 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA microwave super-resolution imaging approach towards breast cancer margin mapping
Apr 23, 2026Accurate characterisation of margins in excised breast cancer tumours is critical to the success of surgical interventions, yet margin status is typically confirmed post-operatively using histopathology. Here we present a new approach to intraoperative margin assessment based on microwave single pixel imaging, demonstrating tissue phantom hydration mapping across large areas (~10 cm x 10 cm) at ~1 mm resolution. By leveraging the photo-induced change in microwave transparency of a silicon modulator placed under the sample, we map the microwave reflectivity and identify positive margins with deeply sub-wavelength resolution. We test the discriminatory capabilities of our approach using gelatine-based tumour phantoms with variations in water density representative of the margin and cancerous tissues of a resected tumour. We demonstrate the capability to identify, locate and quantify inadequate margins up to the typically targeted minimum thickness of 2 mm. Furthermore, using numerical modelling, we show that our approach is expected to be resilient to patient-specific tissue differences. Our technique has potential for future deployment as a real-time intraoperative tissue margin analysis tool.
Learning to Liquidate Forex: Optimal Stopping via Adaptive Top-K Regression
Feb 25, 2022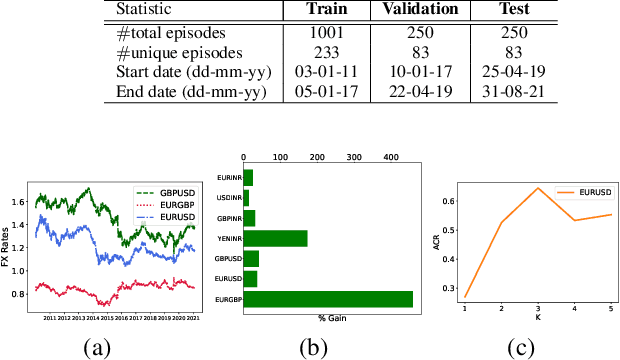
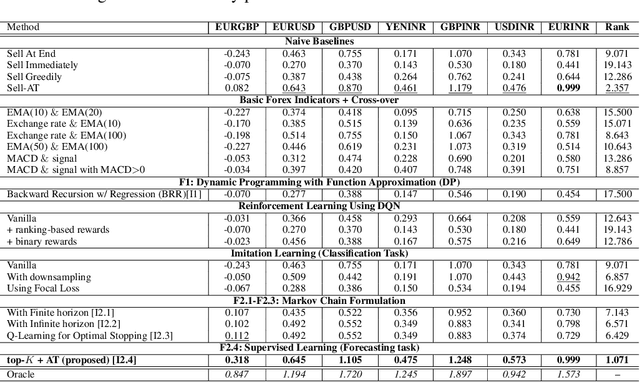
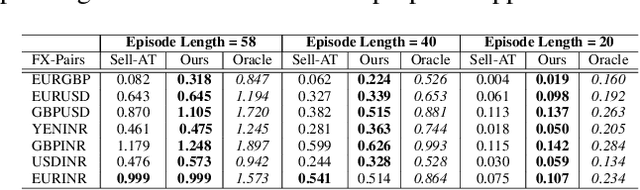
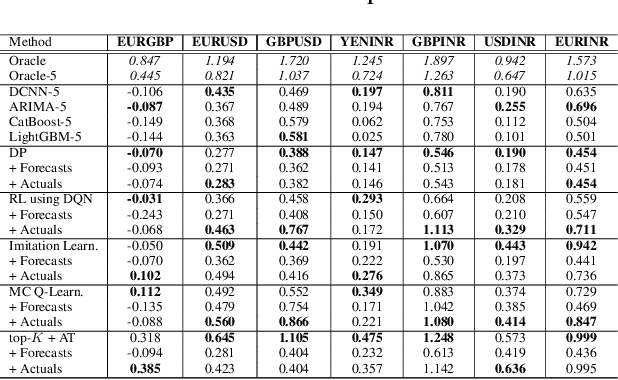
We consider learning a trading agent acting on behalf of the treasury of a firm earning revenue in a foreign currency (FC) and incurring expenses in the home currency (HC). The goal of the agent is to maximize the expected HC at the end of the trading episode by deciding to hold or sell the FC at each time step in the trading episode. We pose this as an optimization problem, and consider a broad spectrum of approaches with the learning component ranging from supervised to imitation to reinforcement learning. We observe that most of the approaches considered struggle to improve upon simple heuristic baselines. We identify two key aspects of the problem that render standard solutions ineffective - i) while good forecasts of future FX rates can be highly effective in guiding good decisions, forecasting FX rates is difficult, and erroneous estimates tend to degrade the performance of trading agents instead of improving it, ii) the inherent non-stationary nature of FX rates renders a fixed decision-threshold highly ineffective. To address these problems, we propose a novel supervised learning approach that learns to forecast the top-K future FX rates instead of forecasting all the future FX rates, and bases the hold-versus-sell decision on the forecasts (e.g. hold if future FX rate is higher than current FX rate, sell otherwise). Furthermore, to handle the non-stationarity in the FX rates data which poses challenges to the i.i.d. assumption in supervised learning methods, we propose to adaptively learn decision-thresholds based on recent historical episodes. Through extensive empirical evaluation, we show that our approach is the only approach which is able to consistently improve upon a simple heuristic baseline. Further experiments show the inefficacy of state-of-the-art statistical and deep-learning-based forecasting methods as they degrade the performance of the trading agent.
