely, HealthNet - on diverse tasks in healthcare domain, and adapting it to new target tasks in the same domain. We evaluate the above approaches on publicly available MIMIC-III benchmark dataset, and demonstrate that (a) computationally-efficient linear models trained using features extracted via pre-trained RNNs outperform or, in the worst case, perform as well as deep RNNs and statistical hand-crafted features based models trained specifically for target task; (b) models obtained by adapting pre-trained models for target tasks are significantly more robust to the size of labeled data compared to task-specific RNNs, while also being computationally efficient. We, therefore, conclude that pre-trained deep models like TimeNet and HealthNet allow leveraging the advantages of deep learning for clinical time series analysis tasks, while also minimize dependence on hand-crafted features, deal robustly with scarce labeled training data scenarios without overfitting, as well as reduce dependence on expertise and resources required to train deep networks from scratch.
Transfer Learning for Clinical Time Series Analysis using Recurrent Neural Networks
Jul 04, 2018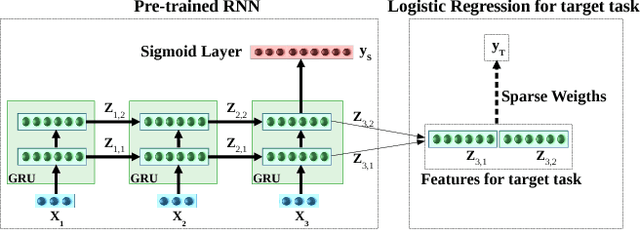

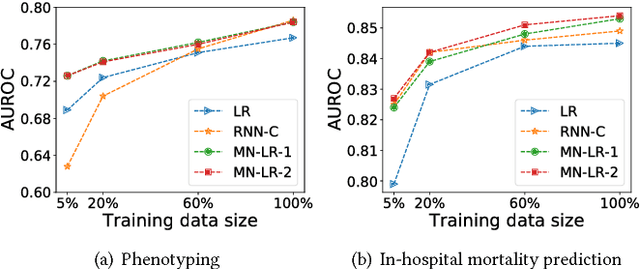

Deep neural networks have shown promising results for various clinical prediction tasks such as diagnosis, mortality prediction, predicting duration of stay in hospital, etc. However, training deep networks -- such as those based on Recurrent Neural Networks (RNNs) -- requires large labeled data, high computational resources, and significant hyperparameter tuning effort. In this work, we investigate as to what extent can transfer learning address these issues when using deep RNNs to model multivariate clinical time series. We consider transferring the knowledge captured in an RNN trained on several source tasks simultaneously using a large labeled dataset to build the model for a target task with limited labeled data. An RNN pre-trained on several tasks provides generic features, which are then used to build simpler linear models for new target tasks without training task-specific RNNs. For evaluation, we train a deep RNN to identify several patient phenotypes on time series from MIMIC-III database, and then use the features extracted using that RNN to build classifiers for identifying previously unseen phenotypes, and also for a seemingly unrelated task of in-hospital mortality. We demonstrate that (i) models trained on features extracted using pre-trained RNN outperform or, in the worst case, perform as well as task-specific RNNs; (ii) the models using features from pre-trained models are more robust to the size of labeled data than task-specific RNNs; and (iii) features extracted using pre-trained RNN are generic enough and perform better than typical statistical hand-crafted features.
Implementation of Rule Based Algorithm for Sandhi-Vicheda Of Compound Hindi Words
Sep 12, 2009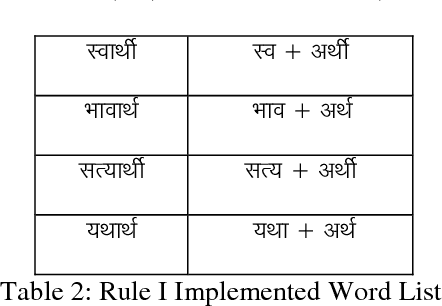
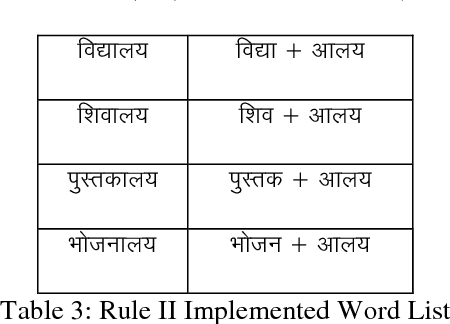
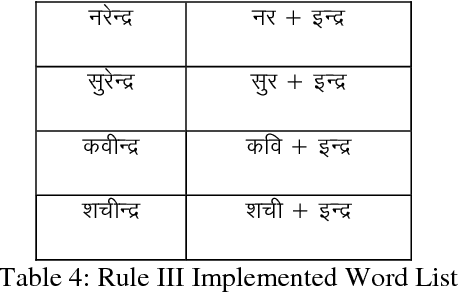
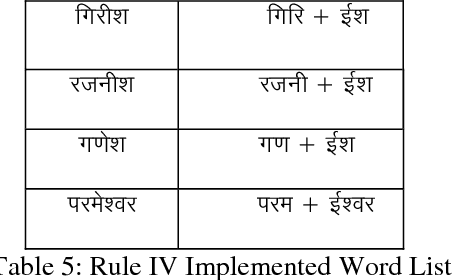
Sandhi means to join two or more words to coin new word. Sandhi literally means `putting together' or combining (of sounds), It denotes all combinatory sound-changes effected (spontaneously) for ease of pronunciation. Sandhi-vicheda describes [5] the process by which one letter (whether single or cojoined) is broken to form two words. Part of the broken letter remains as the last letter of the first word and part of the letter forms the first letter of the next letter. Sandhi- Vicheda is an easy and interesting way that can give entirely new dimension that add new way to traditional approach to Hindi Teaching. In this paper using the Rule based algorithm we have reported an accuracy of 60-80% depending upon the number of rules to be implemented.
* International Journal of Computer Science Issues (IJCSI), Volume 3, pp45-49, August 2009