 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning for Multivariate Time Series Tasks with Variable Input Dimensions
Mar 14, 2022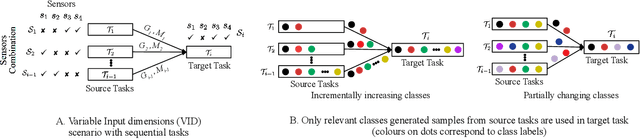
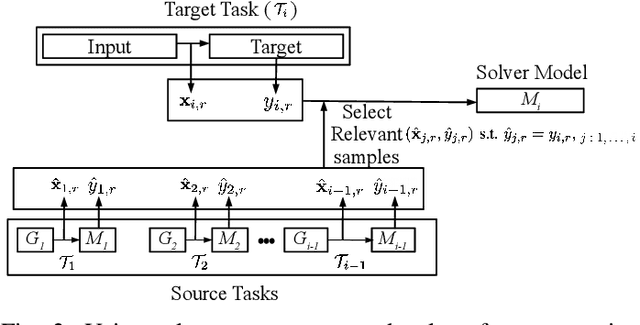
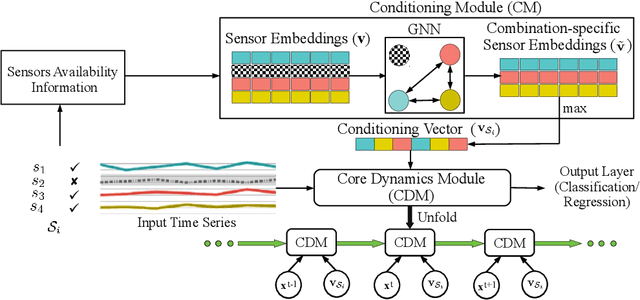
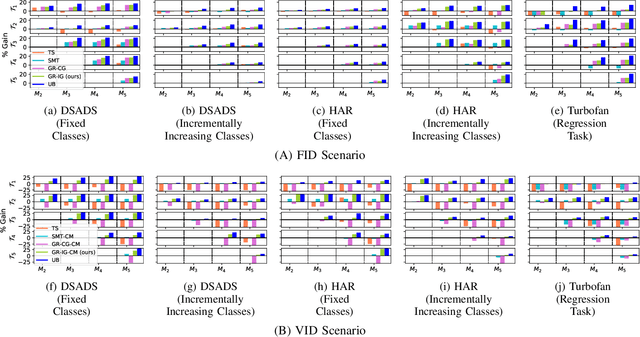
We consider a sequence of related multivariate time series learning tasks, such as predicting failures for different instances of a machine from time series of multi-sensor data, or activity recognition tasks over different individuals from multiple wearable sensors. We focus on two under-explored practical challenges arising in such settings: (i) Each task may have a different subset of sensors, i.e., providing different partial observations of the underlying 'system'. This restriction can be due to different manufacturers in the former case, and people wearing more or less measurement devices in the latter (ii) We are not allowed to store or re-access data from a task once it has been observed at the task level. This may be due to privacy considerations in the case of people, or legal restrictions placed by machine owners. Nevertheless, we would like to (a) improve performance on subsequent tasks using experience from completed tasks as well as (b) continue to perform better on past tasks, e.g., update the model and improve predictions on even the first machine after learning from subsequently observed ones. We note that existing continual learning methods do not take into account variability in input dimensions arising due to different subsets of sensors being available across tasks, and struggle to adapt to such variable input dimensions (VID) tasks. In this work, we address this shortcoming of existing methods. To this end, we learn task-specific generative models and classifiers, and use these to augment data for target tasks. Since the input dimensions across tasks vary, we propose a novel conditioning module based on graph neural networks to aid a standard recurrent neural network. We evaluate the efficacy of the proposed approach on three publicly available datasets corresponding to two activity recognition tasks (classification) and one prognostics task (regression).
