 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework for Contrastive Learning from a Perspective of Affinity Matrix
Nov 26, 2022In recent years, a variety of contrastive learning based unsupervised visual representation learning methods have been designed and achieved great success in many visual tasks. Generally, these methods can be roughly classified into four categories: (1) standard contrastive methods with an InfoNCE like loss, such as MoCo and SimCLR; (2) non-contrastive methods with only positive pairs, such as BYOL and SimSiam; (3) whitening regularization based methods, such as W-MSE and VICReg; and (4) consistency regularization based methods, such as CO2. In this study, we present a new unified contrastive learning representation framework (named UniCLR) suitable for all the above four kinds of methods from a novel perspective of basic affinity matrix. Moreover, three variants, i.e., SimAffinity, SimWhitening and SimTrace, are presented based on UniCLR. In addition, a simple symmetric loss, as a new consistency regularization term, is proposed based on this framework. By symmetrizing the affinity matrix, we can effectively accelerate the convergence of the training process. Extensive experiments have been conducted to show that (1) the proposed UniCLR framework can achieve superior results on par with and even be better than the state of the art, (2) the proposed symmetric loss can significantly accelerate the convergence of models, and (3) SimTrace can avoid the mode collapse problem by maximizing the trace of a whitened affinity matrix without relying on asymmetry designs or stop-gradients.
Playing Lottery Tickets in Style Transfer Models
Apr 10, 2022



Style transfer has achieved great success and attracted a wide range of attention from both academic and industrial communities due to its flexible application scenarios. However, the dependence on a pretty large VGG-based autoencoder leads to existing style transfer models having high parameter complexities, which limits their applications on resource-constrained devices. Compared with many other tasks, the compression of style transfer models has been less explored. Recently, the lottery ticket hypothesis (LTH) has shown great potential in finding extremely sparse matching subnetworks which can achieve on par or even better performance than the original full networks when trained in isolation. In this work, we for the first time perform an empirical study to verify whether such trainable matching subnetworks also exist in style transfer models. Specifically, we take two most popular style transfer models, i.e., AdaIN and SANet, as the main testbeds, which represent global and local transformation based style transfer methods respectively. We carry out extensive experiments and comprehensive analysis, and draw the following conclusions. (1) Compared with fixing the VGG encoder, style transfer models can benefit more from training the whole network together. (2) Using iterative magnitude pruning, we find the matching subnetworks at 89.2% sparsity in AdaIN and 73.7% sparsity in SANet, which demonstrates that style transfer models can play lottery tickets too. (3) The feature transformation module should also be pruned to obtain a much sparser model without affecting the existence and quality of the matching subnetworks. (4) Besides AdaIN and SANet, other models such as LST, MANet, AdaAttN and MCCNet can also play lottery tickets, which shows that LTH can be generalized to various style transfer models.
Triplet is All You Need with Random Mappings for Unsupervised Visual Representation Learning
Jul 22, 2021
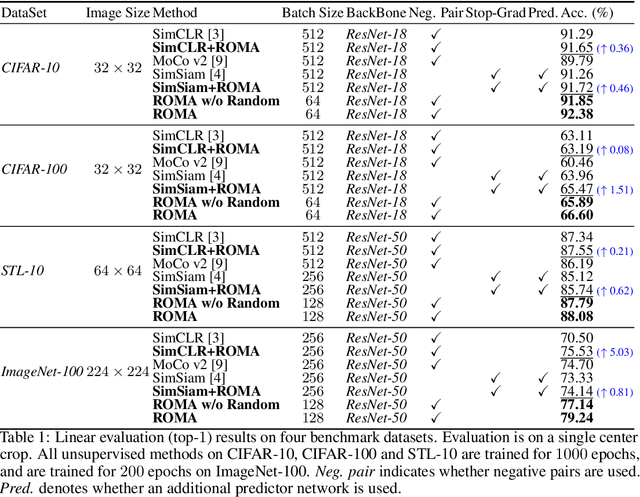
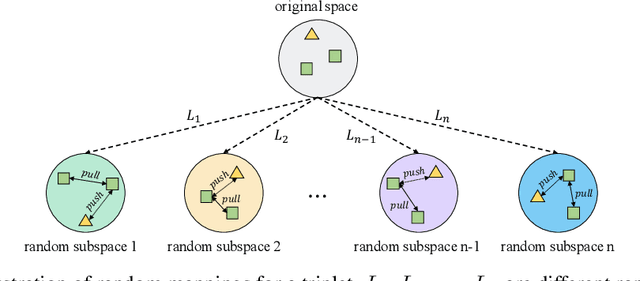

Contrastive self-supervised learning (SSL) has achieved great success in unsupervised visual representation learning by maximizing the similarity between two augmented views of the same image (positive pairs) and simultaneously contrasting other different images (negative pairs). However, this type of methods, such as SimCLR and MoCo, relies heavily on a large number of negative pairs and thus requires either large batches or memory banks. In contrast, some recent non-contrastive SSL methods, such as BYOL and SimSiam, attempt to discard negative pairs by introducing asymmetry and show remarkable performance. Unfortunately, to avoid collapsed solutions caused by not using negative pairs, these methods require sophisticated asymmetry designs. In this paper, we argue that negative pairs are still necessary but one is sufficient, i.e., triplet is all you need. A simple triplet-based loss can achieve surprisingly good performance without requiring large batches or asymmetry. Moreover, we observe that unsupervised visual representation learning can gain significantly from randomness. Based on this observation, we propose a simple plug-in RandOm MApping (ROMA) strategy by randomly mapping samples into other spaces and enforcing these randomly projected samples to satisfy the same correlation requirement. The proposed ROMA strategy not only achieves the state-of-the-art performance in conjunction with the triplet-based loss, but also can further effectively boost other SSL methods.