 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeKo: Toward Post Recognition Generative Correction Large Language Models with Task-Oriented Experts
Paper and Code
Nov 08, 2024
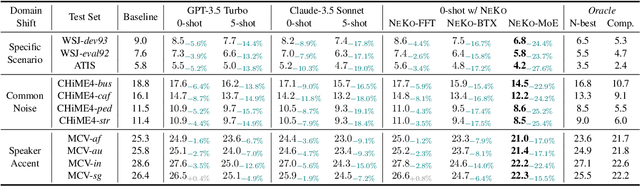
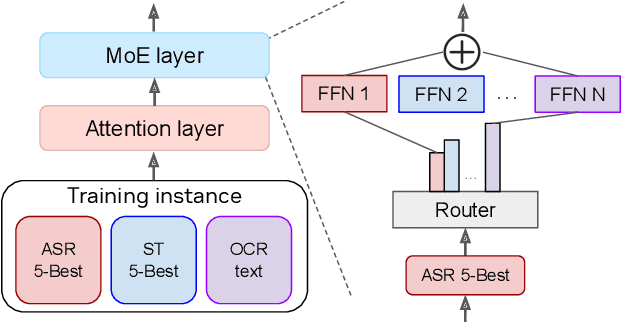
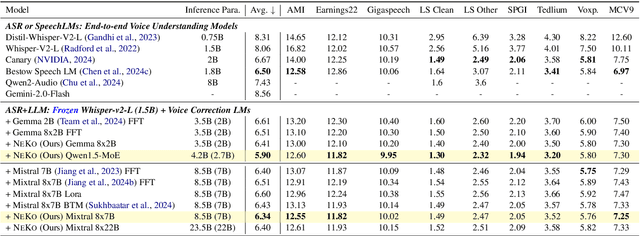
Construction of a general-purpose post-recognition error corrector poses a crucial question: how can we most effectively train a model on a large mixture of domain datasets? The answer would lie in learning dataset-specific features and digesting their knowledge in a single model. Previous methods achieve this by having separate correction language models, resulting in a significant increase in parameters. In this work, we present Mixture-of-Experts as a solution, highlighting that MoEs are much more than a scalability tool. We propose a Multi-Task Correction MoE, where we train the experts to become an ``expert'' of speech-to-text, language-to-text and vision-to-text datasets by learning to route each dataset's tokens to its mapped expert. Experiments on the Open ASR Leaderboard show that we explore a new state-of-the-art performance by achieving an average relative $5.0$% WER reduction and substantial improvements in BLEU scores for speech and translation tasks. On zero-shot evaluation, NeKo outperforms GPT-3.5 and Claude-Opus with $15.5$% to $27.6$% relative WER reduction in the Hyporadise benchmark. NeKo performs competitively on grammar and post-OCR correction as a multi-task model.