Electricity Consumption Forecasting for Out-of-distribution Time-of-Use Tariffs
Feb 11, 2022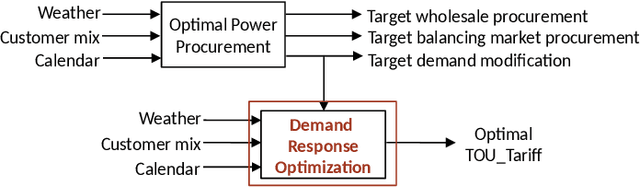

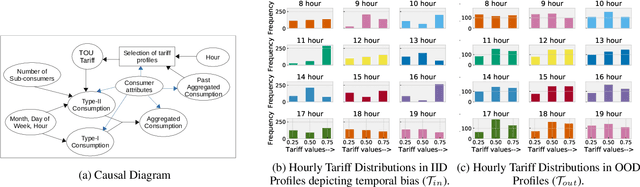

In electricity markets, retailers or brokers want to maximize profits by allocating tariff profiles to end consumers. One of the objectives of such demand response management is to incentivize the consumers to adjust their consumption so that the overall electricity procurement in the wholesale markets is minimized, e.g. it is desirable that consumers consume less during peak hours when cost of procurement for brokers from wholesale markets are high. We consider a greedy solution to maximize the overall profit for brokers by optimal tariff profile allocation. This in-turn requires forecasting electricity consumption for each user for all tariff profiles. This forecasting problem is challenging compared to standard forecasting problems due to following reasons: i. the number of possible combinations of hourly tariffs is high and retailers may not have considered all combinations in the past resulting in a biased set of tariff profiles tried in the past, ii. the profiles allocated in the past to each user is typically based on certain policy. These reasons violate the standard i.i.d. assumptions, as there is a need to evaluate new tariff profiles on existing customers and historical data is biased by the policies used in the past for tariff allocation. In this work, we consider several scenarios for forecasting and optimization under these conditions. We leverage the underlying structure of how consumers respond to variable tariff rates by comparing tariffs across hours and shifting loads, and propose suitable inductive biases in the design of deep neural network based architectures for forecasting under such scenarios. More specifically, we leverage attention mechanisms and permutation equivariant networks that allow desirable processing of tariff profiles to learn tariff representations that are insensitive to the biases in the data and still representative of the task.
Handling Variable-Dimensional Time Series with Graph Neural Networks
Jul 07, 2020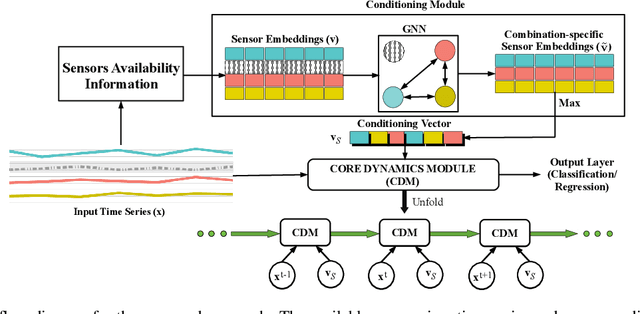
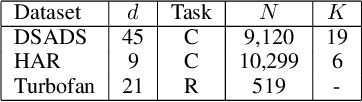
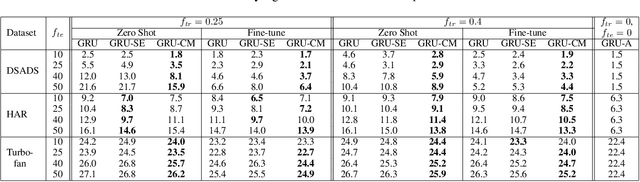
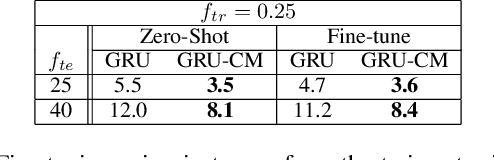
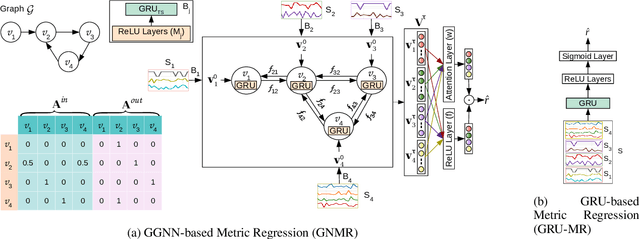
Several applications of Internet of Things (IoT) technology involve capturing data from multiple sensors resulting in multi-sensor time series. Existing neural networks based approaches for such multi-sensor or multivariate time series modeling assume fixed input dimension or number of sensors. Such approaches can struggle in the practical setting where different instances of the same device or equipment such as mobiles, wearables, engines, etc. come with different combinations of installed sensors. We consider training neural network models from such multi-sensor time series, where the time series have varying input dimensionality owing to availability or installation of a different subset of sensors at each source of time series. We propose a novel neural network architecture suitable for zero-shot transfer learning allowing robust inference for multivariate time series with previously unseen combination of available dimensions or sensors at test time. Such a combinatorial generalization is achieved by conditioning the layers of a core neural network-based time series model with a "conditioning vector" that carries information of the available combination of sensors for each time series. This conditioning vector is obtained by summarizing the set of learned "sensor embedding vectors" corresponding to the available sensors in a time series via a graph neural network. We evaluate the proposed approach on publicly available activity recognition and equipment prognostics datasets, and show that the proposed approach allows for better generalization in comparison to a deep gated recurrent neural network baseline.