Batch-Constrained Distributional Reinforcement Learning for Session-based Recommendation
Dec 16, 2020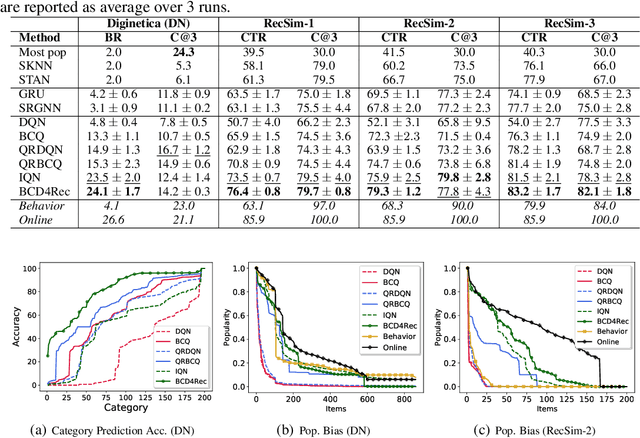
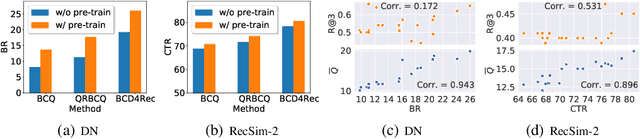

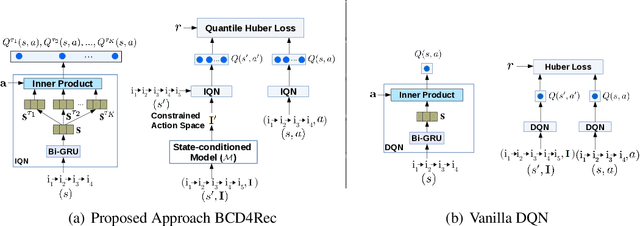
Most of the existing deep reinforcement learning (RL) approaches for session-based recommendations either rely on costly online interactions with real users, or rely on potentially biased rule-based or data-driven user-behavior models for learning. In this work, we instead focus on learning recommendation policies in the pure batch or offline setting, i.e. learning policies solely from offline historical interaction logs or batch data generated from an unknown and sub-optimal behavior policy, without further access to data from the real-world or user-behavior models. We propose BCD4Rec: Batch-Constrained Distributional RL for Session-based Recommendations. BCD4Rec builds upon the recent advances in batch (offline) RL and distributional RL to learn from offline logs while dealing with the intrinsically stochastic nature of rewards from the users due to varied latent interest preferences (environments). We demonstrate that BCD4Rec significantly improves upon the behavior policy as well as strong RL and non-RL baselines in the batch setting in terms of standard performance metrics like Click Through Rates or Buy Rates. Other useful properties of BCD4Rec include: i. recommending items from the correct latent categories indicating better value estimates despite large action space (of the order of number of items), and ii. overcoming popularity bias in clicked or bought items typically present in the offline logs.
NISER: Normalized Item and Session Representations with Graph Neural Networks
Sep 13, 2019
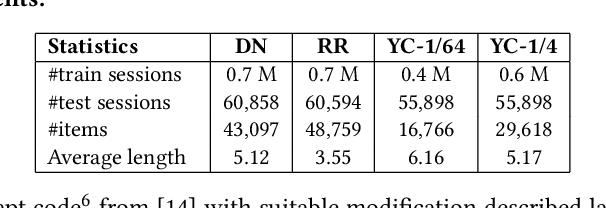
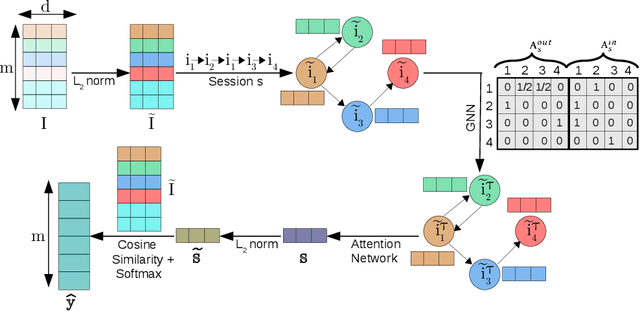

The goal of session-based recommendation (SR) models is to utilize the information from past actions (e.g. item/product clicks) in a session to recommend items that a user is likely to click next. Recently it has been shown that the sequence of item interactions in a session can be modeled as graph-structured data to better account for complex item transitions. Graph neural networks (GNNs) can learn useful representations for such session-graphs, and have been shown to improve over sequential models such as recurrent neural networks [14]. However, we note that these GNN-based recommendation models suffer from popularity bias: the models are biased towards recommending popular items, and fail to recommend relevant long-tail items (less popular or less frequent items). Therefore, these models perform poorly for the less popular new items arriving daily in a practical online setting. We demonstrate that this issue is, in part, related to the magnitude or norm of the learned item and session-graph representations (embedding vectors). We propose a training procedure that mitigates this issue by using normalized representations. The models using normalized item and session-graph representations perform significantly better: i. for the less popular long-tail items in the offline setting, and ii. for the less popular newly introduced items in the online setting. Furthermore, our approach significantly improves upon existing state-of-the-art on three benchmark datasets.