Graph Neural Networks for Leveraging Industrial Equipment Structure: An application to Remaining Useful Life Estimation
Jun 30, 2020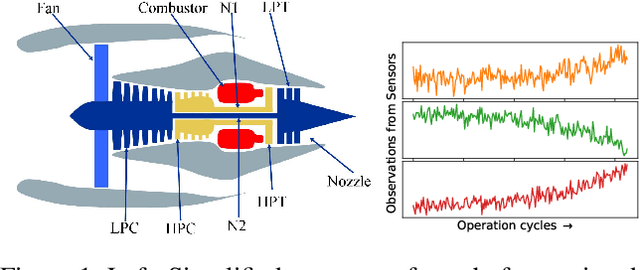
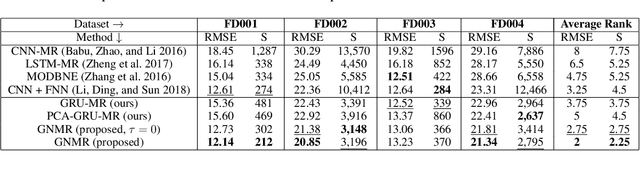

Automated equipment health monitoring from streaming multisensor time-series data can be used to enable condition-based maintenance, avoid sudden catastrophic failures, and ensure high operational availability. We note that most complex machinery has a well-documented and readily accessible underlying structure capturing the inter-dependencies between sub-systems or modules. Deep learning models such as those based on recurrent neural networks (RNNs) or convolutional neural networks (CNNs) fail to explicitly leverage this potentially rich source of domain-knowledge into the learning procedure. In this work, we propose to capture the structure of a complex equipment in the form of a graph, and use graph neural networks (GNNs) to model multi-sensor time-series data. Using remaining useful life estimation as an application task, we evaluate the advantage of incorporating the graph structure via GNNs on the publicly available turbofan engine benchmark dataset. We observe that the proposed GNN-based RUL estimation model compares favorably to several strong baselines from literature such as those based on RNNs and CNNs. Additionally, we observe that the learned network is able to focus on the module (node) with impending failure through a simple attention mechanism, potentially paving the way for actionable diagnosis.
Meta-Learning for Few-Shot Time Series Classification
Sep 25, 2019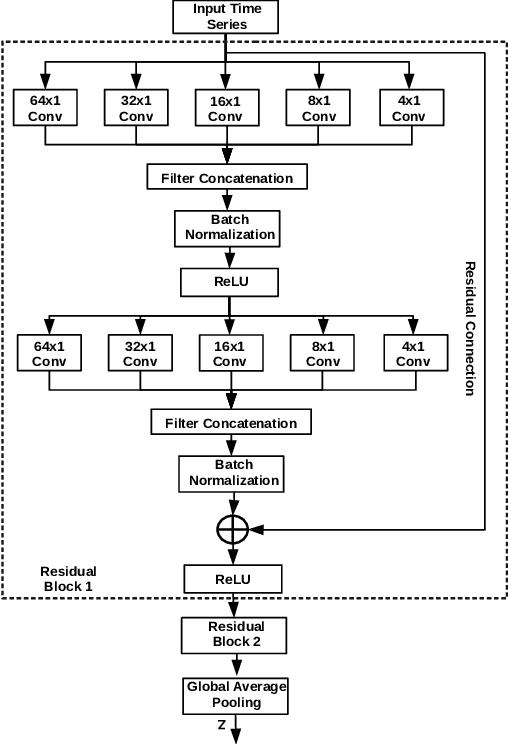
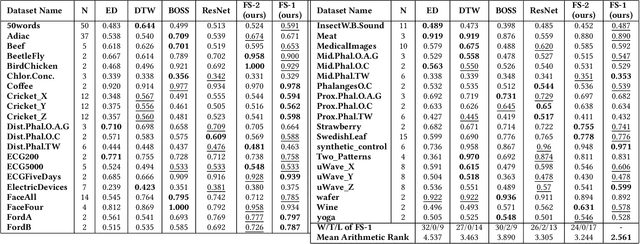
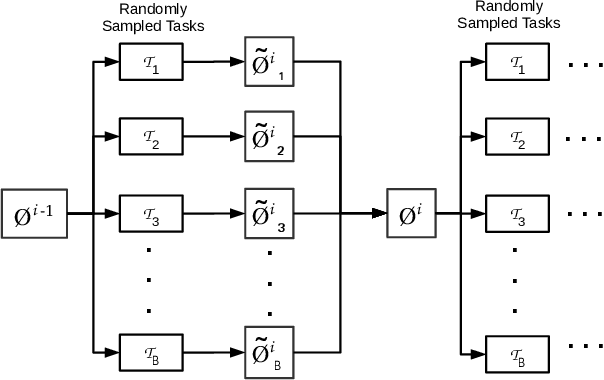
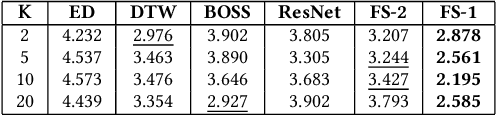
Deep neural networks (DNNs) have achieved state-of-the-art results on time series classification (TSC) tasks. In this work, we focus on leveraging DNNs in the often-encountered practical scenario where access to labeled training data is difficult, and where DNNs would be prone to overfitting. We leverage recent advancements in gradient-based meta-learning, and propose an approach to train a residual neural network with convolutional layers as a meta-learning agent for few-shot TSC. The network is trained on a diverse set of few-shot tasks sampled from various domains (e.g. healthcare, activity recognition, etc.) such that it can solve a target task from another domain using only a small number of training samples from the target task. Most existing meta-learning approaches are limited in practice as they assume a fixed number of target classes across tasks. We overcome this limitation in order to train a common agent across domains with each domain having different number of target classes, we utilize a triplet-loss based learning procedure that does not require any constraints to be enforced on the number of classes for the few-shot TSC tasks. To the best of our knowledge, we are the first to use meta-learning based pre-training for TSC. Our approach sets a new benchmark for few-shot TSC, outperforming several strong baselines on few-shot tasks sampled from 41 datasets in UCR TSC Archive. We observe that pre-training under the meta-learning paradigm allows the network to quickly adapt to new unseen tasks with small number of labeled instances.
Meta-Learning for Black-box Optimization
Jul 16, 2019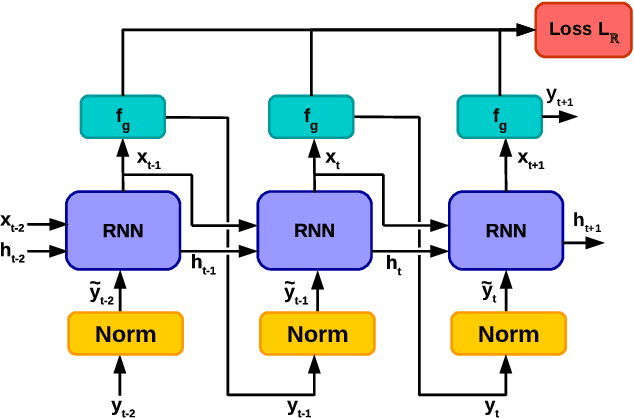
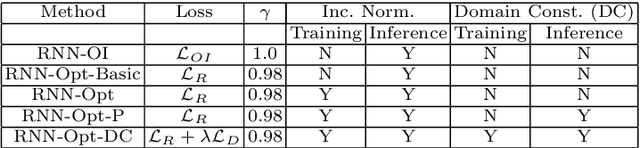

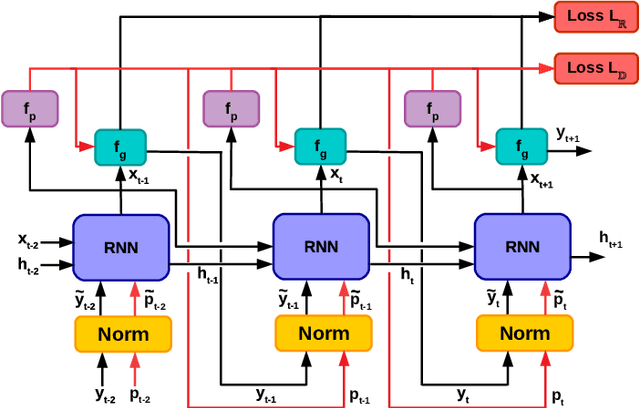
Recently, neural networks trained as optimizers under the "learning to learn" or meta-learning framework have been shown to be effective for a broad range of optimization tasks including derivative-free black-box function optimization. Recurrent neural networks (RNNs) trained to optimize a diverse set of synthetic non-convex differentiable functions via gradient descent have been effective at optimizing derivative-free black-box functions. In this work, we propose RNN-Opt: an approach for learning RNN-based optimizers for optimizing real-parameter single-objective continuous functions under limited budget constraints. Existing approaches utilize an observed improvement based meta-learning loss function for training such models. We propose training RNN-Opt by using synthetic non-convex functions with known (approximate) optimal values by directly using discounted regret as our meta-learning loss function. We hypothesize that a regret-based loss function mimics typical testing scenarios, and would therefore lead to better optimizers compared to optimizers trained only to propose queries that improve over previous queries. Further, RNN-Opt incorporates simple yet effective enhancements during training and inference procedures to deal with the following practical challenges: i) Unknown range of possible values for the black-box function to be optimized, and ii) Practical and domain-knowledge based constraints on the input parameters. We demonstrate the efficacy of RNN-Opt in comparison to existing methods on several synthetic as well as standard benchmark black-box functions along with an anonymized industrial constrained optimization problem.
ConvTimeNet: A Pre-trained Deep Convolutional Neural Network for Time Series Classification
May 02, 2019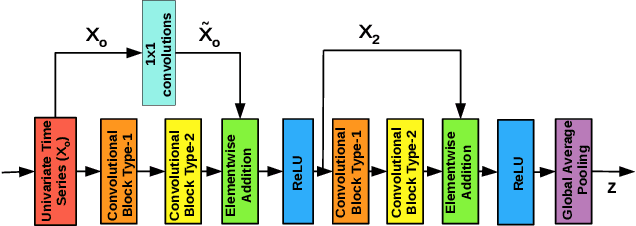
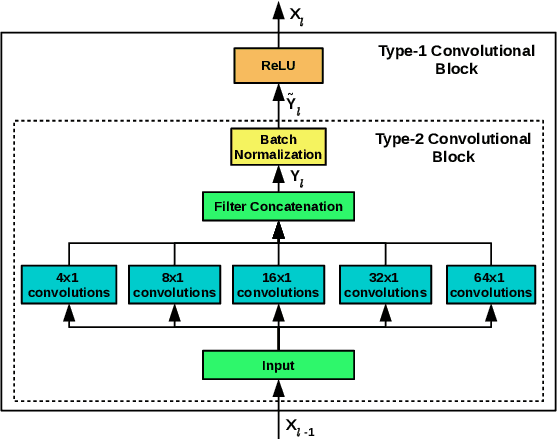
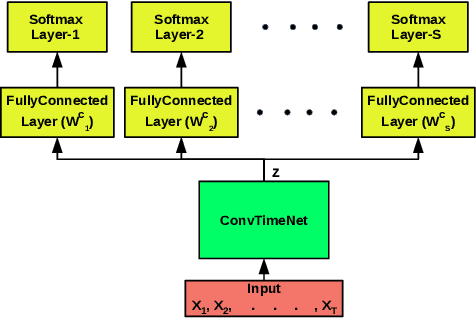
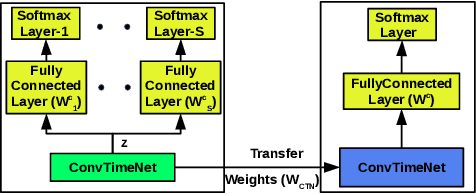
Training deep neural networks often requires careful hyper-parameter tuning and significant computational resources. In this paper, we propose ConvTimeNet (CTN): an off-the-shelf deep convolutional neural network (CNN) trained on diverse univariate time series classification (TSC) source tasks. Once trained, CTN can be easily adapted to new TSC target tasks via a small amount of fine-tuning using labeled instances from the target tasks. We note that the length of convolutional filters is a key aspect when building a pre-trained model that can generalize to time series of different lengths across datasets. To achieve this, we incorporate filters of multiple lengths in all convolutional layers of CTN to capture temporal features at multiple time scales. We consider all 65 datasets with time series of lengths up to 512 points from the UCR TSC Benchmark for training and testing transferability of CTN: We train CTN on a randomly chosen subset of 24 datasets using a multi-head approach with a different softmax layer for each training dataset, and study generalizability and transferability of the learned filters on the remaining 41 TSC datasets. We observe significant gains in classification accuracy as well as computational efficiency when using pre-trained CTN as a starting point for subsequent task-specific fine-tuning compared to existing state-of-the-art TSC approaches. We also provide qualitative insights into the working of CTN by: i) analyzing the activations and filters of first convolution layer suggesting the filters in CTN are generically useful, ii) analyzing the impact of the design decision to incorporate multiple length decisions, and iii) finding regions of time series that affect the final classification decision via occlusion sensitivity analysis.
Transfer Learning for Clinical Time Series Analysis using Deep Neural Networks
Apr 01, 2019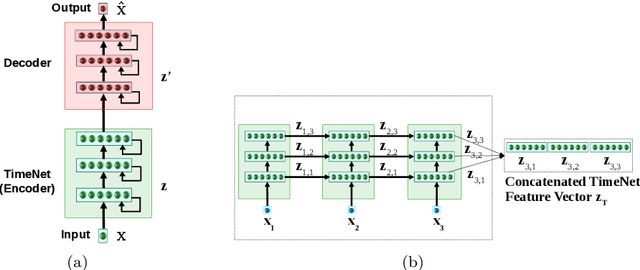
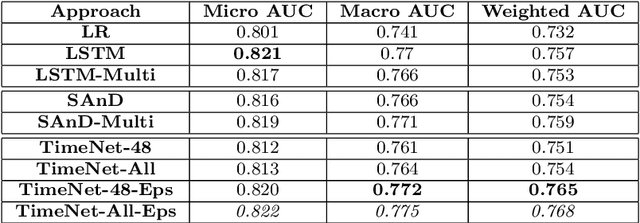
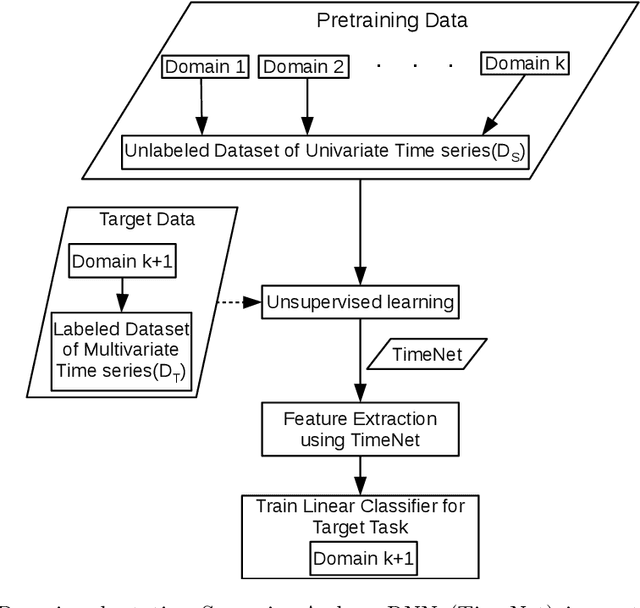

Deep neural networks have shown promising results for various clinical prediction tasks. However, training deep networks such as those based on Recurrent Neural Networks (RNNs) requires large labeled data, significant hyper-parameter tuning effort and expertise, and high computational resources. In this work, we investigate as to what extent can transfer learning address these issues when using deep RNNs to model multivariate clinical time series. We consider two scenarios for transfer learning using RNNs: i) domain-adaptation, i.e., leveraging a deep RNN - namely, TimeNet - pre-trained for feature extraction on time series from diverse domains, and adapting it for feature extraction and subsequent target tasks in healthcare domain, ii) task-adaptation, i.e., pre-training a deep RNN - namely, HealthNet - on diverse tasks in healthcare domain, and adapting it to new target tasks in the same domain. We evaluate the above approaches on publicly available MIMIC-III benchmark dataset, and demonstrate that (a) computationally-efficient linear models trained using features extracted via pre-trained RNNs outperform or, in the worst case, perform as well as deep RNNs and statistical hand-crafted features based models trained specifically for target task; (b) models obtained by adapting pre-trained models for target tasks are significantly more robust to the size of labeled data compared to task-specific RNNs, while also being computationally efficient. We, therefore, conclude that pre-trained deep models like TimeNet and HealthNet allow leveraging the advantages of deep learning for clinical time series analysis tasks, while also minimize dependence on hand-crafted features, deal robustly with scarce labeled training data scenarios without overfitting, as well as reduce dependence on expertise and resources required to train deep networks from scratch.